You might also like
- Linear Alg NotesDocument4 pagesLinear Alg NotesCathy DengNo ratings yet
- Notes On Matric AlgebraDocument11 pagesNotes On Matric AlgebraMaesha ArmeenNo ratings yet
- Appendix and IndexDocument104 pagesAppendix and IndexkankirajeshNo ratings yet
- Introduction To Matrices: 2.14 Analysis and Design of Feedback Control SystemsDocument9 pagesIntroduction To Matrices: 2.14 Analysis and Design of Feedback Control Systemsberndjulie726No ratings yet
- MGMT 221, Ch. IIDocument33 pagesMGMT 221, Ch. IIMulugeta Girma67% (6)
- 5 System of Linear EquationDocument12 pages5 System of Linear EquationAl Asad Nur RiyadNo ratings yet
- MatricesDocument14 pagesMatricesthinkiitNo ratings yet
- Reminding Matrices and DeterminantsDocument6 pagesReminding Matrices and DeterminantsFredrick MutungaNo ratings yet
- Algebra MatricialDocument17 pagesAlgebra MatricialjoelmulatosanchezNo ratings yet
- Matrix Algebra ReviewDocument12 pagesMatrix Algebra ReviewLeo TeruelNo ratings yet
- Matrix Mathematics: AppendixDocument9 pagesMatrix Mathematics: AppendixBright MuzaNo ratings yet
- Matrices and Linear AlgebraDocument13 pagesMatrices and Linear AlgebraRaulNo ratings yet
- Maths 2 For Eng - Lesson 1Document9 pagesMaths 2 For Eng - Lesson 1Abdulkader TukaleNo ratings yet
- NA 5 LatexDocument45 pagesNA 5 LatexpanmergeNo ratings yet
- Appendix: Fundamentals of MatricesDocument6 pagesAppendix: Fundamentals of MatricessarwankumarpalNo ratings yet
- matrixAlgebraReview PDFDocument16 pagesmatrixAlgebraReview PDFRocket FireNo ratings yet
- DeterminantDocument14 pagesDeterminantNindya SulistyaniNo ratings yet
- Matrices and Determinants: Ij Ij Ij Ij IjDocument23 pagesMatrices and Determinants: Ij Ij Ij Ij Ijumeshmalla2006No ratings yet
- Mathematics II-matricesDocument52 pagesMathematics II-matricesBagus RizalNo ratings yet
- Chapter OneDocument14 pagesChapter OneBiruk YidnekachewNo ratings yet
- 1 Topics in Linear AlgebraDocument42 pages1 Topics in Linear AlgebraArlene DaroNo ratings yet
- "Just The Maths" Unit Number 9.1 Matrices 1 (Definitions & Elementary Matrix Algebra) by A.J.HobsonDocument9 pages"Just The Maths" Unit Number 9.1 Matrices 1 (Definitions & Elementary Matrix Algebra) by A.J.HobsonMayank SanNo ratings yet
- Introduction To Financial Econometrics Appendix Matrix Algebra ReviewDocument8 pagesIntroduction To Financial Econometrics Appendix Matrix Algebra ReviewKalijorne MicheleNo ratings yet
- Systems and MatricesDocument15 pagesSystems and MatricesTom DavisNo ratings yet
- NC 10Document12 pagesNC 10Hamid RehmanNo ratings yet
- Things To Know PDFDocument7 pagesThings To Know PDFJohn ChenNo ratings yet
- Math Majorship LinearDocument12 pagesMath Majorship LinearMaybelene NavaresNo ratings yet
- WIN (2019-20) MAT1002 ETH AP2019205000028 Reference Material I Application of ODE PDFDocument177 pagesWIN (2019-20) MAT1002 ETH AP2019205000028 Reference Material I Application of ODE PDFEswar RcfNo ratings yet
- 300 MatricesDocument11 pages300 MatricesXacoScribdNo ratings yet
- Untitled 2Document81 pagesUntitled 2JEAN KATHLEEN SORIANONo ratings yet
- Chapter 26 - Remainder - A4Document9 pagesChapter 26 - Remainder - A4GabrielPaintingsNo ratings yet
- 2.7.3 Example: 2.2 Matrix AlgebraDocument8 pages2.7.3 Example: 2.2 Matrix Algebrafredy8704No ratings yet
- Arrays and MatricesDocument43 pagesArrays and MatricesMarian CelesteNo ratings yet
- Related Topics of Matrix Theory: Appendix EDocument5 pagesRelated Topics of Matrix Theory: Appendix EAwais HassanNo ratings yet
- 8 Sistem Persamaan Linier SPLDocument20 pages8 Sistem Persamaan Linier SPLIgor M FarhanNo ratings yet
- Mathematics (Introduction To Linear Algebra)Document36 pagesMathematics (Introduction To Linear Algebra)shilpajosephNo ratings yet
- Algebra of MatrixDocument14 pagesAlgebra of MatrixRajeenaNayimNo ratings yet
- Matrix NotesDocument23 pagesMatrix NotespsnspkNo ratings yet
