You might also like
- Ten-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesFrom EverandTen-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesNo ratings yet
- Upper Bound Lower BoundDocument37 pagesUpper Bound Lower BoundArunabh NagNo ratings yet
- SortingDocument22 pagesSortingayush Baiswar WIqFuKAHXxNo ratings yet
- Unit 6 FinalbfgDocument23 pagesUnit 6 FinalbfgKrishna ThapaNo ratings yet
- Lab Session 07: ObjectDocument5 pagesLab Session 07: ObjectMohammad Anas BalochNo ratings yet
- Data Structures Guide: Arrays, Records, Pointers & AlgorithmsDocument27 pagesData Structures Guide: Arrays, Records, Pointers & Algorithmstowha elahiNo ratings yet
- Sorting Techniques: Bubble Sort Insertion Sort Selection Sort Quick Sort Merge SortDocument22 pagesSorting Techniques: Bubble Sort Insertion Sort Selection Sort Quick Sort Merge SortKumar Vidya100% (1)
- Algo Tri FusionDocument4 pagesAlgo Tri FusionLionel OueiNo ratings yet
- UNIT - V (Sorting and Searching)Document11 pagesUNIT - V (Sorting and Searching)varun MAJETINo ratings yet
- Sorting & Searching ALgorhithmDocument44 pagesSorting & Searching ALgorhithmShubham GhosalNo ratings yet
- Lec 2.1 (Arrays)Document19 pagesLec 2.1 (Arrays)SURYANo ratings yet
- Learn About ArraysDocument42 pagesLearn About Arraysprabhdeep kaurNo ratings yet
- Created By:: Mehak UID: 23837 Seee-CseDocument36 pagesCreated By:: Mehak UID: 23837 Seee-CseMitesh ChoubeyNo ratings yet
- Linear Arrays Representation & Traversal Insertion Deletion Linear Search Bubble Sort Binary SearchDocument18 pagesLinear Arrays Representation & Traversal Insertion Deletion Linear Search Bubble Sort Binary SearchPratibha BahugunaNo ratings yet
- Algorithm Array OperationsDocument7 pagesAlgorithm Array OperationsEr Natish KumarNo ratings yet
- Chapter TwoDocument30 pagesChapter TwoHASEN SEIDNo ratings yet
- Searching and SortingDocument30 pagesSearching and SortingBibekananda ShiNo ratings yet
- C++ Programs For Computer Science StudentsDocument75 pagesC++ Programs For Computer Science StudentsTanay MondalNo ratings yet
- Linear Arrays Representation & Traversal Insertion Deletion Linear Search Bubble Sort Binary SearchDocument18 pagesLinear Arrays Representation & Traversal Insertion Deletion Linear Search Bubble Sort Binary SearchAnanth KallamNo ratings yet
- Linear Arrays Representation & Traversal Insertion Deletion Linear Search Bubble Sort Binary SearchDocument18 pagesLinear Arrays Representation & Traversal Insertion Deletion Linear Search Bubble Sort Binary SearchAnanth KallamNo ratings yet
- SORTING METHODSDocument79 pagesSORTING METHODSKaran RoyNo ratings yet
- Chapter 3s ALGODocument11 pagesChapter 3s ALGOAbraham woldeNo ratings yet
- ArraysDocument22 pagesArraysAmisha SainiNo ratings yet
- Array Data Structure Lect-3Document16 pagesArray Data Structure Lect-3Tanmay BaranwalNo ratings yet
- Apex Institute of Technology Department: CseDocument16 pagesApex Institute of Technology Department: CseSheetu JainNo ratings yet
- CHAPTER-04(Searching&sorting) 1Document32 pagesCHAPTER-04(Searching&sorting) 1xx69dd69xxNo ratings yet
- DATA STRUCTURE Notes 2Document16 pagesDATA STRUCTURE Notes 2SamikshaNo ratings yet
- Unit 6 Sorting Algorithms Modified (1)Document46 pagesUnit 6 Sorting Algorithms Modified (1)nityamprakasharya123No ratings yet
