
You might also like
- Silly 1Document6 pagesSilly 1Raji SuriNo ratings yet
- CH 11 PowerpointDocument62 pagesCH 11 PowerpointRolando QuintanaNo ratings yet
- Liver Diseases by AnilDocument11 pagesLiver Diseases by AnilvisbioNo ratings yet
- Maya AswamDocument48 pagesMaya Aswamvisbio63% (8)
- Matlab TutorialDocument20 pagesMatlab TutorialnityanandsharmaNo ratings yet
- Presentation For FBADocument11 pagesPresentation For FBAvisbioNo ratings yet
- State Bank of India Account Opening FormDocument7 pagesState Bank of India Account Opening Formvisbio100% (1)
- Improvement of Hydrogen Production by Newly Isolated Thermoanaerobacterium Thermosaccharolyticum IIT BT-ST1Document12 pagesImprovement of Hydrogen Production by Newly Isolated Thermoanaerobacterium Thermosaccharolyticum IIT BT-ST1visbioNo ratings yet
- BookList1 PDFDocument5 pagesBookList1 PDFvisbioNo ratings yet
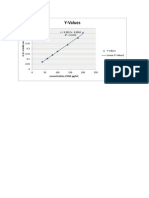
- Bsa Standard GraphDocument1 pageBsa Standard GraphvisbioNo ratings yet
- Ecoli MetabolismDocument7 pagesEcoli MetabolismvisbioNo ratings yet
- Oodankulam Nuclear Power Plant Issues AND Controversies: Presented by Vishnu Vardhan - M Dept. of Biotechnology 11BT60R15Document6 pagesOodankulam Nuclear Power Plant Issues AND Controversies: Presented by Vishnu Vardhan - M Dept. of Biotechnology 11BT60R15visbioNo ratings yet
- Brilliant AppllicationDocument2 pagesBrilliant AppllicationvisbioNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- [18476228 - Organization, Technology and Management in Construction_ an International Journal] Adaptive Reuse_ an Innovative Approach for Generating Sustainable Values for Historic Buildings in Developing CountriesDocument15 pages[18476228 - Organization, Technology and Management in Construction_ an International Journal] Adaptive Reuse_ an Innovative Approach for Generating Sustainable Values for Historic Buildings in Developing Countrieslohithsarath bethalaNo ratings yet
- Beyond Models and Metaphors Complexity Theory, Systems Thinking and - Bousquet & CurtisDocument21 pagesBeyond Models and Metaphors Complexity Theory, Systems Thinking and - Bousquet & CurtisEra B. LargisNo ratings yet
- Chief Complaint: History TakingDocument9 pagesChief Complaint: History TakingMohamad ZulfikarNo ratings yet
- SavannahHarbor5R Restoration Plan 11 10 2015Document119 pagesSavannahHarbor5R Restoration Plan 11 10 2015siamak dadashzadeNo ratings yet
- Xtype Power Train DTC SummariesDocument53 pagesXtype Power Train DTC Summariescardude45750No ratings yet
- DCN Dte-Dce and ModemsDocument5 pagesDCN Dte-Dce and ModemsSathish BabuNo ratings yet
- Amritsar Police StationDocument5 pagesAmritsar Police StationRashmi KbNo ratings yet
- Dessler HRM12e PPT 01Document30 pagesDessler HRM12e PPT 01harryjohnlyallNo ratings yet
- Reaserch On Effect of Social Media On Academic Performance: Study On The Students of University of DhakaDocument27 pagesReaserch On Effect of Social Media On Academic Performance: Study On The Students of University of DhakaFatema Tuz Johoora88% (114)
- Crisis of The World Split Apart: Solzhenitsyn On The WestDocument52 pagesCrisis of The World Split Apart: Solzhenitsyn On The WestdodnkaNo ratings yet
- Project Chalk CorrectionDocument85 pagesProject Chalk CorrectionEmeka Nicholas Ibekwe100% (6)
- Gujarat Urja Vikas Nigam LTD., Vadodara: Request For ProposalDocument18 pagesGujarat Urja Vikas Nigam LTD., Vadodara: Request For ProposalABCDNo ratings yet
- IOT Questions and Answers - SolutionDocument8 pagesIOT Questions and Answers - SolutionOmar CheikhrouhouNo ratings yet
- Additional Article Information: Keywords: Adenoid Cystic Carcinoma, Cribriform Pattern, Parotid GlandDocument7 pagesAdditional Article Information: Keywords: Adenoid Cystic Carcinoma, Cribriform Pattern, Parotid GlandRizal TabootiNo ratings yet
- RPH Week 31Document8 pagesRPH Week 31bbwowoNo ratings yet
- Web-Based Attendance Management System Using Bimodal Authentication TechniquesDocument61 pagesWeb-Based Attendance Management System Using Bimodal Authentication TechniquesajextopeNo ratings yet
- Functional Programming in Swift by Eidhof Chris, Kugler Florian, Swierstra Wouter.Document212 pagesFunctional Programming in Swift by Eidhof Chris, Kugler Florian, Swierstra Wouter.angloesamNo ratings yet
- Days Papers 2001Document341 pagesDays Papers 2001jorgefeitoza_hotmailNo ratings yet
- Lab Manual Switchgear and Protection SapDocument46 pagesLab Manual Switchgear and Protection SapYash MaheshwariNo ratings yet
- PetrifiedDocument13 pagesPetrifiedMarta GortNo ratings yet
- STS Module 11Document64 pagesSTS Module 11Desiree GalletoNo ratings yet
- Twin PregnancyDocument73 pagesTwin Pregnancykrishna mandalNo ratings yet
- Group 2 ITI Consensus Report: Prosthodontics and Implant DentistryDocument9 pagesGroup 2 ITI Consensus Report: Prosthodontics and Implant DentistryEsme ValenciaNo ratings yet
- Loop Types and ExamplesDocument19 pagesLoop Types and ExamplesSurendran K SurendranNo ratings yet
- Healthymagination at Ge Healthcare SystemsDocument5 pagesHealthymagination at Ge Healthcare SystemsPrashant Pratap Singh100% (1)
- All India Civil Services Coaching Centre, Chennai - 28Document4 pagesAll India Civil Services Coaching Centre, Chennai - 28prakashNo ratings yet
- Benefits and Limitations of BEPDocument2 pagesBenefits and Limitations of BEPAnishaAppuNo ratings yet
- Camless EnginesDocument4 pagesCamless EnginesKavya M BhatNo ratings yet
- Advertisement: National Institute of Technology, Tiruchirappalli - 620 015 TEL: 0431 - 2503365, FAX: 0431 - 2500133Document4 pagesAdvertisement: National Institute of Technology, Tiruchirappalli - 620 015 TEL: 0431 - 2503365, FAX: 0431 - 2500133dineshNo ratings yet
- UAV Design TrainingDocument17 pagesUAV Design TrainingPritam AshutoshNo ratings yet





















































![[18476228 - Organization, Technology and Management in Construction_ an International Journal] Adaptive Reuse_ an Innovative Approach for Generating Sustainable Values for Historic Buildings in Developing Countries](https://imgv2-2-f.scribdassets.com/img/document/422064728/149x198/344a5742a7/1565947342?v=1)




























