You might also like
- HW 7Document11 pagesHW 7api-285777244No ratings yet
- 7 Methods To Calculate PCDocument10 pages7 Methods To Calculate PCapi-285777244No ratings yet
- HW 6Document14 pagesHW 6api-285777244No ratings yet
- Support Vector Machine With Multiple ClassesDocument5 pagesSupport Vector Machine With Multiple Classesapi-285777244100% (1)
- Harmonic Seasonal ModelsDocument10 pagesHarmonic Seasonal Modelsapi-285777244No ratings yet
- Support Vector ClassificationDocument8 pagesSupport Vector Classificationapi-285777244No ratings yet
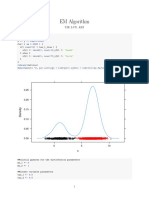
- Em AlgorithmDocument4 pagesEm Algorithmapi-285777244No ratings yet
- Stats101a Homework8Document7 pagesStats101a Homework8api-285777244No ratings yet
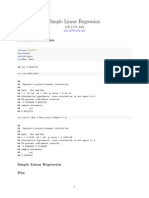
- Simple Linear RegressionDocument9 pagesSimple Linear Regressionapi-285777244No ratings yet
- Monte Carlo IntegrationDocument3 pagesMonte Carlo Integrationapi-285777244No ratings yet
- PCR and Pls RegressionDocument5 pagesPCR and Pls Regressionapi-285777244No ratings yet
- Normality Skewness KurtosisDocument7 pagesNormality Skewness Kurtosisapi-285777244No ratings yet
- Autoregressive Integrated Moving Average ArimaDocument23 pagesAutoregressive Integrated Moving Average Arimaapi-285777244No ratings yet
- Non-Stationary ModelsDocument13 pagesNon-Stationary Modelsapi-285777244No ratings yet
- Importance SamplingDocument8 pagesImportance Samplingapi-285777244No ratings yet
- Random ForestsDocument10 pagesRandom Forestsapi-285777244No ratings yet
- Cross-Validation and The BootstrapDocument5 pagesCross-Validation and The Bootstrapapi-285777244No ratings yet
- Practice 1 From Analysis of Financial Time SeriesDocument11 pagesPractice 1 From Analysis of Financial Time Seriesapi-285777244No ratings yet
- HW 2Document8 pagesHW 2api-285777244No ratings yet
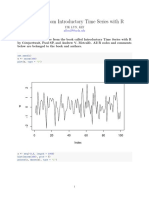
- Practice of Introductory Time Series With RDocument22 pagesPractice of Introductory Time Series With Rapi-285777244No ratings yet
- Practice 1 From Introductory Time Series With RDocument14 pagesPractice 1 From Introductory Time Series With Rapi-285777244No ratings yet
- Regression SplinesDocument4 pagesRegression Splinesapi-285777244No ratings yet
- Ridge Regression and The LassoDocument7 pagesRidge Regression and The Lassoapi-285777244No ratings yet
- Trade Bulls v1.2Document5 pagesTrade Bulls v1.2mauricioNo ratings yet
- Data Visualization With Ggplot2: Install PackagesDocument19 pagesData Visualization With Ggplot2: Install PackagesPablo MedranoNo ratings yet
- Count words by length in text file(40Document7 pagesCount words by length in text file(40queen setiloNo ratings yet
- Rogue Lineage Philo ScriptDocument2 pagesRogue Lineage Philo Scriptnigger kidNo ratings yet
- Subsetting Data in RDocument44 pagesSubsetting Data in RGoyobodNo ratings yet
- Polynomial Regression and Step FunctionDocument6 pagesPolynomial Regression and Step Functionapi-285777244100% (1)
- Principal Component Analysis Regression Visualization and InterpretationDocument10 pagesPrincipal Component Analysis Regression Visualization and Interpretationapi-285777244No ratings yet
- Haskell 09Document7 pagesHaskell 09Марина ЖуковскаяNo ratings yet
- Fitting Data - SciPy Cookbook Documentation PDFDocument10 pagesFitting Data - SciPy Cookbook Documentation PDFninjai_thelittleninjaNo ratings yet
