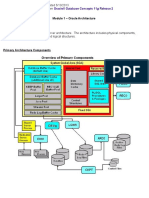
You might also like
- ORACLE DBMS MANAGES DATADocument127 pagesORACLE DBMS MANAGES DATAsoireeNo ratings yet
- Chapter01 Oracle ArchitectureDocument42 pagesChapter01 Oracle ArchitectureOscar RiveraNo ratings yet
- PEM Executive SummaryDocument11 pagesPEM Executive SummaryJvr SubramaniaraajaaNo ratings yet
- Oracle8i Architecture OverviewDocument30 pagesOracle8i Architecture OverviewJesus MartinezNo ratings yet
- 10G ConceptsDocument4 pages10G Conceptssrini6886dbaNo ratings yet
- Oracle Database Architecture OverviewDocument49 pagesOracle Database Architecture OverviewSraVanKuMarThadakamallaNo ratings yet
- Introducing Oracle8: New Features of Oracle8Document22 pagesIntroducing Oracle8: New Features of Oracle8Arsalan AhmedNo ratings yet
- ÷y ÷y ÷y ÷y ÷yDocument20 pages÷y ÷y ÷y ÷y ÷ydbareddyNo ratings yet
- Instance: What Is An Oracle Database?Document7 pagesInstance: What Is An Oracle Database?Vinay GoddemmeNo ratings yet
- Pca15E04 Database Administration Unit-2Document11 pagesPca15E04 Database Administration Unit-2Mohammed AlramadiNo ratings yet
- DBA Interview QuestionsDocument19 pagesDBA Interview QuestionssiganNo ratings yet
- Oracle SM IDocument388 pagesOracle SM ITanmoy NandyNo ratings yet
- Oracle Database Architecture OverviewDocument24 pagesOracle Database Architecture OverviewSuneel KumarNo ratings yet
- Racle G Rchitecture With Iagram: U N: 3 N Oracle 11g New FeaturesDocument14 pagesRacle G Rchitecture With Iagram: U N: 3 N Oracle 11g New FeaturesThirumal VankamNo ratings yet
- Arch 2Document3 pagesArch 2anjandbaNo ratings yet
- Initialization and Data Files in Oracle DatabaseDocument6 pagesInitialization and Data Files in Oracle Databasezaiby5No ratings yet
- Oracle Book-Final FormattedDocument168 pagesOracle Book-Final Formattedkranthi633100% (1)
- Module 1 - Oracle Architecture: ObjectivesDocument64 pagesModule 1 - Oracle Architecture: Objectivesshaikali1980No ratings yet
- Module 1 - Oracle ArchitectureDocument34 pagesModule 1 - Oracle ArchitectureGautam TrivediNo ratings yet
- Creation Instance OracleDocument3 pagesCreation Instance OraclebedorlehackerNo ratings yet
- Database Architecture Oracle DbaDocument41 pagesDatabase Architecture Oracle DbaImran ShaikhNo ratings yet
- 1.0 Introduction To The Oracle Database: ServerDocument3 pages1.0 Introduction To The Oracle Database: ServerKumarNo ratings yet
- Oracle8i On Windows NT/2000: Architecture, Scalability, and TuningDocument19 pagesOracle8i On Windows NT/2000: Architecture, Scalability, and TuningtanveerwajidNo ratings yet
- Business Objects OracleDocument3 pagesBusiness Objects OraclebedorlehackerNo ratings yet
- Oracle File TypesDocument2 pagesOracle File TypesAtthulaiNo ratings yet
- Module 1 - Oracle ArchitectureDocument33 pagesModule 1 - Oracle ArchitectureDivya SrinivasanNo ratings yet
- Study Material For OracleDocument198 pagesStudy Material For OracleSarath ChandraNo ratings yet
- Study Material For OracleDocument197 pagesStudy Material For OracleSidharth SontiNo ratings yet
- Oracle 10g Material Final 1Document143 pagesOracle 10g Material Final 1mohammad_rahman147No ratings yet
- About Files in Data BasdeDocument41 pagesAbout Files in Data BasdePILLINAGARAJUNo ratings yet
- Oracle TutorialDocument53 pagesOracle TutorialLalit ShaktawatNo ratings yet
- Ora 2Document3 pagesOra 2jey hNo ratings yet
- Oracle QuestionsDocument56 pagesOracle QuestionsMadjid MansouriNo ratings yet
- Database NotesDocument31 pagesDatabase NotesSaad QaisarNo ratings yet
- Chapter01 Oracle ArchitectureDocument42 pagesChapter01 Oracle ArchitecturehenaediNo ratings yet
- Introduction To The Oracle Server: It Includes The FollowingDocument11 pagesIntroduction To The Oracle Server: It Includes The FollowingRishabh BhagatNo ratings yet
- Oracle Database Architecture: Product Alliance GroupDocument53 pagesOracle Database Architecture: Product Alliance GrouppranayusinNo ratings yet
- Module 1 - Oracle ArchitectureDocument110 pagesModule 1 - Oracle ArchitectureKranthi KumarNo ratings yet
