You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- 6th GATEDocument33 pages6th GATESamejiel Aseviel LajesielNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Tchaikovsky Piano Concerto 1Document2 pagesTchaikovsky Piano Concerto 1arno9bear100% (2)
- Present Perfect.Document1 pagePresent Perfect.Leidy DiazNo ratings yet
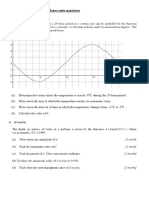
- Sine and Cosine Exam QuestionsDocument8 pagesSine and Cosine Exam QuestionsGamer Shabs100% (1)
- P-H Agua PDFDocument1 pageP-H Agua PDFSarah B. LopesNo ratings yet
- Mid Term Business Economy - Ayustina GiustiDocument9 pagesMid Term Business Economy - Ayustina GiustiAyustina Giusti100% (1)
- Antarctica Can Give A MonopolyDocument6 pagesAntarctica Can Give A MonopolyFilip DukicNo ratings yet
- Polygon shapes solve complex mechanical problemsDocument6 pagesPolygon shapes solve complex mechanical problemskristoffer_mosshedenNo ratings yet
- Guidelines To MAS Notice 626 April 2015Document62 pagesGuidelines To MAS Notice 626 April 2015Wr OngNo ratings yet
- Importance of Geometric DesignDocument10 pagesImportance of Geometric DesignSarfaraz AhmedNo ratings yet
- Pirates and Privateers of the Caribbean: A Guide to the GameDocument25 pagesPirates and Privateers of the Caribbean: A Guide to the GameLunargypsyNo ratings yet
- Bylaw 16232 High Park RezoningDocument9 pagesBylaw 16232 High Park RezoningJamie_PostNo ratings yet
- How To Retract BPS Data Back To R3 When There Is No Standard RetractorDocument3 pagesHow To Retract BPS Data Back To R3 When There Is No Standard Retractorraphavega2010No ratings yet
- 2018 JC2 H2 Maths SA2 River Valley High SchoolDocument50 pages2018 JC2 H2 Maths SA2 River Valley High SchoolZtolenstarNo ratings yet
- Lab 1 Boys CalorimeterDocument11 pagesLab 1 Boys CalorimeterHafizszul Feyzul100% (1)
- 2004 Canon Bino BrochureDocument6 pages2004 Canon Bino BrochureCraig ThompsonNo ratings yet
- 2-STM Answers SokhaDocument6 pages2-STM Answers SokhamenghokcNo ratings yet
- Strategic Marketing FiguresDocument34 pagesStrategic Marketing FiguresphuongmonNo ratings yet
- JE Creation Using F0911MBFDocument10 pagesJE Creation Using F0911MBFShekar RoyalNo ratings yet
- Applied SciencesDocument25 pagesApplied SciencesMario BarbarossaNo ratings yet
- PENGARUH CYBERBULLYING BODY SHAMING TERHADAP KEPERCAYAAN DIRIDocument15 pagesPENGARUH CYBERBULLYING BODY SHAMING TERHADAP KEPERCAYAAN DIRIRizky Hizrah WumuNo ratings yet
- CSIR AnalysisDocument1 pageCSIR Analysisசெபா செல்வாNo ratings yet
- Teaching and Learning in the Multigrade ClassroomDocument18 pagesTeaching and Learning in the Multigrade ClassroomMasitah Binti TaibNo ratings yet
- BS en 1044-1999 - Brazing Filler MetalsDocument26 pagesBS en 1044-1999 - Brazing Filler MetalsBorn ToSinNo ratings yet
- Bond Strength of Normal-to-Lightweight Concrete InterfacesDocument9 pagesBond Strength of Normal-to-Lightweight Concrete InterfacesStefania RinaldiNo ratings yet
- Huawei Switch S5700 How ToDocument10 pagesHuawei Switch S5700 How ToJeanNo ratings yet
- jk2 JAVADocument57 pagesjk2 JAVAAndi FadhillahNo ratings yet
- List of OperationsDocument3 pagesList of OperationsGibs_9122100% (3)
- NYU Stern Evaluation NewsletterDocument25 pagesNYU Stern Evaluation NewsletterCanadianValueNo ratings yet
- Dinflo DFCSDocument2 pagesDinflo DFCSvictorharijantoNo ratings yet