- Function - SortDocument5 pagesFunction - SortZhuan WuNo ratings yet
- Codewriting Solutions PythonDocument25 pagesCodewriting Solutions PythonMarlin Pohlman100% (4)
- DAA Elab 1Document127 pagesDAA Elab 1anant33331No ratings yet
- Doubly Linked List - Attempt ReviewDocument22 pagesDoubly Linked List - Attempt ReviewJo ChNo ratings yet
- XIIth Practical FileDocument43 pagesXIIth Practical FilenubaidNo ratings yet
- Solution HW04 of CIS 194 Haskell Course 2015Document3 pagesSolution HW04 of CIS 194 Haskell Course 2015Vitalie CracanNo ratings yet
- Apcs - Recursion WorksheetDocument5 pagesApcs - Recursion Worksheetapi-355180314No ratings yet
- Python Lists: Access, Update, Delete ElementsDocument8 pagesPython Lists: Access, Update, Delete ElementsJyotirmay SahuNo ratings yet
- LAB 3: Binary Tree and Binary Search Tree EX1Document33 pagesLAB 3: Binary Tree and Binary Search Tree EX1Cao Minh Quang100% (1)
- CS2405 Computer Graphics Lab ManualDocument70 pagesCS2405 Computer Graphics Lab ManualDhilip Prabakaran100% (2)
- Mcdermott 6014 Final Summer B 17Document14 pagesMcdermott 6014 Final Summer B 17api-373102817No ratings yet
- R Basics PDFDocument10 pagesR Basics PDFSAILY JADHAVNo ratings yet
- Variosalgoritmos - Jupyter NotebookDocument9 pagesVariosalgoritmos - Jupyter NotebookPAULO CESAR CALDERON BERMUDO100% (1)
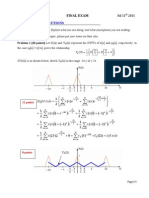
- Y_d(Ω) sketch for problem 1Document4 pagesY_d(Ω) sketch for problem 1Le HuyNo ratings yet
- Statistics exp 4 - P(Z) calculations and visualisationsDocument8 pagesStatistics exp 4 - P(Z) calculations and visualisationsPranavNo ratings yet
- Graphics With C: Explore The UnexploredDocument9 pagesGraphics With C: Explore The UnexploredAdi adiNo ratings yet
- CST 370 - Spring A 2020 Homework 3: Answer: 1Document4 pagesCST 370 - Spring A 2020 Homework 3: Answer: 1api-427618266No ratings yet
- MAT 244 Differential Equations Fall 2014 Homework 3 SolutionsDocument2 pagesMAT 244 Differential Equations Fall 2014 Homework 3 SolutionsRevownSadaNo ratings yet
- Ee132b Hw1 SolDocument4 pagesEe132b Hw1 SolAhmed HassanNo ratings yet
- 49 Partial FractionsDocument9 pages49 Partial Fractionsapi-299265916No ratings yet
- IP - Pandas 1 & 2 (Worksheet) Class 12Document16 pagesIP - Pandas 1 & 2 (Worksheet) Class 12WhiteNo ratings yet
- Cot4501sp17 Hw2solDocument4 pagesCot4501sp17 Hw2solNathanael HooperNo ratings yet
- GeneratorDocument4 pagesGeneratorNQ BN100% (1)
- Module 5: Peer Reviewed Assignment: OutlineDocument55 pagesModule 5: Peer Reviewed Assignment: OutlineAshutosh KumarNo ratings yet
- ProjectDocument17 pagesProjectmohamed mohsenNo ratings yet
- Codes WorkshopDocument13 pagesCodes Workshopiqra mumtazNo ratings yet
- K MeansDocument4 pagesK Meansmohamed mohsenNo ratings yet
- Analytic Geometry: Graphic Solutions Using Matlab LanguageFrom EverandAnalytic Geometry: Graphic Solutions Using Matlab LanguageNo ratings yet
- HW 2Document8 pagesHW 2api-285777244No ratings yet
- SQL StatementDocument1 pageSQL Statementapi-285777244No ratings yet
- HW 4Document12 pagesHW 4api-285777244No ratings yet
- How To Import From Saleforce To PardotDocument3 pagesHow To Import From Saleforce To Pardotapi-285777244No ratings yet
- HW 2Document13 pagesHW 2api-285777244No ratings yet
- HW 3Document10 pagesHW 3api-285777244No ratings yet
- Anova ReviewDocument8 pagesAnova Reviewapi-285777244100% (1)
