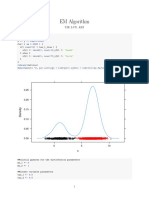
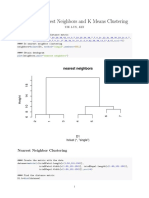
You might also like
- R Basics PDFDocument10 pagesR Basics PDFSAILY JADHAVNo ratings yet
- R ExamplesDocument56 pagesR ExamplesAnimesh DubeyNo ratings yet
- Cross-Validation and The BootstrapDocument5 pagesCross-Validation and The Bootstrapapi-285777244No ratings yet
- Normality Skewness KurtosisDocument7 pagesNormality Skewness Kurtosisapi-285777244No ratings yet
- PCR and Pls RegressionDocument5 pagesPCR and Pls Regressionapi-285777244No ratings yet
- Support Vector Machine With Multiple ClassesDocument5 pagesSupport Vector Machine With Multiple Classesapi-285777244100% (1)
- Practice 1 From Analysis of Financial Time SeriesDocument11 pagesPractice 1 From Analysis of Financial Time Seriesapi-285777244No ratings yet
- Support Vector ClassificationDocument8 pagesSupport Vector Classificationapi-285777244No ratings yet
- Em AlgorithmDocument4 pagesEm Algorithmapi-285777244No ratings yet
- Simple Linear RegressionDocument9 pagesSimple Linear Regressionapi-285777244No ratings yet
- Autoregressive Integrated Moving Average ArimaDocument23 pagesAutoregressive Integrated Moving Average Arimaapi-285777244No ratings yet
- 7 Methods To Calculate PCDocument10 pages7 Methods To Calculate PCapi-285777244No ratings yet
- Non-Stationary ModelsDocument13 pagesNon-Stationary Modelsapi-285777244No ratings yet
- HW 6Document14 pagesHW 6api-285777244No ratings yet
- Stats101a Homework8Document7 pagesStats101a Homework8api-285777244No ratings yet
- Harmonic Seasonal ModelsDocument10 pagesHarmonic Seasonal Modelsapi-285777244No ratings yet
- HW 7Document11 pagesHW 7api-285777244No ratings yet
- Monte Carlo IntegrationDocument3 pagesMonte Carlo Integrationapi-285777244No ratings yet
- Importance SamplingDocument8 pagesImportance Samplingapi-285777244No ratings yet
- ClusteringDocument8 pagesClusteringapi-285777244No ratings yet
- Practice of Introductory Time Series With RDocument22 pagesPractice of Introductory Time Series With Rapi-285777244No ratings yet
- HW 2Document8 pagesHW 2api-285777244No ratings yet
- Practice 1 From Introductory Time Series With RDocument14 pagesPractice 1 From Introductory Time Series With Rapi-285777244No ratings yet
- Ridge Regression and The LassoDocument7 pagesRidge Regression and The Lassoapi-285777244No ratings yet
- Regression SplinesDocument4 pagesRegression Splinesapi-285777244No ratings yet
- Principal Component Analysis Regression Visualization and InterpretationDocument10 pagesPrincipal Component Analysis Regression Visualization and Interpretationapi-285777244No ratings yet
- Polynomial Regression and Step FunctionDocument6 pagesPolynomial Regression and Step Functionapi-285777244100% (1)
- R-Tutorial - IntroductionDocument30 pagesR-Tutorial - Introductionlamaram32No ratings yet
- Data Visualization With Ggplot2: Install PackagesDocument19 pagesData Visualization With Ggplot2: Install PackagesPablo MedranoNo ratings yet
- Count words by length in text file(40Document7 pagesCount words by length in text file(40queen setiloNo ratings yet
- Fitting Data - SciPy Cookbook Documentation PDFDocument10 pagesFitting Data - SciPy Cookbook Documentation PDFninjai_thelittleninjaNo ratings yet
- Haskell 09Document7 pagesHaskell 09Марина ЖуковскаяNo ratings yet
- Solution HW04 of CIS 194 Haskell Course 2015Document3 pagesSolution HW04 of CIS 194 Haskell Course 2015Vitalie CracanNo ratings yet
- Haskell 01Document1 pageHaskell 01Марина ЖуковскаяNo ratings yet
- Python Lists: Access, Update, Delete ElementsDocument8 pagesPython Lists: Access, Update, Delete ElementsJyotirmay SahuNo ratings yet
- Module 4 - 1Document2 pagesModule 4 - 1deepakkashyaNo ratings yet
- Variable SelectionDocument15 pagesVariable Selectionapi-285777244No ratings yet
- NumPy Cheat Sheets: Tips and Tricks for Data AnalysisDocument1 pageNumPy Cheat Sheets: Tips and Tricks for Data AnalysisToldo94No ratings yet
