You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- A System Has 16 Tapes, and 4 Processes P 0, P 1, P 2, P 3 With Corresponding RequestsDocument15 pagesA System Has 16 Tapes, and 4 Processes P 0, P 1, P 2, P 3 With Corresponding RequestsHoàng NguyễnNo ratings yet
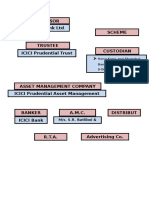
- Sponsor ICICI Bank Ltd. Scheme: M/s. S.R. Batliboi & Co. LLPDocument1 pageSponsor ICICI Bank Ltd. Scheme: M/s. S.R. Batliboi & Co. LLPSubhajit SahaNo ratings yet
- MC0085 Set 2 Solved Assingment 2012Document21 pagesMC0085 Set 2 Solved Assingment 2012Subhajit SahaNo ratings yet
- HGDocument1 pageHGSubhajit SahaNo ratings yet
- MC0081 Set 1 &2 Solved Assingment 2012Document41 pagesMC0081 Set 1 &2 Solved Assingment 2012Subhajit SahaNo ratings yet
- Class MembersDocument39 pagesClass MembersSubhajit SahaNo ratings yet
- Mc0079 - 1 - (Me)Document18 pagesMc0079 - 1 - (Me)Subhajit SahaNo ratings yet
- Computer Application - PCC-CM-PHD103 - Computer - Application Class Assignment:1Document3 pagesComputer Application - PCC-CM-PHD103 - Computer - Application Class Assignment:1Rakesh JhaNo ratings yet
- Introduction To Parallel ProgrammingDocument53 pagesIntroduction To Parallel ProgrammingDejan VujičićNo ratings yet
- 0x01-Shell PermissionsDocument4 pages0x01-Shell PermissionsMmaNo ratings yet
- Unit4 Java FullDocument21 pagesUnit4 Java Fullmadani hussainNo ratings yet
- Woot17 Paper KurmusDocument9 pagesWoot17 Paper Kurmushombre pocilgaNo ratings yet
- HH Bea Gayr R00tk1t 2008Document243 pagesHH Bea Gayr R00tk1t 2008MetalAnonNo ratings yet
- Multi Threading ShrikantDocument106 pagesMulti Threading ShrikantKomal RansingNo ratings yet
- SQL WMI ProviderDocument13 pagesSQL WMI ProvidertiecvuibatngoNo ratings yet
- Amithlon How To:: (A Wordy Guide To Setting Up Amigaos On An X86 Box) Why?Document8 pagesAmithlon How To:: (A Wordy Guide To Setting Up Amigaos On An X86 Box) Why?Jairo Navarro DiasNo ratings yet
- Tutorial 5Document5 pagesTutorial 5armanNo ratings yet
- Com - Dual.space - Parallel.apps - Multiaccounts.thinktech LogcatDocument227 pagesCom - Dual.space - Parallel.apps - Multiaccounts.thinktech Logcatsurioadrian19No ratings yet
- TLE ICT 10 - Prepare and Create An Installer - Activity SheetDocument3 pagesTLE ICT 10 - Prepare and Create An Installer - Activity SheetGioSanBuenaventura100% (1)
- LogDocument256 pagesLogErnitaria PurbaNo ratings yet
- Couesera Python On OsDocument3 pagesCouesera Python On OsJashwanth REddyNo ratings yet
- CoE 135 Notes 2Document7 pagesCoE 135 Notes 2Iman EncarnacionNo ratings yet
- Missing OLEAUT32.DLLDocument2 pagesMissing OLEAUT32.DLLplanner.dandelionNo ratings yet
- UntitledDocument1 pageUntitledeggy officialNo ratings yet
- Localizable Unc0verDocument9 pagesLocalizable Unc0verAvoine CheyNo ratings yet
- SchedulingDocument44 pagesSchedulingapi-19975941No ratings yet
- How It Works Bare-Metal BMR For LinuxDocument23 pagesHow It Works Bare-Metal BMR For Linuxjalvarez82No ratings yet
- FIFA Mod Manager Log20230902 - 002Document54 pagesFIFA Mod Manager Log20230902 - 002BHASKAR TalukdarNo ratings yet
- Debian HandbookDocument495 pagesDebian HandbookRian HermawanNo ratings yet
- Distributed File Systems & Name Services: UNIT-4Document70 pagesDistributed File Systems & Name Services: UNIT-4Shreya BhashyakarlaNo ratings yet
- Endpoint Security Via Application Sandboxing and Virtualization: Past, Present, FutureDocument27 pagesEndpoint Security Via Application Sandboxing and Virtualization: Past, Present, FutureAnubha KabraNo ratings yet
- Basic Shell ScriptingDocument6 pagesBasic Shell Scriptingapi-315485367No ratings yet
- Windows Perfomance TroubleshootingDocument223 pagesWindows Perfomance TroubleshootingSharon KarkadaNo ratings yet
- CS325 Operating Systems Spring 2021: Computer-System StructuresDocument25 pagesCS325 Operating Systems Spring 2021: Computer-System StructuresAftab JahangirNo ratings yet
- LogDocument881 pagesLogSthalling MendezNo ratings yet
- MDF To Exe Converter PDFDocument2 pagesMDF To Exe Converter PDFjesus de jesusNo ratings yet