- HW 5Document1 pageHW 5api-285777244No ratings yet
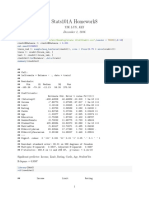
- Stats101a Homework8Document7 pagesStats101a Homework8api-285777244No ratings yet
- HW 1Document6 pagesHW 1api-285777244No ratings yet
- Point of TangencyDocument5 pagesPoint of Tangencyapi-285777244No ratings yet
- Handwriting RecognitionDocument10 pagesHandwriting Recognitionapi-285777244No ratings yet
- Coordinate Descent and Golden Selection SearchDocument2 pagesCoordinate Descent and Golden Selection Searchapi-285777244No ratings yet
- Em AlgorithmDocument4 pagesEm Algorithmapi-285777244No ratings yet
- Multivariate Monte Carlo IntegrationDocument2 pagesMultivariate Monte Carlo Integrationapi-285777244No ratings yet
- Adjusting BetasDocument2 pagesAdjusting Betasapi-285777244No ratings yet
- Non-Stationary ModelsDocument13 pagesNon-Stationary Modelsapi-285777244No ratings yet
- Conditional Heteroscedastic ModelsDocument20 pagesConditional Heteroscedastic Modelsapi-285777244No ratings yet
- Random ForestsDocument10 pagesRandom Forestsapi-285777244No ratings yet
- Gradient Steepest DescentDocument7 pagesGradient Steepest Descentapi-285777244No ratings yet
- Monte Carlo IntegrationDocument3 pagesMonte Carlo Integrationapi-285777244No ratings yet
- Generalized Additive ModelDocument10 pagesGeneralized Additive Modelapi-285777244No ratings yet
- PCR and Pls RegressionDocument5 pagesPCR and Pls Regressionapi-285777244No ratings yet
- Variable SelectionDocument15 pagesVariable Selectionapi-285777244No ratings yet
- Practice 2 From Introductory Time Series With RDocument18 pagesPractice 2 From Introductory Time Series With Rapi-285777244No ratings yet
- Clustering in BioinformaticsDocument110 pagesClustering in BioinformaticstisimpsonNo ratings yet
- Data Mining DBSCAN ClusteringDocument1 pageData Mining DBSCAN ClusteringSwappy BoiNo ratings yet
- 07 Hierarchical ClusteringDocument19 pages07 Hierarchical ClusteringOussama D. OtakuNo ratings yet
- Data Mining-Partitioning MethodsDocument7 pagesData Mining-Partitioning MethodsRaj Endran100% (1)
- CLUSTERING METHODSDocument7 pagesCLUSTERING METHODSNur AdliNo ratings yet
- Estimasi Sumberdaya Batubara Dengan Menggunakan Geostatistik KriggingDocument11 pagesEstimasi Sumberdaya Batubara Dengan Menggunakan Geostatistik KriggingVerima Jesica100% (1)
- RIVOIRARD - Cours - 00312 (Introduction To Disjunctive Kriging and Non Geostatistics)Document98 pagesRIVOIRARD - Cours - 00312 (Introduction To Disjunctive Kriging and Non Geostatistics)Cristian CollaoNo ratings yet
- Analisis Diskriminan Untuk Validasi Cluster Pada Studi Kasus Pengelompokan Kecamatan Di Kabupaten Jember Berdasarkan Status KemiskinanDocument10 pagesAnalisis Diskriminan Untuk Validasi Cluster Pada Studi Kasus Pengelompokan Kecamatan Di Kabupaten Jember Berdasarkan Status KemiskinanFADHIILA SENJALIANANo ratings yet
- Estimasi Sumberdaya Untuk Data Dengan Distribusi Lognormal Pada Endapan Urat Emas Gunung Pongkor Dengan Pendekatan GeostatistikDocument9 pagesEstimasi Sumberdaya Untuk Data Dengan Distribusi Lognormal Pada Endapan Urat Emas Gunung Pongkor Dengan Pendekatan GeostatistikAndi Baso Lovan AltamarNo ratings yet
- Assignment 2 - M0719077 - Naufal Adhi IyansyahDocument4 pagesAssignment 2 - M0719077 - Naufal Adhi IyansyahNaufal Adhi IyansyahNo ratings yet