- Chapter 6Document20 pagesChapter 6Shimeque SmithNo ratings yet
- Numerical Methods 6Document45 pagesNumerical Methods 6Olga Diokta FerinnandaNo ratings yet
- Appendix C - Review of Linear Algebra and R - 2006 - Numerical Methods in BiomedDocument9 pagesAppendix C - Review of Linear Algebra and R - 2006 - Numerical Methods in BiomedTonny HiiNo ratings yet
- A Second Course in Elementary Differential EquationsDocument210 pagesA Second Course in Elementary Differential EquationsMechanicals1956No ratings yet
- GEM 802 Chapter 1Document52 pagesGEM 802 Chapter 1Leah Ann ManuelNo ratings yet
- MM2 Linear Algebra 2011 I 1x2Document33 pagesMM2 Linear Algebra 2011 I 1x2Aaron LeeNo ratings yet
- Tea Lec NoteDocument27 pagesTea Lec NoteAlex OrtegaNo ratings yet
- Linear Algebra SolutionsDocument22 pagesLinear Algebra Solutionsjaspreet_xps0% (1)
- Linear Algebra 24 - PDFDocument97 pagesLinear Algebra 24 - PDFnurullah_bulutNo ratings yet
- Linear Algebra - Module 1Document52 pagesLinear Algebra - Module 1TestNo ratings yet
- Matrix Algebra ReviewDocument16 pagesMatrix Algebra ReviewGourav GuptaNo ratings yet
- 1 Linear AlgebraDocument5 pages1 Linear AlgebraSonali VasisthaNo ratings yet
- Notes of AlgebraDocument6 pagesNotes of AlgebraSherif El-soudyNo ratings yet
- Chapter 3 Lae1Document27 pagesChapter 3 Lae1razlan ghazaliNo ratings yet
- Chapter 15 Linear AlgebraDocument59 pagesChapter 15 Linear AlgebraAk ChintuNo ratings yet
- Usme, Dtu Project On Matrices and Determinants Analysis BY Bharat Saini Tanmay ChhikaraDocument17 pagesUsme, Dtu Project On Matrices and Determinants Analysis BY Bharat Saini Tanmay ChhikaraTanmay ChhikaraNo ratings yet
- Mce371 13Document19 pagesMce371 13Abul HasnatNo ratings yet
- Various Types of Matrices: DeterminantDocument5 pagesVarious Types of Matrices: DeterminantFarid HossainNo ratings yet
- MatricesDocument2 pagesMatricesSanjoy BrahmaNo ratings yet
- Chapter 10 Matrices and Determinants: AlgebraDocument15 pagesChapter 10 Matrices and Determinants: AlgebraDinesh KumarNo ratings yet
- Ls. Linear SystemsDocument6 pagesLs. Linear SystemsZubinJainNo ratings yet
- Sample Business Valuation - BAGDocument43 pagesSample Business Valuation - BAGjeygar12No ratings yet
- Reset Mysql Pass Ow RD MacDocument1 pageReset Mysql Pass Ow RD Macjeygar12No ratings yet
- Energy BalanceDocument31 pagesEnergy BalanceabdulqaderNo ratings yet
- 1 6javaDocument1 page1 6javajeygar12No ratings yet
- Case Studies On Optimum Reflux Ratio of Distillation Towers in Petroleum Refining ProcessesDocument6 pagesCase Studies On Optimum Reflux Ratio of Distillation Towers in Petroleum Refining ProcessesMcChima LeonardNo ratings yet
- Ethyleneglycol Design 2520of 2520equipmentsDocument41 pagesEthyleneglycol Design 2520of 2520equipmentsHardik Gandhi100% (1)
- Optimisation & Decision Making ENGM072: Dr. Franjo CeceljaDocument26 pagesOptimisation & Decision Making ENGM072: Dr. Franjo Ceceljajeygar12No ratings yet
- Lecture - 3 SolarDocument87 pagesLecture - 3 Solarjeygar12No ratings yet
- MLU Spec Sheet 250W 255WDocument2 pagesMLU Spec Sheet 250W 255Wjeygar12No ratings yet
- Optimisation & Decision Making ENGM072: Dr. Franjo CeceljaDocument26 pagesOptimisation & Decision Making ENGM072: Dr. Franjo Ceceljajeygar12No ratings yet
- Optimisation ProblemDocument2 pagesOptimisation Problemjeygar12No ratings yet
- Biodiesel ReviewDocument15 pagesBiodiesel ReviewelizabethvperezNo ratings yet
- Hydro ProcessingDocument24 pagesHydro Processingjeygar12No ratings yet
- Catalytic CrackingDocument43 pagesCatalytic Crackingjeygar12100% (2)
- CG ThesisDocument239 pagesCG Thesisjeygar12No ratings yet
- Fawley 2011 PDFDocument14 pagesFawley 2011 PDFjeygar12No ratings yet
- PDFDocument27 pagesPDFjeygar12No ratings yet
- Numerical Solution of Differential Algebraic Equations PDFDocument109 pagesNumerical Solution of Differential Algebraic Equations PDFjeygar12No ratings yet
