Professional Documents
Culture Documents
Apuntes IntroInfer
Uploaded by
ElMisterioDeCalendaOriginal Title
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Apuntes IntroInfer
Uploaded by
ElMisterioDeCalendaCopyright:
Available Formats
Captulo 5
Introduccin a la inferencia estadstica
1. La inferencia estadstica. Poblacin y muestra 2. Distribucin muestral de un estadstico 3. La distribucin de la media muestral 4. Estimacin y estimadores 5. El mtodo de los momentos 6. Diagnosis y crtica del modelo 7. El mtodo de mxima verosimilitud
0 Apuntes
realizados por Ismael Snchez. Universidad Carlos III de Madrid.
CAPTULO 5. INTRODUCCIN A LA INFERENCIA ESTADSTICA
5.1.
La inferencia estadstica. Poblacin y muestra
Como ya se ha dicho en anteriores temas, uno de los principales objetivos de la estadstica es el aprendizaje a partir de la observacin. En particular, la estadstica proporciona el mtodo para poder conocer cmo es el fenmeno real que ha generado los datos observados y que generar los futuros. En estadstica, el inters nal no est tanto en los datos observados, sino en cmo sern los prximos datos que se vayan a observar. Como ya se ha estudiado anteriormente, consideraremos que la variable que nos interesa es una variable aleatoria X , y que los datos que observamos son slo una muestra (conjunto de realizaciones) procedente de dicha variable aleatoria. La variable aleatoria puede generar un nmero indenido de datos. Todos los datos posibles (posiblemente innitos) sern la poblacin. Por eso, muchas veces nos referiremos de forma indistinta a la poblacin o a la variable aleatoria que la genera. Supongamos, por ejemplo, que queremos saber cmo son los artculos manufacturados por un determinado proceso. Para ello nos concentraremos en algn conjunto de variables medibles que sean representativas de las caractersticas de dicho artculo. Por ejemplo, la longitud de alguna de sus dimensiones podra ser una variable que nos interese conocer. La longitud de los posibles artculos manufacturados ser una variable aleatoria, pues todo proceso productivo tiene siempre variabilidad, grande o pequea. Las longitudes de los distintos artculos sern, en general, distintas. Diremos entonces que X = longitud de un artculo genrico, es una variable aleatoria de distribucin desconocida. Para poder saber cmo es esa variable aleatoria, produciremos una muestra de artculos, y a partir de ella haremos un ejercicio de inducccin, para extrapolar las caractersticas de la muestra a toda la poblacin. En estadstica, al ejercicio de induccin, por el que a partir de la muestra intentamos predecir cmo ser el resto de la poblacin que no se ha observado (la variable aleatoria) se le llama inferencia estadstica, o simplemente inferencia. Supondremos que para realizar este ejercicio de inferencia tenemos una conjunto de datos obtenidos al azar de entre la poblacin de posibles datos. A una muestra de este tipo se le llamar muestra aleatoria simple. Por simplicidad, y mientras no se diga lo contrario, supondremos que las muestras que obtengamos sern muestras aleatorias simples, y por tanto nos referiremos a ellas simplemente como muestras. En una muestra aleatoria simple se tienen dos caractersticas importantes: 1. Los elementos de la muestra son independientes entre s. Por tanto, el valor que tome uno de ellos no condicionar al de los dems. Esta independecia se puede conseguir seleccionando los elementos al azar. 2. Todos los elementos tienen las mismas caractersticas que la poblacin. Sea X nuestra variable aleatoria de inters, y sean X1 , X2 , ..., Xn los elementos de una muestra de tamao n de dicha variable aleatoria X. Entonces, antes de ver los valores concretos que tomar la muestra formada por X1 , X2 , ..., Xn , tendremos que la muesta X1 , X2 , ..., Xn ser un conjunto de variables aleatorias independientes e idnticas a X.
5.2.
