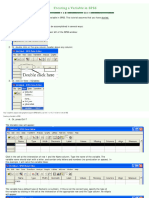
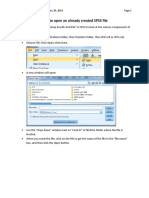
You might also like
- SPSS Statistics Course OverviewDocument27 pagesSPSS Statistics Course OverviewAdesanya Olatunbosun80% (5)
- Child Dental Examination FormDocument1 pageChild Dental Examination FormElok Faiqotul Umma100% (2)
- SPSS Basics ManualDocument25 pagesSPSS Basics ManualAlfredBakChoiNo ratings yet
- E Book OdontologyDocument347 pagesE Book OdontologyElok Faiqotul UmmaNo ratings yet
- SPSS Step-by-Step Tutorial: Part 1Document50 pagesSPSS Step-by-Step Tutorial: Part 1Ram Krishn PandeyNo ratings yet
- Note - SPSS For Customer Analysis 2018Document22 pagesNote - SPSS For Customer Analysis 2018Avinash KumarNo ratings yet
- SPSSDocument90 pagesSPSSDean VidafarNo ratings yet
- SPSSTutorial 1Document50 pagesSPSSTutorial 1BharatNo ratings yet
- SPSS Step-by-Step Tutorial: Part 1Document50 pagesSPSS Step-by-Step Tutorial: Part 1ntagungiraNo ratings yet
- Exercise: 1 SPSS (Statistical Package For Social Sciences)Document43 pagesExercise: 1 SPSS (Statistical Package For Social Sciences)Karthi Keyan100% (1)
- Note - SPSS For Customer AnalysisDocument18 pagesNote - SPSS For Customer Analysisصالح الشبحيNo ratings yet
- Final SSB Manual Mbn605 08.08Document46 pagesFinal SSB Manual Mbn605 08.08khanrules2012No ratings yet
- SPSS Tutorial Lecture Notes Please See The Full SPSS Tutorial From SPSS SoftwareDocument20 pagesSPSS Tutorial Lecture Notes Please See The Full SPSS Tutorial From SPSS SoftwareSnow WhitNo ratings yet
- Exploratory Data AnalysisDocument38 pagesExploratory Data Analysishss601No ratings yet
- Learning SPSS: Data and EDADocument40 pagesLearning SPSS: Data and EDAscr33nwriterNo ratings yet
- Experimental WorksheetDocument8 pagesExperimental WorksheetAlPHA NiNjANo ratings yet
- Learning SPSS: Data and EDADocument40 pagesLearning SPSS: Data and EDARamyLloydLotillaNo ratings yet
- SPSSDocument2 pagesSPSSAngelaNo ratings yet
- Intro to SPSS: Learn Layout & FunctionsDocument6 pagesIntro to SPSS: Learn Layout & FunctionsManikandan SankarNo ratings yet
- Getting Started With SPSSDocument8 pagesGetting Started With SPSSMoosa MuhammadhNo ratings yet
- SPSS Introduction Group AssignmentDocument32 pagesSPSS Introduction Group AssignmentkutoyaNo ratings yet
- Spss Crosstabs Instructions Final DraftDocument9 pagesSpss Crosstabs Instructions Final Draftapi-669698004No ratings yet
- Workshop Series: ContentsDocument10 pagesWorkshop Series: ContentsAnonymous kTVBUxrNo ratings yet
- CRS Notes-1Document10 pagesCRS Notes-1Abdulai FofanahNo ratings yet
- RM Practical FileDocument59 pagesRM Practical Filegarvit sharmaNo ratings yet
- Spss ExercisesDocument13 pagesSpss ExercisesEbenezerNo ratings yet
- Presentation 1Document55 pagesPresentation 1Zeleke GeresuNo ratings yet
- SPSS For Windows: Introduction ToDocument26 pagesSPSS For Windows: Introduction ToganeshantreNo ratings yet
- (Ebook PDF) - Statistics. .Spss - TutorialDocument15 pages(Ebook PDF) - Statistics. .Spss - TutorialMASAIER4394% (17)
- Lesson 1 SPSS Windows and FilesDocument125 pagesLesson 1 SPSS Windows and FilesEnatnesh AsayeNo ratings yet
- SPSS Guide for WindowsDocument16 pagesSPSS Guide for WindowsFabio Luis BusseNo ratings yet
- Session 1: Module Introduction and Getting Started With StataDocument35 pagesSession 1: Module Introduction and Getting Started With StataHector GarciaNo ratings yet
- SPSS HandoutDocument43 pagesSPSS HandoutÖrdinärySoel100% (1)
- Data Management & SPSS: Khan Sarfaraz AliDocument10 pagesData Management & SPSS: Khan Sarfaraz AliDr. Khan Sarfaraz AliNo ratings yet
- Syarif Hidayat - ES1Document9 pagesSyarif Hidayat - ES1HysteriaNo ratings yet
- 0 Data Entry ADocument7 pages0 Data Entry ANazia SyedNo ratings yet
- Mba Ii DviDocument43 pagesMba Ii DviArshad JamilNo ratings yet
- Data Analysis Guide SpssDocument58 pagesData Analysis Guide SpssUrvashi KhedooNo ratings yet
- Presentation 2Document34 pagesPresentation 2Zeleke GeresuNo ratings yet
- Furman University Statistics Using SPSSDocument117 pagesFurman University Statistics Using SPSSRomer GesmundoNo ratings yet