- Compare character frequency between filesDocument47 pagesCompare character frequency between filesChirantan SahooNo ratings yet
- DAA Elab 1Document127 pagesDAA Elab 1anant33331No ratings yet
- Chapter 1 Part 1 SolutionsDocument2 pagesChapter 1 Part 1 Solutionsjordanpitt269No ratings yet
- Rmarkdown Cheatsheet 2.0Document2 pagesRmarkdown Cheatsheet 2.0Weid Davinio PanDuroNo ratings yet
- An R Tutorial Starting OutDocument9 pagesAn R Tutorial Starting OutWendy WeiNo ratings yet
- Window Function in PysparkDocument8 pagesWindow Function in Pysparkkubir nannaware100% (1)
- Python AssignmentDocument5 pagesPython AssignmentRavi KishoreNo ratings yet
- Practice of Analysis of Financial Time Series by Ruey S TsayDocument10 pagesPractice of Analysis of Financial Time Series by Ruey S Tsayapi-285777244No ratings yet
- R - Tutorial: Matrices Are VectorsDocument13 pagesR - Tutorial: Matrices Are VectorsИван РадоновNo ratings yet
- XIIth Practical FileDocument43 pagesXIIth Practical FilenubaidNo ratings yet
- Trade Bulls v1.2Document5 pagesTrade Bulls v1.2mauricioNo ratings yet
- Module 5 - 2Document1 pageModule 5 - 2deepakkashyaNo ratings yet
- Saveetha Institute of Medical and Technical Sciences: Unit V Plotting and Regression Analysis in RDocument63 pagesSaveetha Institute of Medical and Technical Sciences: Unit V Plotting and Regression Analysis in RMuzakir Laikh KhanNo ratings yet
- Jesse Lesperance Smre Homework 2 Reliability Apportionment Component ImportanceDocument10 pagesJesse Lesperance Smre Homework 2 Reliability Apportionment Component Importanceeeit_nizamNo ratings yet
- Function - SortDocument5 pagesFunction - SortZhuan WuNo ratings yet
- Lecture 4Document2 pagesLecture 4datsnoNo ratings yet
- 14 3 DP Optimal Binary Search Trees 4upDocument4 pages14 3 DP Optimal Binary Search Trees 4upcute_guddyNo ratings yet
- 10th Maths - Creative One Mark Questions With Answer Key - English MediumDocument9 pages10th Maths - Creative One Mark Questions With Answer Key - English MediumAKSHAY SekarNo ratings yet
- Lab 9Document4 pagesLab 9Beitriss ChuaNo ratings yet
- Aditya Garg DMDWDocument40 pagesAditya Garg DMDWRaj NishNo ratings yet
- Scalable Data Processing in RDocument8 pagesScalable Data Processing in ROctavio FloresNo ratings yet
- HW 7Document11 pagesHW 7api-285777244No ratings yet
- Point of TangencyDocument5 pagesPoint of Tangencyapi-285777244No ratings yet
- SQL StatementDocument1 pageSQL Statementapi-285777244No ratings yet
- HW 2Document8 pagesHW 2api-285777244No ratings yet
- Coordinate Descent and Golden Selection SearchDocument2 pagesCoordinate Descent and Golden Selection Searchapi-285777244No ratings yet
- Stats101a Homework8Document7 pagesStats101a Homework8api-285777244No ratings yet
- HW 4Document12 pagesHW 4api-285777244No ratings yet
- HW 6Document14 pagesHW 6api-285777244No ratings yet
- HW 5Document1 pageHW 5api-285777244No ratings yet
- How To Import From Saleforce To PardotDocument3 pagesHow To Import From Saleforce To Pardotapi-285777244No ratings yet
- HW 2Document13 pagesHW 2api-285777244No ratings yet
- Handwriting RecognitionDocument10 pagesHandwriting Recognitionapi-285777244No ratings yet
- HW 3Document10 pagesHW 3api-285777244No ratings yet
- HW 1Document6 pagesHW 1api-285777244No ratings yet
- Anova ReviewDocument8 pagesAnova Reviewapi-285777244100% (1)
- ClusteringDocument8 pagesClusteringapi-285777244No ratings yet
- Monte Carlo IntegrationDocument3 pagesMonte Carlo Integrationapi-285777244No ratings yet
- Em AlgorithmDocument4 pagesEm Algorithmapi-285777244No ratings yet
- Non-Stationary ModelsDocument13 pagesNon-Stationary Modelsapi-285777244No ratings yet
- Harmonic Seasonal ModelsDocument10 pagesHarmonic Seasonal Modelsapi-285777244No ratings yet
- Adjusting BetasDocument2 pagesAdjusting Betasapi-285777244No ratings yet
- Conditional Heteroscedastic ModelsDocument20 pagesConditional Heteroscedastic Modelsapi-285777244No ratings yet
- Generalized Additive ModelDocument10 pagesGeneralized Additive Modelapi-285777244No ratings yet