Distribucin muestral de un estadstico
Volvamos a nuestro ejemplo del proceso productivo, en el que estamos interesados en saber cmo es la variable aleatoria X =longitud de un artculo genrico. Estamos interesados en las caractersticas de la poblacin, es decir, en todas las longitudes posibles. Supongamos que tenemos una muestra de n = 100 artculos y hemos medido sus longitudes. Supongamos que calculamos un
5.2. DISTRIBUCIN MUESTRAL DE UN ESTADSTICO
conjunto de medidas caractersticas de dicha muestra de 100 longitudes: la media, la varianza, etc. Son dichos valores los de la poblacin? Est claro que no. La media de las n = 100 longitudes no tiene por qu coincidir con la media de toda la poblacin. La media de la poblacin ser el promedio de TODOS sus innitos datos, y slo por casualidad ser igual al promedio de los n = 100 datos que hemos seleccionado al azar. El problema es que si no tenemos todos los innitos datos, no podremos conocer las medidas caractersticas de la poblacin. Slo tendremos lo que podamos obtener de la muestra. Por tanto, una primera conclusin que podemos extraer al intentar predecir (inferir) las medidas caractersticas de una poblacin utilizando una muestra es la siguiente: Conclusin 1: Los valores de las medidas caractersticas que se obtienen de una muestra sern slo una aproximacin de los valores de las medidas caractersticas de la poblacin. Otra segunda limitacin de intentar averiguar cmo es una poblacin a partir de la informacin de una muestra, es que nuestras conclusiones dependen de la muestra concreta que hayamos obtenido. Con otras muestras tendramos otros valores en nuestras medidas caractersticas y podramos sacar conclusiones diferentes sobre la poblacin. Supongamos que tomamos una muestra = 23,5 de n = 100 artculos y medimos esas 100 longitudes obteniendo una longitud media de X cm Quiere esto decir que cada vez que tomemos una muestra al azar de 100 de dichos artculos = 23,5 cm? Pues obviamente no. Ser mucha y los midamos, su media muestral ser siempre X casualidad que dos muestras distintas nos den exctamente la misma media. Como son muestras de una misma poblacin, las medias ser ms o menos similares, pero no tienen por qu coincidir. Por tanto, se puede concluir los siguiente: Conclusin 2: Los valores de las medidas caractersticas que se obtienen de una muestra dependen de los elementos que la constituyen. Muestras diferentes darn por tanto valores diferentes. Como los elementos han sido seleccionados al azar, se dice que los valores de las medidas caractersticas de una muestra dependen del azar del muestreo. En lugar de hablar de medidas caractersticas de una muestra, hablaremos de forma ms general de operaciones matemticas realizadas con la muestra. Vamos a introducir entonces un nuevo concepto: llamaremos estadstico a cualquier operacin realizada con una muestra. Por ejemplo, la media muestral es un estadstico, as como la varianza, el rango, o cualquier otra medida caracterstica. El estadstico es la operacin matemtica, no el resultado obtenido. El estadstico tomar, de acuerdo a la conclusin 2 anterior, un valor diferente en cada muestra. Un estadstico ser, por tanto, una variable aleatoria pues el valor concreto que obtengamos depender del azar del muestreo. El resultado obtenido con una muestra concreta ser una realizacin de dicha variable aleatoria. Cada vez que realicemos el experimento de computar el valor de un estadstico en una muestra diferente, obtendremos una realizacin diferente del estadstico. En la prctica, tendremos una sola muestra, y por tanto una sola realizacin del estadstico. Si queremos dar alguna interpretacin al valor de la realizacin de un estadstico en una muestra concreta, necesitamos conocer cmo vara el valor que puede tomar el estadstico de unas muestras a otras (ese ser uno de los objetivos de este tema). Por ejemplo, supongamos el caso de las longitudes de los artculos antes mencionados. Supongamos tambin que sabemos por informacin histrica que si el proceso productivo funciona adecuadamente, la longitud media () de los artculos que produce debe ser de =25 cm. Cmo podemos entonces interpretar que en una muestra de = 23,5 cm? Es esa diferencia (25-23.5) evidencia de tamao n = 100 se haya obtenido que X
CAPTULO 5. INTRODUCCIN A LA INFERENCIA ESTADSTICA
que la media se ha reducido y por eso la muestra tiene una media menor? O la media no ha cambiado y esa discrepancia (25-23.5) puede atribuirse a la variabilidad debida al muestreo? Si no no podremos valorar si 23.5 es un nmero muy alejado de conocemos la funcin de densidad de X 25, y por tanto sospechoso de que algo ha ocurrido en el proceso; o por el contrario que sea muy frecuente que muestras de una poblacin de media = 25 den alejamientos tan grandes como 23.5. Supongamos ahora que extraemos una segunda muestra de tamao n = 100 tras haber realizado (2) = 24. Quiere algunos ajustes a la mquina y que obtenemos que la nueva media muestral es X decir que los ajustes han provocado un aumento en la media (de 23.5 a 24)?o ese cambio (23.5-24) puede explicarse simplente por ser muestras diferentes de una misma poblacin de media 25?. El tipo de preguntas que se plantean en el prrafo anterior son muy importantes en la prctica, y sern las que querramos resolver con la estadstica. Para responder a este tipo de preguntas, es necesario conocer las caractersticas del estadstico que nos interese (en el caso del ejemplo, la media muestral). A la distribucin de un estadstico debido a la variabilidad de la muestra se le denomina, distribucin del estadstico en el muestreo. Esta distribucin depender de cada caso concreto. Es importante darse cuenta de que estamos manejando dos niveles de variables aleatorias. En un primer nivel, ms supercial, estara nuestra variable aleatoria de inters X . En nuestro ejemplo sera X = longitud de un artculo genrico de nuestro proceso productivo. Para conocer las propiedades de dicha variable aleatoria extraemos una muestra aleatoria simple de tamao n. Las longitudes de esos n elementos sern X1 , X2 , ..., Xn . Como hemos dicho anteriormente, antes de extraer la muestra, no sabremos qu valores tomarn X1 , X2 , ..., Xn . Y al tratarse de una muestra aleatoria simple, estos n elementos pueden interpretarse como un conjunto de n variables aleatorias independientes, e idnticas a nuestra variable de inters X. Nuestro objetivo es utilizar la muestra para saber cmo es X. Para ello, computamos el valor de un conjunto de estadsticos de inters 2 Sx con los datos de la muestra: X, , etc. Esos estadsticos constituirn, debido a la variabilidad del muestreo, un segundo nivel de variables aleatorias con caractersticas diferentes a X. Para jar mejor estos conceptos, en la seccin siguiente veremos el caso de la media muestral.