- Solar Hot Water SystemsDocument5 pagesSolar Hot Water SystemsMariam AnsariNo ratings yet
- Process Modelling and Simulation Chapter 6 Soln Strategies For Lumped Parameter ModelDocument33 pagesProcess Modelling and Simulation Chapter 6 Soln Strategies For Lumped Parameter Modeljeygar12No ratings yet
- Fortigate Firewall Version 4 OSDocument122 pagesFortigate Firewall Version 4 OSSam Mani Jacob DNo ratings yet
- Sales Forecast Template DownloadDocument9 pagesSales Forecast Template DownloadAshokNo ratings yet
- Existentialism in LiteratureDocument2 pagesExistentialism in LiteratureGirlhappy Romy100% (1)
- Operations Management Interim ProjectDocument4 pagesOperations Management Interim ProjectABAYANKAR SRIRAM (RA1931201020042)No ratings yet
- EP001 LifeCoachSchoolTranscriptDocument13 pagesEP001 LifeCoachSchoolTranscriptVan GuedesNo ratings yet
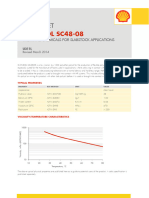
- Caradol sc48 08Document2 pagesCaradol sc48 08GİZEM DEMİRNo ratings yet
- DAA UNIT 1 - FinalDocument38 pagesDAA UNIT 1 - FinalkarthickamsecNo ratings yet
- B. Pengenalan Kepada Pengawal Mikro 1. Mengenali Sistem Yang Berasaskan Pengawal MikroDocument4 pagesB. Pengenalan Kepada Pengawal Mikro 1. Mengenali Sistem Yang Berasaskan Pengawal MikroSyamsul IsmailNo ratings yet
- Internship Format HRMI620Document4 pagesInternship Format HRMI620nimra tariqNo ratings yet
- Coal Bottom Ash As Sand Replacement in ConcreteDocument9 pagesCoal Bottom Ash As Sand Replacement in ConcretexxqNo ratings yet
- Art of War Day TradingDocument17 pagesArt of War Day TradingChrispen MoyoNo ratings yet
- Beyond Models and Metaphors Complexity Theory, Systems Thinking and - Bousquet & CurtisDocument21 pagesBeyond Models and Metaphors Complexity Theory, Systems Thinking and - Bousquet & CurtisEra B. LargisNo ratings yet
- Rishika Reddy Art Integrated ActivityDocument11 pagesRishika Reddy Art Integrated ActivityRishika ReddyNo ratings yet
- ETNOBotanica NombresDocument188 pagesETNOBotanica Nombresjalepa_esNo ratings yet
- Boarding House Preferences by Middle Up Class Students in SurabayaDocument8 pagesBoarding House Preferences by Middle Up Class Students in Surabayaeditor ijeratNo ratings yet
- Impact of Government Policies and EthicsDocument24 pagesImpact of Government Policies and EthicsGunveen AbrolNo ratings yet
- Openvpn ReadmeDocument7 pagesOpenvpn Readmefzfzfz2014No ratings yet
- Low Speed Aerators PDFDocument13 pagesLow Speed Aerators PDFDgk RajuNo ratings yet
- Song LyricsDocument13 pagesSong LyricsCyh RusNo ratings yet
- Philhis 1blm Group 6 ReportDocument19 pagesPhilhis 1blm Group 6 Reporttaehyung trashNo ratings yet
- Erosional VelocityDocument15 pagesErosional VelocityGary JonesNo ratings yet
- Designing and Drawing PropellerDocument4 pagesDesigning and Drawing Propellercumpio425428100% (1)
- BÀI TẬP LESSON 7. CÂU BỊ ĐỘNG 1Document4 pagesBÀI TẬP LESSON 7. CÂU BỊ ĐỘNG 1Yến Vy TrầnNo ratings yet
- Sainik School Balachadi: Name-Class - Roll No - Subject - House - Assigned byDocument10 pagesSainik School Balachadi: Name-Class - Roll No - Subject - House - Assigned byPagalNo ratings yet
- DR S GurusamyDocument15 pagesDR S Gurusamybhanu.chanduNo ratings yet
- Taoist Master Zhang 张天师Document9 pagesTaoist Master Zhang 张天师QiLeGeGe 麒樂格格100% (2)
- Crisis of The World Split Apart: Solzhenitsyn On The WestDocument52 pagesCrisis of The World Split Apart: Solzhenitsyn On The WestdodnkaNo ratings yet
- Planetary Gear DesignDocument3 pagesPlanetary Gear DesignGururaja TantryNo ratings yet
- Matrix PBX Product CatalogueDocument12 pagesMatrix PBX Product CatalogueharshruthiaNo ratings yet
- Possessive Determiners: A. 1. A) B) C) 2. A) B) C) 3. A) B) C) 4. A) B) C) 5. A) B) C) 6. A) B) C) 7. A) B) C)Document1 pagePossessive Determiners: A. 1. A) B) C) 2. A) B) C) 3. A) B) C) 4. A) B) C) 5. A) B) C) 6. A) B) C) 7. A) B) C)Manuela Marques100% (1)