- Variable SelectionDocument15 pagesVariable Selectionapi-285777244No ratings yet
- Multivariate Monte Carlo IntegrationDocument2 pagesMultivariate Monte Carlo Integrationapi-285777244No ratings yet
- Gradient Steepest DescentDocument7 pagesGradient Steepest Descentapi-285777244No ratings yet
- Practice 2 From Introductory Time Series With RDocument18 pagesPractice 2 From Introductory Time Series With Rapi-285777244No ratings yet
- MS8 IGNOU MBA Assignment 2009Document6 pagesMS8 IGNOU MBA Assignment 2009rakeshpipadaNo ratings yet
- Chi Square TestsDocument12 pagesChi Square TestsFun Toosh345No ratings yet
- Analysis of VarianceDocument51 pagesAnalysis of Varianceapi-19916399No ratings yet
- One-Way Analysis of VarianceDocument4 pagesOne-Way Analysis of VarianceRami DouakNo ratings yet
- Sta10003 - Oua Unit Outline - sp4 2014Document11 pagesSta10003 - Oua Unit Outline - sp4 2014seggy7No ratings yet
- From Alpha To Omega: A Practical Solution To The Pervasive Problem of Internal Consistency EstimationDocument14 pagesFrom Alpha To Omega: A Practical Solution To The Pervasive Problem of Internal Consistency EstimationLuis Angel Hernandez MirandaNo ratings yet
- WINSEM2020-21 ECE3502 ETH VL2020210501413 Reference Material I 29-Apr-2021 New PPTDocument23 pagesWINSEM2020-21 ECE3502 ETH VL2020210501413 Reference Material I 29-Apr-2021 New PPTAryan VermaNo ratings yet
- (STATISTICS & PROBABILITY) Unit II - Lesson 1 Understanding The Normal Curve DistributionDocument14 pages(STATISTICS & PROBABILITY) Unit II - Lesson 1 Understanding The Normal Curve DistributionVany SpadesNo ratings yet
- Skittles ProjectDocument4 pagesSkittles Projectapi-299945887No ratings yet
- Blended learning improves modeling skills and chemistry learningDocument9 pagesBlended learning improves modeling skills and chemistry learningishak hasibuanNo ratings yet
- Telecom Customer Churn Project ReportDocument25 pagesTelecom Customer Churn Project ReportSravanthi Ammu50% (2)
- Original Introduction To Mathematical Statistics 8Th Edition by Robert V Hogg Full ChapterDocument41 pagesOriginal Introduction To Mathematical Statistics 8Th Edition by Robert V Hogg Full Chapterantonio.cummins133100% (24)
- Extraneous VariablesDocument3 pagesExtraneous VariablesAmna MazharNo ratings yet
- Tutorial AnswersDocument5 pagesTutorial AnswersPetrinaNo ratings yet
- Time Series Forecasting Chapter 16Document43 pagesTime Series Forecasting Chapter 16Jeff Ray SanchezNo ratings yet
- Bit 3 LessonDocument20 pagesBit 3 LessonKalum PalihawadanaNo ratings yet
- POST Test StatDocument3 pagesPOST Test Statadlez nootibNo ratings yet
- Sampling-MethodsDocument2 pagesSampling-Methodsxellee shethNo ratings yet
- 052180661Document571 pages052180661api-26426597No ratings yet
- This Study Resource Was: Week 6 Homework - Summer 2020Document9 pagesThis Study Resource Was: Week 6 Homework - Summer 2020Kim CraftNo ratings yet
- X1 Ke Y: Variables Entered/RemovedDocument3 pagesX1 Ke Y: Variables Entered/RemovedAgeng FitriyantoNo ratings yet
- Research Aptitude TestDocument14 pagesResearch Aptitude TestMaths CTNo ratings yet
- Analysis of Variance (ANOVA) : The F Distribution Good For Two or More GroupsDocument21 pagesAnalysis of Variance (ANOVA) : The F Distribution Good For Two or More GroupsSarthak GuptaNo ratings yet
- Mor 7 Nvsu-Fr-Icd-05-00Document20 pagesMor 7 Nvsu-Fr-Icd-05-00Aliza PoyatosNo ratings yet
- SUBMIT ASSIGNMENT - Spearmann Correlation PT 1Document8 pagesSUBMIT ASSIGNMENT - Spearmann Correlation PT 1Ezad juferiNo ratings yet
- Practical Session 1 SolvedDocument14 pagesPractical Session 1 SolvedThéobald VitouxNo ratings yet
- Basic Statistics ConceptsDocument29 pagesBasic Statistics ConceptsthinagaranNo ratings yet
- SPSS Problems SolvedDocument15 pagesSPSS Problems SolvedGreeshma100% (2)
- Statistical MethodsDocument65 pagesStatistical Methodsrecep100% (4)
- One Way DesignDocument104 pagesOne Way DesignUkhtie JulieNo ratings yet