- SPSS Windows and File TypesDocument115 pagesSPSS Windows and File TypesRomer GesmundoNo ratings yet
- SPSS Refresher Course File OpeningDocument20 pagesSPSS Refresher Course File Openingfrancisco_araujo_22100% (1)
- PDFDocument114 pagesPDFSmart SarimNo ratings yet
- Cursocompleto de Spss AulaclicDocument58 pagesCursocompleto de Spss Aulacliceloy felipesNo ratings yet
- Spss IntroDocument61 pagesSpss Introbakhtawar sheraniNo ratings yet
- SpssDocument16 pagesSpssSUMITNo ratings yet
- Spss AssignmentDocument28 pagesSpss AssignmentAnu S R100% (1)
- Oxford University Press - Online Resource Centre - Multiple Choice QuestionsDocument4 pagesOxford University Press - Online Resource Centre - Multiple Choice Questionsshahid Hussain100% (1)
- Tutorial Del Programa SciDAVisDocument35 pagesTutorial Del Programa SciDAVisHect FariNo ratings yet
- SPSS For Beginners: An Illustrative Step-by-Step Approach to Analyzing Statistical dataFrom EverandSPSS For Beginners: An Illustrative Step-by-Step Approach to Analyzing Statistical dataNo ratings yet
- Tableau Training Manual 9.0 Basic Version: This Via Tableau Training Manual Was Created for Both New and IntermediateFrom EverandTableau Training Manual 9.0 Basic Version: This Via Tableau Training Manual Was Created for Both New and IntermediateRating: 3 out of 5 stars3/5 (1)
- Microsoft Office Productivity Pack: Microsoft Excel, Microsoft Word, and Microsoft PowerPointFrom EverandMicrosoft Office Productivity Pack: Microsoft Excel, Microsoft Word, and Microsoft PowerPointNo ratings yet
- Icd 10 Diagnosa GigiDocument2 pagesIcd 10 Diagnosa GigiElok Faiqotul UmmaNo ratings yet
- Curaprox BrochureDocument68 pagesCuraprox BrochureElok Faiqotul UmmaNo ratings yet
- Contoh Rundown Basic Life SupportDocument2 pagesContoh Rundown Basic Life SupportElok Faiqotul Umma100% (1)
- Tongue DisordersDocument68 pagesTongue DisordersSiskaJanerNo ratings yet
- Comprehensive Periodontal Exam GuideDocument40 pagesComprehensive Periodontal Exam GuideKavin SandhuNo ratings yet
- Jadwal AcaraDocument2 pagesJadwal AcaraElok Faiqotul UmmaNo ratings yet
- Dental FormDocument1 pageDental FormElok Faiqotul UmmaNo ratings yet
- In Most Patients With Frictional KeratosisDocument1 pageIn Most Patients With Frictional KeratosisElok Faiqotul UmmaNo ratings yet
- Product Knowledge - Espe Sil Ifu WeDocument2 pagesProduct Knowledge - Espe Sil Ifu WeElok Faiqotul UmmaNo ratings yet
- Gambaran Tumpatan Amalgam Dan Semen Ionomer Kaca Pada Masyarakat Kelurahan Kalumpang Kecamatan Ternate TengahDocument2 pagesGambaran Tumpatan Amalgam Dan Semen Ionomer Kaca Pada Masyarakat Kelurahan Kalumpang Kecamatan Ternate TengahElok Faiqotul UmmaNo ratings yet
- A Review On Peppermint OilDocument7 pagesA Review On Peppermint OilElok Faiqotul UmmaNo ratings yet
- Acrylic AcidDocument7 pagesAcrylic AcidElok Faiqotul Umma0% (1)
- Gambaran Tumpatan Amalgam Dan Semen Ionomer Kaca Pada Masyarakat Kelurahan Kalumpang Kecamatan Ternate TengahDocument2 pagesGambaran Tumpatan Amalgam Dan Semen Ionomer Kaca Pada Masyarakat Kelurahan Kalumpang Kecamatan Ternate TengahElok Faiqotul UmmaNo ratings yet
- AcroleinDocument4 pagesAcroleinElok Faiqotul UmmaNo ratings yet
- Local Anesthesia in Pediatric DentistryDocument31 pagesLocal Anesthesia in Pediatric DentistryMohamed Beshi100% (1)
- Medicallycompromised 1233751509281867 3Document31 pagesMedicallycompromised 1233751509281867 3Wafa AL-sooryNo ratings yet
- Konservasi GigiDocument1 pageKonservasi GigisofiandwimardiantoNo ratings yet
- Materi SEMINAR FixDocument5 pagesMateri SEMINAR FixElok Faiqotul UmmaNo ratings yet
- Burning Mouth Syndrome: Symptoms, Causes and Treatment of Burning TongueDocument4 pagesBurning Mouth Syndrome: Symptoms, Causes and Treatment of Burning TongueElok Faiqotul UmmaNo ratings yet
- 119-137 DR Agus Sel Squamosa CarsinomaDocument19 pages119-137 DR Agus Sel Squamosa CarsinomaElok Faiqotul UmmaNo ratings yet
- Evaluation of Consistency in Dosing Directions and Measuring Devices For Pediatric Nonprescription Liquid MedicationsDocument8 pagesEvaluation of Consistency in Dosing Directions and Measuring Devices For Pediatric Nonprescription Liquid MedicationsElok Faiqotul UmmaNo ratings yet