5.3.
La distribucin de la media muestral
Supongamos que tenemos una muestra de tamao n de una variable aleatoria X. Los elementos de dicha mestra sern sern X1 , X2 , ..., Xn . La media muestral de esas n observaciones es el siguiente estadstico: = X1 + X2 + + Xn . X (5.1) n es tambin una variable Como cada Xi es una variable aleatoria (idntica a X ) tendremos que X aleatoria. De esta manera, su valor ser, en general, diferente en cada muestra. El objetivo de esta en el muestreo. seccin es analizar cmo es la distribucin de X Si llamamos E (X ) = tendremos En primer lugar calcularemos la esperanza matemtica de X. que E (Xi ) = , i = 1, 2, ..., n. Entonces X1 + X2 + + Xn n E (X1 ) + E (X2 ) + + E (Xn ) n = = . n n
) = E E (X
(5.2)
pueda variar de unas muestras a otras, por trmino medio proporciona el Por tanto, aunque X valor de la media poblacional, que es al n y al cabo nuestro objetivo. Este resultado es muy
5.4. ESTIMACIN Y ESTIMADORES
importante, pues nos dice que de los posibles valores que podamos obtener al cambiar la muestra, el centro de gravedad de ellos es la media poblacional. Para ver la dispersin de los distintos valores de medias muestrales alrededor de , calcularemos Llamaremos Var(X ) = 2 . Por tanto Var(Xi ) = 2 , i = 1, 2, ..., n. Entonces, la varianza de X. X1 + X2 + + Xn Var (X1 + X2 + + Xn ) . Var(X ) = Var = n n2 Al ser una muestra aleatoria simple, los Xi sern variables aleatorias independientes, y por tanto tendremos que ) = Var(X Var(X1 ) + Var(X2 ) + + Var(Xn ) n 2 2 = = . 2 n n n (5.3)
De este resultado se pueden sacar dos conclusiones que son tambin importantes: 1. La varianza disminuye con el tamao muestral. Por tanto cuantos ms datos se tengan ser ms probable que la media muestral sea un valor prximoa . alrededor de depende de la dispersin de la variable original X. As, 2. La dispersin de X si 2 es muy grande har falta un tamao muestral grande si queremos asegurarnos que la media muestral est cerca de la poblacional. Finalmente, vemos que la media muestral puede escribirse como suma de variables aleatorias. Reescribiendo (5.1) tenemos que = X1 + X2 + + Xn , X n n n y por tanto, por el Teorema Central del Lmite (ver tema anterior) tenemos que, indepen ser dientemente de cmo sea X, si el tamao muestral n es sucientemente grande X aproximadamente una distribucin normal. Se tiene por tanto que si n es grande (en la prctica, con ms de 30 datos) 2 N , . X (5.4) n Por tanto, la media muestral realizada con un nmero suciente de datos es una variable aleatoria simtrica y muy concentrada alrededor de la media poblacional, independientemente de cmo sea la naturaleza de X . De esta forma, la media muestral con un tamao muestral sucientemente grande proporciona una forma bastante precisa de aproximar la media poblacional . No olvidemos Por esta que en la prctica tendremos una sola muestra, y por tanto una sola realizacin de X. razn, es muy til disponer de resultados tericos tan interesantes como (5.4), que nos ayuden a valorar la abilidad de la media muestral. Ntese que el resultado (5.4) es independiente de la distribucin que siga X si n es grande. En los prximos temas obtendremos ms conclusiones y construiremos procedimientos estadsticos basados en este resultado.
5.4.