- Interview Questions For Oracle DbaDocument23 pagesInterview Questions For Oracle DbadarrelgonsalvesNo ratings yet
- Oracle 10g Material FinalDocument145 pagesOracle 10g Material FinalidealbloomsNo ratings yet
- Starting Database Administration: Oracle DBAFrom EverandStarting Database Administration: Oracle DBARating: 3 out of 5 stars3/5 (2)
- Oracle St04Document9 pagesOracle St04khaled_dudeNo ratings yet
- 3 Oracle Architecture NotesDocument39 pages3 Oracle Architecture NotesPaul NikolaidisNo ratings yet
- (SQL) Oracle StreamDocument199 pages(SQL) Oracle StreamHarish KumarNo ratings yet
- Process Architecture: Open, Comprehensive, and Integrated Approach To Information Management. An OracleDocument13 pagesProcess Architecture: Open, Comprehensive, and Integrated Approach To Information Management. An OraclevishwasdeshkarNo ratings yet
- The Basics of Oracle ArchitectureDocument5 pagesThe Basics of Oracle Architecturebhuvan_boseNo ratings yet
- Group Application-Related Data Together in Single TablespaceDocument8 pagesGroup Application-Related Data Together in Single TablespaceMr. noneNo ratings yet
- Basics of The Oracle Database ArchitectureDocument56 pagesBasics of The Oracle Database Architecturevidhi hinguNo ratings yet
- Chapter6 Database ArchitectureDocument56 pagesChapter6 Database ArchitectureMohammed AlramadiNo ratings yet
- Module 1 - Oracle Architecture: ObjectivesDocument41 pagesModule 1 - Oracle Architecture: ObjectivesNavneet SainiNo ratings yet
- Lu2 Lo4Document32 pagesLu2 Lo4samuel yitakubayoNo ratings yet
- Understanding Operating System ResourcesDocument11 pagesUnderstanding Operating System ResourcesNooraFukuzawa NorNo ratings yet
- Shell ScriptingDocument13 pagesShell ScriptingatifhassansiddiquiNo ratings yet
- Oracle Architecture BasicsDocument5 pagesOracle Architecture Basicschetanb39No ratings yet
- Alter Database Backup Controlfile To Trace - PM-DB PDFDocument3 pagesAlter Database Backup Controlfile To Trace - PM-DB PDFChander ShekharNo ratings yet
- Close: Lascon Storage BackupsDocument3 pagesClose: Lascon Storage BackupsAtthulaiNo ratings yet
- Module 1 - Oracle ArchitectureDocument34 pagesModule 1 - Oracle ArchitecturePratik Gandhi100% (1)
- Oracle Interview QuestionDocument87 pagesOracle Interview QuestionfahdaizazNo ratings yet
- Grade-2 IDP 2023 NewDocument7 pagesGrade-2 IDP 2023 Newanilp20055148No ratings yet
- Oracle Backup and Recovery: An Oracle Technical White Paper February 1999Document33 pagesOracle Backup and Recovery: An Oracle Technical White Paper February 1999pratyush_mathurNo ratings yet
- Unix CommandsDocument8 pagesUnix Commandsrithika14No ratings yet
- Recovering A Database: Requiring RecoveryDocument20 pagesRecovering A Database: Requiring Recoverylokeshchennam1No ratings yet
- h4585 Sourceone Email MGMT DsDocument3 pagesh4585 Sourceone Email MGMT Dsraa96No ratings yet
- Chapter 25Document16 pagesChapter 25anilp20055148No ratings yet
- 30 Unix PDFDocument6 pages30 Unix PDFRavitej TadinadaNo ratings yet
- h4927 Emc Documentum Physical Records Services Ds PDFDocument2 pagesh4927 Emc Documentum Physical Records Services Ds PDFanilp20055148No ratings yet
- Upstart Cookbook PDFDocument104 pagesUpstart Cookbook PDFanilp20055148No ratings yet
- PLSQL TutorialDocument128 pagesPLSQL TutorialkhanarmanNo ratings yet
- Chapter 16Document30 pagesChapter 16anilp20055148No ratings yet
- Chapter 14Document18 pagesChapter 14anilp20055148No ratings yet
- Chapter 12Document24 pagesChapter 12anilp20055148No ratings yet
- Chapter 20Document20 pagesChapter 20anilp20055148No ratings yet
- Chapter 30Document30 pagesChapter 30anilp20055148No ratings yet
- Chapter 25Document16 pagesChapter 25anilp20055148No ratings yet
- Tun1 Statspack3Document10 pagesTun1 Statspack3anilp20055148No ratings yet
- Chapter 07Document30 pagesChapter 07anilp200551480% (1)
- Tun1 Statspack2Document7 pagesTun1 Statspack2anilp20055148No ratings yet
- Tun1 Statspack1Document8 pagesTun1 Statspack1anilp20055148No ratings yet
- 9i Lin RelnotesDocument16 pages9i Lin Relnotesanilp20055148No ratings yet
- DBA Cirtf.Document27 pagesDBA Cirtf.anilp20055148No ratings yet