- Linear Arrays: Memory Representation Traversal Insertion Deletion Linear Search Binary Search Merging 2D Array: Memory RepresentationDocument38 pagesLinear Arrays: Memory Representation Traversal Insertion Deletion Linear Search Binary Search Merging 2D Array: Memory RepresentationVinit KumarNo ratings yet
- Dsa Unit II NotesDocument26 pagesDsa Unit II NotesKadam SupriyaNo ratings yet
- DS&A-Chapter TwoDocument5 pagesDS&A-Chapter Twoeyobeshete01No ratings yet
- Array Data Structure LectureDocument30 pagesArray Data Structure LectureHafiz AhmedNo ratings yet
- AlgorithemChapter TwoDocument41 pagesAlgorithemChapter TwoOz GNo ratings yet
- Linear Arrays: Memory Representation Traversal Insertion Deletion Linear Search Binary Search Merging 2D Array: Memory RepresentationDocument34 pagesLinear Arrays: Memory Representation Traversal Insertion Deletion Linear Search Binary Search Merging 2D Array: Memory RepresentationKrishnaNo ratings yet
- Ds 2-ArraysDocument38 pagesDs 2-ArraysharryNo ratings yet
- Module5 DSADocument68 pagesModule5 DSAbarotshreedhar66No ratings yet
- Devide and Conqure RuleDocument11 pagesDevide and Conqure RuleAbhishek NandyNo ratings yet
- ArraysDocument23 pagesArraysshadowriser240No ratings yet
- Ds 2ArraysUpdatedDocument34 pagesDs 2ArraysUpdatednullaNo ratings yet
- Divide and Conquer Strategy for Computer AlgorithmsDocument85 pagesDivide and Conquer Strategy for Computer AlgorithmsMahesh PandeNo ratings yet
- Learn Linear and 2D Arrays with ExamplesDocument38 pagesLearn Linear and 2D Arrays with ExamplesVishwas KumarNo ratings yet
- Ch03 ChenDocument24 pagesCh03 ChenSri RNo ratings yet
- Final Algorithm Lab ManualDocument38 pagesFinal Algorithm Lab ManualMainak DeNo ratings yet
- Module Two DS NotesDocument18 pagesModule Two DS NotesVignesh C MNo ratings yet
- 3 ArraysDocument19 pages3 ArraysAmar ThakurNo ratings yet
- Daa Lab ManualDocument37 pagesDaa Lab ManualsridharNo ratings yet
- Data Structures: Linear ArraysDocument19 pagesData Structures: Linear ArraysKrishna sai ReddyNo ratings yet
- Chapter Three 3. Simple Sorting and Searching Algorithms 3.1. SearchingDocument15 pagesChapter Three 3. Simple Sorting and Searching Algorithms 3.1. SearchingGatlat Deng PuochNo ratings yet
- Data Structures: Linear ArraysDocument19 pagesData Structures: Linear ArraysRupendraNo ratings yet
- DS M5 Ktunotes - inDocument10 pagesDS M5 Ktunotes - inLoo OtNo ratings yet
- Lecture 31Document5 pagesLecture 31arjunNo ratings yet
- Algorithm ASSIGNMENT 1 Group 2Document6 pagesAlgorithm ASSIGNMENT 1 Group 2Jeff Mirondo KibalyaNo ratings yet
- DSD Unit 3 Sorting and SearchingDocument36 pagesDSD Unit 3 Sorting and SearchingK Poongodi Assistant Professor CSENo ratings yet
- DAA-Complete Buddha Series Unit-1 To 5Document126 pagesDAA-Complete Buddha Series Unit-1 To 5abcmsms432No ratings yet
- CORE - 14: Algorithm Design Techniques (Unit - 2)Document14 pagesCORE - 14: Algorithm Design Techniques (Unit - 2)Priyaranjan SorenNo ratings yet
- Simple Sorting and Searching Algorithms 2.1searching: PseudocodeDocument7 pagesSimple Sorting and Searching Algorithms 2.1searching: PseudocodebiniNo ratings yet
- Data Structure All AlgorithmDocument9 pagesData Structure All AlgorithmIzaz Uddin MahmudNo ratings yet
- Experiment No.02: Part ADocument7 pagesExperiment No.02: Part AanushkaNo ratings yet