Estimacin y estimadores
Lo que hemos hecho en la seccin anterior: utilizar la media muestral para asignar un valor aproximado a la media poblacional se denomina estimacin. En general, la estimacin consiste
CAPTULO 5. INTRODUCCIN A LA INFERENCIA ESTADSTICA
en asignar valores numricos a aquellos parmetros poblacionales que no conozcamos. Un ejemplo de parmetros poblacionales desconocidos seran las medidas caractersticas de poblaciones de las que slo observamos una muestra. La estimacin se realiza mediante la utilizacin de un estadstico, que evaluamos con una muestra de datos. Llamaremos estimador al estadstico que se usa para estimar un parmetro. Por ejemplo, supongamos que despus de analizar una muestra de longitudes de n artculos hemos concluido que la distribucin normal es un modelo de probabilidad adecuado para describir las longitudes de las piezas que salgan de dicho proceso productivo, es decir X N (, 2 ). El problema entonces estar en asignar valores a los parmetros desconocidos , y 2 de dicha distribucin. El problema de estimacin no solo aparece cuando buscamos un modelo de probabilidad. En algunos casos slo estamos interesados en algunas medidas caractersticas poblacionales: media, varianza, etc. En ambos casos, tanto si estamos interesados en encontrar un modelo de probabilidad o slo algunas medidas caractersticas, tenemos que utilizar una muestra de datos para estimar un parmetro poblacional desconocido. Un parmetro es siempre una propiedad de la poblacin, y por tanto ser una constante de valor desconocido. El valor del parmetro de una Poisson o una exponencial, o el parmetro p de una binomial, etc slo se podran conocer con exactitud si tuvisemos acceso a toda la poblacin; es decir, si repitisemos el experimento aleatorio indenidamente, lo que en la prctica es imposible. Para denotar a un estimador usaremos la misma letra que el parmetro pero con el acento circumejo (^) encima. Para el caso de la media poblacional , un estimador ser denotado por . Si usamos la media muestral como estimador de la media tendremos entonces que = X1 + X2 + + Xn . =X n es, como cualquier otro estimador que hubisemos seleccionado, una variable El estimador =X aleatoria, pues su valor cambia de unas muestras a otras. Vemos entonces que al estudiar una variable aleatoria X nos topamos con otra nueva variable aleatoria que ser necesario analizar. Las propiedades estadsticas ms importantes de un estimador cualquiera son su esperanza matemtica y su varianza. Si para estimar un parmetro tuvisemos que elegir entre varios estimadores alternativos, elegiramos aqul que tuviese mejores propiedades estadsticas. A continuacin vamos a enunciar qu propiedades estadsticas de un estimador conviene tener en cuenta. Supongamos que queremos estimar un parmetro y usamos un estimador que consiste en cierta operacin matemtica realizada con una muestra. Las caractersticas ms importantes de son E ( ) y Var( ). En general sern preferibles aquellos estimadores que veriquen que E ( ) = . A los estimadores que verican esta propiedad se les denomina insesgados o centrados. Si un estimador verica que E ( ) 6= se dice que el estimador es sesgado. El sesgo de un estimador viene entonces denido por sesgo( ) = E ( ) . Por ejemplo, vimos en (5.2) que la media mestral es una variable aleatoria de media . Por lo tanto la media mestral es un estimador insesgado de la media poblacional. En lo que respecta a la varianza de la variable aleatoria , diremos que, en general sern preferibles aquellos estimadores que tengan menor varianza, pues ser, ms precisos en el sentido de que variarn poco de unas muestras a otras. A la desviacin tpica de un estimador se le suele denominar error estndar del estimador. Por ejemplo, en el caso de la media muestral como estimador de la media poblacional, veamos en la seccin anterior que Var( ) = 2 /n. Por tanto, el error estndar de es / n.
5.5. EL MTODO DE LOS MOMENTOS
En general, entre un conjunto de estimadores alternativos para un mismo parmetro, elegiremos aqul que tenga menor ECM. Al estimador que tiene menor ECM le diremos que es eciente.
Vemos entonces que es preferible un estimador insesgado a otro sesgado, y un estimador con poco error estndar a otro con mayor error estndar. Y si dos estimador tiene menos sesgo que otro, pero ms varianza?Cmo elegimos el mejor? Para estos casos, deniremos un crtiterio que tenga en cuenta tanto el sesgo como la varianza. Deniremos error cuadrtico medio de un estimador ECM( ) a h i2 ECM( ) = sesgo( ) + Var .