- Lecture 3. Partitioning-Based Clustering MethodsDocument27 pagesLecture 3. Partitioning-Based Clustering MethodssharathdhamodaranNo ratings yet
- Agglomerative ClusteringDocument6 pagesAgglomerative ClusteringVarun BhayanaNo ratings yet
- CSE3506 - Essentials of Data Analytics: Facilitator: DR Sathiya Narayanan SDocument17 pagesCSE3506 - Essentials of Data Analytics: Facilitator: DR Sathiya Narayanan SWINORLOSENo ratings yet
- Introduction To Data Mining Clustering AnalysisDocument84 pagesIntroduction To Data Mining Clustering AnalysisakNo ratings yet
- Fuzzy C Means (Overlapping Clustering)Document13 pagesFuzzy C Means (Overlapping Clustering)Ravi GuptaNo ratings yet
- Incremental Clustering Algorithm Based on Mahalanobis DistanceDocument1 pageIncremental Clustering Algorithm Based on Mahalanobis DistanceKhairulNo ratings yet
- A Comparative Study of Various Algorithms To Detect Clustering in Spatial DataDocument42 pagesA Comparative Study of Various Algorithms To Detect Clustering in Spatial DataWoona HanishNo ratings yet
- STAT 544.01 - Topics - Spatial StatisticsDocument4 pagesSTAT 544.01 - Topics - Spatial StatisticswerwerwerNo ratings yet
- Amazon Food Review Clustering Using K-Means, Agglomerative & DBSCANDocument79 pagesAmazon Food Review Clustering Using K-Means, Agglomerative & DBSCANkrishnaNo ratings yet
- Analisis Faktor Calon Nasabah PT. Bank Central Asia Dalam Pembuatan Rekening Online Menggunakan Metode K-Means Clustering Studi Kasus Wisma Asia BCADocument8 pagesAnalisis Faktor Calon Nasabah PT. Bank Central Asia Dalam Pembuatan Rekening Online Menggunakan Metode K-Means Clustering Studi Kasus Wisma Asia BCAJurnal JTIK (Jurnal Teknologi Informasi dan Komunikasi)No ratings yet
- Analysis of Product Clustering Using K-Means Algorithm on PT Batamas Niaga Jaya Sales DataDocument16 pagesAnalysis of Product Clustering Using K-Means Algorithm on PT Batamas Niaga Jaya Sales DataputriNo ratings yet
- Detecting DDoS attacks using triage forensics and density-based k-means clusteringDocument3 pagesDetecting DDoS attacks using triage forensics and density-based k-means clusteringEdi SuwandiNo ratings yet
- Data Clustering: K-Means and Hierarchical ClusteringDocument24 pagesData Clustering: K-Means and Hierarchical Clusteringalexia007No ratings yet
- Cluster Analysis of Occupational Wage Data in RDocument18 pagesCluster Analysis of Occupational Wage Data in RdebojyotiNo ratings yet
- Código K-Means en SpyderDocument3 pagesCódigo K-Means en SpyderManuel Calva ZNo ratings yet
- Non-Hierarchical Cluster Analysis Using K-Modes Method On Student of Statistics Major 2015 at The Faculty of Mathematics and Natural Sciences Mulawarman UniversityDocument8 pagesNon-Hierarchical Cluster Analysis Using K-Modes Method On Student of Statistics Major 2015 at The Faculty of Mathematics and Natural Sciences Mulawarman UniversityFitri AzizaNo ratings yet
- Chapter 3: Cluster Analysis: 3.1 Basic Concepts of ClusteringDocument33 pagesChapter 3: Cluster Analysis: 3.1 Basic Concepts of ClusteringpreetamNo ratings yet
- Data Mining ClusteringDocument76 pagesData Mining ClusteringAnjali Asha JacobNo ratings yet
- Concepts and Techniques: Data MiningDocument101 pagesConcepts and Techniques: Data MiningJiyual MustiNo ratings yet
- Assignment 10: Introduction To Machine Learning Prof. B. RavindranDocument4 pagesAssignment 10: Introduction To Machine Learning Prof. B. RavindranPraveen Kumar Kandhala100% (1)