- Merge Sort SeminarDocument22 pagesMerge Sort SeminarChaitanya BharadwajNo ratings yet
- Programming in C++ and Data Structures - 2Document1 pageProgramming in C++ and Data Structures - 2Karthikeyan RamajayamNo ratings yet
- Basic Arithmetic OperationsDocument1 pageBasic Arithmetic OperationsKarthikeyan RamajayamNo ratings yet
- Database Management Systems NotesDocument195 pagesDatabase Management Systems NotesAltafAhmed2706No ratings yet
- Unit 1Document89 pagesUnit 1Ashok Kumar KumaresanNo ratings yet
- Example Program 2 - Adding User Numbers Program: Code When Btnadd Is ClickedDocument2 pagesExample Program 2 - Adding User Numbers Program: Code When Btnadd Is ClickedKarthikeyan RamajayamNo ratings yet
- What Is A Database Management SystemDocument4 pagesWhat Is A Database Management SystemKarthikeyan RamajayamNo ratings yet
- Syllabus JavaDocument1 pageSyllabus JavaKarthikeyan RamajayamNo ratings yet
- Programming in C++ and Data Structures - 5Document1 pageProgramming in C++ and Data Structures - 5Karthikeyan RamajayamNo ratings yet
- Programming in C++ and Data Structures - 1Document2 pagesProgramming in C++ and Data Structures - 1Karthikeyan RamajayamNo ratings yet
- Factors in RDocument6 pagesFactors in RKarthikeyan RamajayamNo ratings yet
- Artificial Intelligence Notes PDFDocument2 pagesArtificial Intelligence Notes PDFKarthikeyan Ramajayam100% (2)
- Iteration - Condition Controlled: WHILE LoopsDocument3 pagesIteration - Condition Controlled: WHILE LoopsKarthikeyan RamajayamNo ratings yet
- Multiplexing in Mobile ComputingDocument5 pagesMultiplexing in Mobile ComputingKarthikeyan RamajayamNo ratings yet
- DMDocument3 pagesDMKarthikeyan RamajayamNo ratings yet
- Calculations With VectorsDocument6 pagesCalculations With VectorsKarthikeyan RamajayamNo ratings yet
- Basic Arithmetic FunctionsDocument7 pagesBasic Arithmetic FunctionsKarthikeyan RamajayamNo ratings yet
- Example Program 1 VBDocument2 pagesExample Program 1 VBKarthikeyan RamajayamNo ratings yet
- Data Flow Diagra1Document3 pagesData Flow Diagra1Karthikeyan RamajayamNo ratings yet
- Difference Between VB and VBDocument2 pagesDifference Between VB and VBKarthikeyan RamajayamNo ratings yet
- vb.netDocument2 pagesvb.netKarthikeyan RamajayamNo ratings yet
- Example program checks capital city of England is LondonDocument2 pagesExample program checks capital city of England is LondonKarthikeyan RamajayamNo ratings yet
- Example 4 - Finding The Average of Numbers in A ListDocument2 pagesExample 4 - Finding The Average of Numbers in A ListKarthikeyan RamajayamNo ratings yet
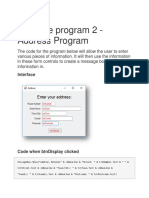
- Example Program 2 - Address Program: InterfaceDocument6 pagesExample Program 2 - Address Program: InterfaceKarthikeyan RamajayamNo ratings yet
- Difference Between VB and VBDocument2 pagesDifference Between VB and VBKarthikeyan RamajayamNo ratings yet
- Introduction To AspDocument1 pageIntroduction To AspKarthikeyan RamajayamNo ratings yet
- Introduction To AspDocument1 pageIntroduction To AspKarthikeyan RamajayamNo ratings yet
- Keel User ManualDocument26 pagesKeel User ManualKarthikeyan RamajayamNo ratings yet
- CLS Specification Ensures .NET InteroperabilityDocument2 pagesCLS Specification Ensures .NET InteroperabilityKarthikeyan RamajayamNo ratings yet
- Data Flow Diagra1Document3 pagesData Flow Diagra1Karthikeyan RamajayamNo ratings yet