Ejemplo 1 En muestras aleatorias simples de tamao n = 3 de una variable aleatoria normal de media y varianza conocida 2 = 1, se consideran los siguientes estimadores de : U1 = 1 X1 + 3 1 U2 = X1 + 4 1 U3 = X1 + 8 1 X2 + 3 1 X2 + 2 3 X2 + 8 1 X3 , 3 1 X3 , 4 1 X3 , 2
donde X1 , X2 , X3 son las observaciones. Comprobar que son estimadores insesgados y estudiar su error cuadrtico medio. SOLUCIN: 1 E (X1 ) + 3 1 E (X1 ) + 4 1 E (X1 ) + 8 1 E (X2 ) + 3 1 E (X2 ) + 2 3 E (X2 ) + 8 1 E (X3 ) = 3 1 E (X3 ) = 4 1 E (X3 ) = 2 1 3 = 3 1 1 + + 4 2 1 3 + + 8 8
E (U1 ) = E (U2 ) = E (U3 ) =
1 = 4 1 = 2
Al ser centrados, el ECM es la varianza. 1 V ar(U1 ) = V ar( X1 + 3 1 V ar(U2 ) = V ar( X1 + 4 1 V ar(U3 ) = V ar( X1 + 8 1 X2 + 3 1 X2 + 2 3 X2 + 8 1 X3 ) = 3 1 X3 ) = 4 1 X3 ) = 2 1 1 1 1 1 V ar(X1 ) + V ar(X2 ) + V ar(X3 ) = 2 = = 0,333 9 9 9 3 3 1 1 1 3 3 V ar(X1 ) + V ar(X2 ) + V ar(X3 ) = 2 = = 0,375 16 4 16 8 8 1 9 1 26 2 13 V ar(X1 ) + V ar(X2 ) + V ar(X3 ) = = = 0,406 64 64 4 64 32
luego el ms eciente es U1 .
5.5.
El mtodo de los momentos
Existen varios procedimientos para construir estimadores. El ms sencillo sea tal vez el mtodo de los momentos. El mtodo de los momentos consiste bsicamente en estimar una caracterstica de la poblacin con la respectiva caracterstica muestral. As, para estimar la media poblacional De la misma forma, el , el mtodo de los momentos consistira en utilizar la media muetral X. 2 estimador de la varianza poblacional por el mtodo de los momentos ser la varianza de la
CAPTULO 5. INTRODUCCIN A LA INFERENCIA ESTADSTICA
muestra s2 . Si lo que queremos es estimar una probabilidad p de que se observe un suceso en una poblacin, usaremos la proporcin muestral, es decir, la proporcin de veces que se ha observado el suceso en la muestra analizada. El nombre de mtodo de los momentos viene de que en estadstica se denomina momento de una P poblacin de orden m a E (X m ), mientras que momento muestral de orden m m es (1/n) n i=1 Xi . Por tanto el primer momento poblacional es E (X ) = y el primer momento muestral X. El segundo momento poblacional ser E (X 2 ) y el segundo momento muestral ser Pn 2 i=1 Xi n. Asmismo, se denomina momento poblacional de orden m P respecto a la media a E [(X )m ] m n y el momento muestral de orden m respecto a la media es (1/n) i=1 Xi X . La media es el momento de primer orden. Por tanto la varianza poblacional 2 es el momento de segundo orden respecto a la media, y la varianza muestral s2 es el segundo momento muestral respecto a la media. Ejemplo 2 Sean t1 , t2 , ..., tn el tiempo de atencin a n clientes en cierto puesto de servicio. Si el tiempo de atencin es una variable aleatoria exponencial de parmetro , estima este parmetro por el mtodo de los momentos. SOLUCIN: Como en una exponencial se tiene que E (T ) = 1 1 = , E (T )
Entonces, estimaremos E (T ) con la media muestral, es decir: Pn ti T = i=1 , n y por tanto el estimador de por el mtodo de los momentos ser: = 1 T Ejemplo 3 Se desea estimar la proporcin de artculos defectuosos que produce una mquina. Para ello se analizan n artculos, resultando que d son defectuosos. Estima p por el mtodo de los momentos. Supondremos que la aparicin de artculos defectuosos sigue un proceso de Bernoulli. SOLUCIN: Si llamamos X a la variable de Bernoulli que vale 1 si el artculo es defectuoso y 0 si es aceptable, entonces E (X ) = p Estimaremos p mediante el promedio de las variables de Bernoullis de los n artculos analizados. Por tanto, si Xi = 1 si el artculo i-simo es defectuosos y 0 si es aceptable, Pn d i=1 Xi = p = n n nmero de artculos defectuosos = , nmero de artculos analizados por lo que el estimador de la proporcin poblacional es la proporcin muestral.
5.6. DIAGNOSIS DEL MODELO
5.6.