- 8I Recovery ManagerDocument11 pages8I Recovery Manageranilp20055148No ratings yet
- Oracle Advanced Security New Features Oracle8i Release 8.1.6Document8 pagesOracle Advanced Security New Features Oracle8i Release 8.1.6anilp20055148No ratings yet
- 9i HP RelnotesDocument12 pages9i HP Relnotesanilp20055148No ratings yet
- 8I Index TablesDocument9 pages8I Index Tablesanilp20055148No ratings yet
- Beg1 SqlplusDocument12 pagesBeg1 Sqlplusanilp20055148No ratings yet
- 8I Locally MGR TBSPDocument4 pages8I Locally MGR TBSPanilp20055148No ratings yet
- 8I Internet SecurityDocument15 pages8I Internet Securityanilp20055148No ratings yet
- Red Hat Enterprise Linux-5-SystemTap Beginners Guide-En-USDocument76 pagesRed Hat Enterprise Linux-5-SystemTap Beginners Guide-En-USBuland Kumar SinghNo ratings yet
- Validus Fintech - Service Order FormDocument4 pagesValidus Fintech - Service Order FormAnuragNo ratings yet
- Test Suite Generation With Memetic Algorithms: Gordon Fraser Andrea Arcuri Phil McminnDocument8 pagesTest Suite Generation With Memetic Algorithms: Gordon Fraser Andrea Arcuri Phil McminnJatin GeraNo ratings yet
- fx-CG50 Soft EN PDFDocument662 pagesfx-CG50 Soft EN PDFSaksham RanjanNo ratings yet
- A Brief History of Early ComputersDocument5 pagesA Brief History of Early ComputersRuth AsterNo ratings yet
- Navigation & SelectionDocument2 pagesNavigation & SelectionPranayNo ratings yet
- Anti-Theft Security System Using Face Recognition Thesis Report by Chong Guan YuDocument76 pagesAnti-Theft Security System Using Face Recognition Thesis Report by Chong Guan Yuakinlabi aderibigbeNo ratings yet
- BSNL Gujarat Telecom Circle..Document2 pagesBSNL Gujarat Telecom Circle..ggtgtretNo ratings yet
- Thread BasicsDocument20 pagesThread Basicskhoaitayran2012_4950No ratings yet
- SliceViewer and VoxelViewer - enDocument55 pagesSliceViewer and VoxelViewer - enemadhsobhyNo ratings yet
- Gadget Comparison - Mi 1c - 02 - Ahmad Ridlo Suhardi#14 - Gita Kartika Pariwara#21 - Putri Dian IstianaDocument8 pagesGadget Comparison - Mi 1c - 02 - Ahmad Ridlo Suhardi#14 - Gita Kartika Pariwara#21 - Putri Dian IstianaGita Kartika PariwaraNo ratings yet
- A Doubly Linked Circular ListDocument7 pagesA Doubly Linked Circular Listkhawar abbasiNo ratings yet
- Window Air ConditionerDocument8 pagesWindow Air ConditionerHimanshu UpadhyayNo ratings yet
- CSC 215 Assembly Language Programming-1Document63 pagesCSC 215 Assembly Language Programming-1Omodunni DanielNo ratings yet
- Resume Syed Faisal LatifDocument4 pagesResume Syed Faisal Latifkenshin uraharaNo ratings yet
- Bio-Medical Engineer C.VDocument4 pagesBio-Medical Engineer C.Veng_aymanhamdan80% (5)
- Software UsageDocument1 pageSoftware UsageAshish BagariaNo ratings yet
- Plasma Donation System: A Project OnDocument29 pagesPlasma Donation System: A Project OnArshiya Mobile ShopeeNo ratings yet
- A Raspberry Pi NAS That Really Look Like A NASDocument11 pagesA Raspberry Pi NAS That Really Look Like A NASvespoNo ratings yet
- Network Software-: Types of Communication SoftwareDocument10 pagesNetwork Software-: Types of Communication SoftwaredavidNo ratings yet
- OopsDocument305 pagesOopsKartikNo ratings yet
- Fire Alarm: HarringtonDocument4 pagesFire Alarm: HarringtonNacho Vega SanchezNo ratings yet
- Aplikasi e-Modul Berbasis Android dalam Mata Pelajaran Administrasi Sistem JaringanDocument6 pagesAplikasi e-Modul Berbasis Android dalam Mata Pelajaran Administrasi Sistem JaringanEksi UmayaniNo ratings yet
- Windows Server 2016 Automation With Powershell CookbookDocument651 pagesWindows Server 2016 Automation With Powershell CookbookGaurav Nayak100% (1)
- Railway Reservation Oops ProjectDocument24 pagesRailway Reservation Oops ProjectShamil IqbalNo ratings yet
- EJ Unit 4Document39 pagesEJ Unit 4Yexo KajNo ratings yet
- Os ND06Document3 pagesOs ND06kevinbtechNo ratings yet
- AutoCAD Command ShortcutsDocument13 pagesAutoCAD Command ShortcutsMandel Battikin Gup-ayNo ratings yet
- Anindita Bhowmick ProfileDocument2 pagesAnindita Bhowmick ProfileNHNNo ratings yet