- Dot Net2Document1 pageDot Net2Karthikeyan RamajayamNo ratings yet
- Hotel Management Project Report AnalysisDocument149 pagesHotel Management Project Report AnalysisRayat ComputerNo ratings yet
- Zaheer PC4Document66 pagesZaheer PC4Dr. Zaheer AliNo ratings yet
- Chapter 2 SlidesDocument66 pagesChapter 2 SlidesHeriansyah NajemiNo ratings yet
- Product Guide: Clipsal C-BusDocument76 pagesProduct Guide: Clipsal C-BusGokul KrishnanNo ratings yet
- Experiment No 6Document11 pagesExperiment No 6Aman JainNo ratings yet
- USM v5 Deployment GuideDocument186 pagesUSM v5 Deployment GuideAnonymous P96rcQILNo ratings yet
- Final Project Report V4 - 1Document42 pagesFinal Project Report V4 - 1Preeti ShresthaNo ratings yet
- Partition and Format a Disk in LinuxDocument13 pagesPartition and Format a Disk in LinuxfopataNo ratings yet
- Resume Syed Faisal LatifDocument4 pagesResume Syed Faisal Latifkenshin uraharaNo ratings yet
- Indoor lighting design concepts for a concert hallDocument145 pagesIndoor lighting design concepts for a concert hallknl83% (6)
- Gaussian ManualDocument59 pagesGaussian ManualIsmail Adewale OlumegbonNo ratings yet
- Schneider Electric ATV312HU40N4 DatasheetDocument3 pagesSchneider Electric ATV312HU40N4 DatasheetMagda DiazNo ratings yet
- Core Java: - Sharad BallepuDocument56 pagesCore Java: - Sharad BallepuyacobaschalewNo ratings yet
- MTK Atcmd SetDocument140 pagesMTK Atcmd Setmarcosr800100% (3)
- Iv7 Rfid Vehicle Reader Data Sheet enDocument2 pagesIv7 Rfid Vehicle Reader Data Sheet enMArceloNo ratings yet
- Avijit Sood: BackgroundDocument7 pagesAvijit Sood: BackgroundAshwani kumarNo ratings yet
- Eric II The Encyclopedia of Roman Imperial Coins PDFDocument2 pagesEric II The Encyclopedia of Roman Imperial Coins PDFNicoleNo ratings yet
- Lesson 1Document31 pagesLesson 1Alice Jane RAMA LagsaNo ratings yet
- 91 of The Cutest Puppies Ever Bored PandaDocument2 pages91 of The Cutest Puppies Ever Bored PandaVenera GolubinaNo ratings yet
- Steam CMDDocument20 pagesSteam CMDRaven HeartNo ratings yet
- Kali AssigmentDocument17 pagesKali Assigmentkounglay mmtNo ratings yet
- Flow Indicator Totaliser PDFDocument2 pagesFlow Indicator Totaliser PDFKARAN SAXENANo ratings yet
- It6006 Da Iq Nov - Dec 2018 RejinpaulDocument1 pageIt6006 Da Iq Nov - Dec 2018 RejinpaulVanathi AnandavelNo ratings yet
- Windows Server 2016 Automation With Powershell CookbookDocument651 pagesWindows Server 2016 Automation With Powershell CookbookGaurav Nayak100% (1)
- SafeQ4 - Quick Start GuideDocument21 pagesSafeQ4 - Quick Start GuideLuki LeviNo ratings yet
- Web-Based Patient Information System for Posyandu at Kalimas PoskesdesDocument10 pagesWeb-Based Patient Information System for Posyandu at Kalimas Poskesdes1/C Amellinda Anisa MarselNo ratings yet
- M-DRO PC Digital Readout Interface: Technical InformationDocument20 pagesM-DRO PC Digital Readout Interface: Technical InformationCarlos Gabriel EstergaardNo ratings yet
- Lab - 2: Linux Installation:: Basic TerminologiesDocument6 pagesLab - 2: Linux Installation:: Basic TerminologiesSikandar KhanNo ratings yet
- 12 CS Practical 1 To 5 Oct2022Document6 pages12 CS Practical 1 To 5 Oct2022Priyesh KumarNo ratings yet
- 9.1.1.6 Lab - Encrypting and Decrypting Data Using OpenSSLDocument3 pages9.1.1.6 Lab - Encrypting and Decrypting Data Using OpenSSLBrian HarefaNo ratings yet