Diagnosis del modelo
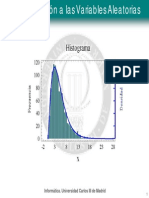
Dado un conjunto de datos x1 , ..., xn , obtenidos al extraer una muestra aleatoria simple de una poblacin, queremos inferir qu distribucin sigue dicha poblacin. Es decir, queremos saber si siguen una distribucin normal, o una exponencial o cualquier otro modelo en el que estemos interesados. Hay muchos procedimientos para hacer ese ejercicio de inferencia. El ms utilizado consiste en evaluar la similitud del histograma de los datos con la funcin de densidad o de distribucin seleccionada. Por ejemplo, el siguiente histograma muestra el peso de 191 monedas de 100 pesetas recogidas justo antes de su desaparicin y sustitucin por el euro (chero monedas100.sf3 ). El histograma sugiere que el peso de las monedas de 100 pesetas puede ser una normal. Mejor dicho, que la normal es un modelo de distribucin adecuado para modelizar la distribucin de probabilidades de (todas) las monedas de 100 pesetas. En este caso diremos que los datos se ajustan a la distribucin elegida.
Las medidas caractersticas de este conjunto de datos son x = 9,23, s2 = 0,0075. Estas medidas caractersticas las emplearemos como estimadores de los parmetros poblacionales y 2 . Si superponemos al histograma anterior la funcin de densidad de una N (9,23; 0,0075) tenemos el siguiente grco.
Lo que vamos a hacer a continuacin es una prueba estadstica que compare esa curva de la normal con el histograma. Si hay poca discrepancia entre la probabilidad que dice el modelo y la
10
CAPTULO 5. INTRODUCCIN A LA INFERENCIA ESTADSTICA
frecuencia relativa observada en los datos en todos y cada uno de los intervalos, podremos concluir que es muy plausible que dicho histograma pueda proceder de la poblacin representada por el modelo. O bien, que podemos adoptar dicho modelo para representar a la poblacin de la cual proceden nuestros datos. Existen muchas pruebas estadsticas que comparan los datos observados con modelos de probabilidad. La prueba estadstica ms popular es el test la chi-cuadrado. A este tipo de pruebas se le denomina pruebas de bondad de ajuste, pues lo que hacemos es medir cmo se ajustan los datos al patrn que marca el modelo elegido. Puede verse que en esta prueba estadstica estamos haciendo un ejercicio de induccin o inferencia, pues vamos de lo particular -los datos observados- a lo general -el modelo que ha generado no solo a esos datos sino al resto de datos que no hemos tomado-. Todas las pruebas de este tipo se basan en algn tipo de comparacin de los datos con el modelo elegido. Si la discrepancia es grande se rechaza dicho modelo, si la discrepancia no es grande no se rechaza el modelo, y se considera que es una buena representacin de la poblacin que gener los datos. La siguiente gura muestra un conjunto de datos donde la discrepancia con la normal es mayor que en el ejemplo de las monedas de 100 pesetas. Los datos corresponden al precio de unos vehculos (segn el chero cardata.sf ).
A continuacin comentaremos brevemente cmo se realiza la prueba de la chi-cuadrado, aunque en la prctica la haremos siempre con el ordenador. Supondremos que tenemos siempre un mnimo de unos 25 datos, de lo contrario, la prueba es poco able. Para hacer el contraste chi-cuadrado se siguen los siguientes pasos: 1. Se hace el histograma, usando ms de 5 clases con al menos 3 datos en cada clase. 2. En cada clase del histograma obtenemos la frecuencia (absoluta) observada de individuos, que denotaremos por Oi , i = 1, 2, ..., k, siendo k el nmero de clases del histograma. 3. Con los datos estimamos los parmetros del modelo seleccionado, y calculamos con dicho modelo la probabilidad pi de obtener valores en cada una de las clases del histograma. Llamaremos Ei = npi a la frecuencia absoluta esperada de acuerdo al modelo seleccionado Oi 4. Calculamos el siguiente estadstico
2 = X0 k X (Oi Ei )2 i=1
Ei
5.6. DIAGNOSIS DEL MODELO
11
2 Este estadstico X0 resume toda la discrepancia entre el histograma y el modelo.
2 es un nmero elevado rechazaramos el modelo, mientras que en caso contrario acep5. Si X0 taramos el modelo como adecuado para representar a la poblacin que genera los datos. Para 2 valorar X0 es necesario alguna referencia que nos diga cundo es grande y cundo no. La obtencin de esta referencia se explica a continuacin.
2 La valoracin del estadstico X0 se basa en el siguiente resultado:
Si los datos pertenecen a una poblacin que sigue el modelo de probabilidad elegido, 2 el estadstico X0 ser una variable aleatoria que sigue una distribucin denominada Chi-cuadrado, y que se simboliza por 2 g , donde g es un parmetro que se denomina grados de libertad. Los grados de libertad son g = k v 1, donde v es el nmero de parmetros que hemos estimado en ese modelo. Por el conrario, si la distribucin no 2 es adecuada, el estadstico X0 no seguir dicha distribucin, y podr tomar un valor muy grande con mucha probabilidad La distribucin 2 g es una distribucin asimtrica de valores positivos. Es una distribucin que se encuentra tabulada en muchos textos de estadstica. La siguiente gura muestra dos ejemplos de distribuciones 2 g , de 5 y 10 grados de libertad respectivamente.
2 Consideraremos que el modelo no es adecuado para nuestros datos, si X0 est en la zona de la derecha de la distribucin, donde la probabilidad de que la distribucin 2 g genere valores en 2 esa zona es ya muy pequea. Por tanto, si X0 est en la zona de la cola de la derecha, ser seal de que el modelo elegido no es adecuado. La siguiente gura ilustra esta idea. En esta gura se 2 muestran dos valores de X0 obtenidos al proponer dos modelos diferentes, M1 y M2, a un mismo 2 conjunto de datos. El valor de X0 ms pequeo nos llevara a concluir que el modelo M1 elegido es adecuado, tiene un buen ajuste a los datos; mientras que el mayor nos llevara a concluir que el
12
CAPTULO 5. INTRODUCCIN A LA INFERENCIA ESTADSTICA
otro modelo, el M2 no se ajusta bien a los datos.
2 Los programas informticos proporcionan el rea que queda a la derecha de X0 en la distribucin de referencia. Ese rea recibe el nombre de p-valor. De esta forma, cuanto menor sea el p-valor, 2 peor es el modelo elegido para representar a nuestra poblacin, pues indicar que X0 est muy a la derecha de la distribucin. En general, rechazaremos un modelo si p-valor<0.05. Veamos algunos ejemplos.
Ejemplo 4 El chero monedas100.sf3 contiene el peso de 191 monedas de 100 pesetas. El histograma del peso de estas monedas se ha mostrado anteriormene, sugiriendo que la curva normal puede ser un buen modelo para representar a la poblacin de pesos de esas monedas. Una prctica comn en la aplicacin del test de la chi-cuadrado es hacer clases de tal manera que la frecuencia esperada Ei en cada clase sea la misma. Para ello, las clases deben ser de longitud diferente. De esta manera se evita que algunas clases tengan pocas observaciones, lo que empeora la abilidad de esta prueba estadstica. Por tanto, el histograma que nos muestre el programa informtico, basado en clases iguales, no coincidir con el histograma que utilice para hacer el test. A continuacin se
5.6. DIAGNOSIS DEL MODELO
13
muestra el resultado del test que realiza el Statgraphics:
Puede verse que el p-valor es bastante mayor que 0.05. Por tanto, consideramos que la normal es un modelo adecuado para modelizar los pesos de las monedas de 100 pesetas. A continuacin vamos a intentar ajustar un modelo que sea claramente inadecuado. Si elegimos la distribucin uniforme tenemos la siguiente gura:
donde puede verse que el modelo elegido no se ajusta a los datos. El test de la chi-cuadrado que
14
CAPTULO 5. INTRODUCCIN A LA INFERENCIA ESTADSTICA
resulta es
que muestra un p-valor=0.0, por lo que resulta evidente que la distribucin uniforme no es un modelo adecuado para este tipo de datos Ejemplo 5 En este ejemplo vamos a ajustar en primer lugar una distribucin normal a la variable precio, del chero cardata.sf. Ms arriba se mostr el histograma con la curva normal superpuesta. Dicha curva normal es la que se obtiene al usar la media muestral y la varianza muestral de los datos. El test de la chi-cuadrado da el siguiente resultado:
El p-valor es muy pequeo, por lo que se conrma lo que sugera el histograma con la distribucin normal: la normal no es una buena representacin para esta variable. No obstante vemos que la caracterstica de estos datos es su asimetra positiva. Podemos intentar alguna transformacin que haga la distribucin de los datos ms simtrica (ver Tema 1), y tal vez entonces la variable transformada s sea normal. A continuacin se muestra el resultado de hacer la transformacin
5.7. EL MTODO DE MXIMA VEROSIMILITUD
15
X.
Esta transformacin ha conseguido una mayor simetra, pero an se nota una mayor cola hacia la derecha. El test de la chi-cuadrado an tiene un p-valor muy pequeo. El ajuste a la normal de X no es adecuado. Probaremos entonces otra transformacin que sea algo ms fuerte que la raz cuadrada. La gura siguiente muestra el resultado de aplicar la transformacin ln(X ).
En esta ocasin, la transformacin s que proporciona un mejor ajuste a la normal. El p-valor es ya sucientemente grande. Por tanto podemos considerar que el logaritmo de los precios se ajusta a una normal. (Esto es equivalente a decir que los precios siguen una distribucin lognormal)
5.7.
5.7.1.
El mtodo de mxima verosimilitud
Introduccin
El mtodo de los momentos proporciona en muchas ocasiones una forma sencilla de obtener estimaciones de los parmetros de dicho modelos. Otro procedimeinto para estimar parmetros a partir de una muestra es el llamado mtodo de mxima verosimilitud (MV). El mtodo de MV es ms complejo que el de los momentos, pero proporciona, en general, estimadores con mejores propiedades estadsticas. La razn de la superioridad del mtodo de MV est en que se basa en la funcin de probabilidad o densidad de la poblacin, mientras que el mtodo de los momentos
16
CAPTULO 5. INTRODUCCIN A LA INFERENCIA ESTADSTICA
no aprovecha esa informacin. En muchas ocasiones MV proporciona los mismos resultados que el mtodo de los momentos. Otra ventaja del mtodo de MV es que permite estimar parmetros que no estn relacionados con ningn momento muestral. Ejemplo 6 La velocidad de una molcula, segn el modelo de Maxwell, es una variable aleatoria con funcin de densidad, 4 1 2 (x/)2 x e , x0 3 f (x) = 0, x < 0. Donde > 0, es el parmetro de la distribucin. Se desea estimar el parmetro . Si calculsemos E (X ) veramos que no guarda una relacin sencilla con , que permita estimar a a patir de X. Sera deseable, por tanto, disponer de otra forma de estimar . El mtodo de mxima verosimilitud consiste en estimar un parmetro mediante el valor que haga que la muestra observada sea un suceso de probabilidad mxima. Por ejemplo, sea p la probabilidad de observar un suceso al realizar un experimento. Si despus de repetir 10 veces el experimento hemos observado el suceso en 5 ocasiones, Cul ser el estimador mximo verosimil de p? Pues, obviamente p = 0,5 ser el valor que haga que la muestra observada sea el suceso ms probable de entre todos los posibles. En el mtodo de MV vamos a hacer un procedimiento matemtico muy general que nos permita precisamente obtener este tipo de estimadores. El mtodo de mxima verosimilitud tiene los siguientes pasos: 1. Encontrar la funcin que nos d, para cada valor del parmetro, o conjunto de parmetros, la probabilidad de observar una muestra dada. 2. Encontrar los valores de los parmetros que maximizan dicha funcin, lo que se obtiene simplemente derivando
5.7.2.
La distribucin conjunta de la muestra
Sea una variable aleatoria X de funcin de probabilidad p(x) o funcin de densidad f (x) que depende del parmetro (o vector de parmetros) . Sean x1 , ..., xn los valores observados en una muestra aleatoria simple X1 , X2 , ..., Xn de dicha variable aleatoria X . Entonces la funcin de probabilidad conjunta ser la funcin p(x1 , ..., xn ) que proporcionar la probabilidad p(x1 , ..., xn ) = P (X1 = x1 ; X2 = x2 ; ...; Xn = xn ), es decir, es la probabilidad de obtener unos datos concretos x1 , ..., xn . Esta funcin depender del parmetro . Por tanto podemos escribir p(x1 , ..., xn ) = p(x1 , ..., xn , ), que proporcionar, para cada valor de la probabilidad de observar x1 , ..., xn . Esta es precisamente la funcin que necesitamos maximizar en funcin de en el caso de una variable aleatoria discreta. En el caso de una variable aleatoria continua, la funcin de densidad conjunta ser f (x1 , ..., xn ) proporcionar la probabilidad por unidad de medidad de la muestra. Esta funcin es tambin funcin de los parmetros y tambin puede escribirse como f (x1 , ..., xn ) = f (x1 , ..., xn , ),
5.7. EL MTODO DE MXIMA VEROSIMILITUD
17
y sta ser la funcin a maximizar en funcinde . Las funciones p(x1 , ..., xn , ) o f (x1 , ..., xn , ) sern, en general, muy complejas. Sin embargo, en el caso de tener una muestra aleatoria simple, su clculo es muy sencillo. Al ser una muestra independiente se puede demostrar que la funcin de probabilidad o densidad conjunta es el producto de las univariantes p(x1 , ..., xn ) = f (x1 , ..., xn ) =
n Y
p(xi ) = f (xi ) =
i=1 n Y i=1
i=1 n Y
n Y
p(xi , ) f (xi , )
i=1
La demostracin de este resultado no es sencilla y la omitiremos. Por ejemplo, usando la informacin del Ejemplo 6 anterior se tiene Pn n i=1 x2 4n 1 Y 2 i f (xi ) = n/2 3n , x exp f (x1 , ..., xn ) = i=1 i 2 i=1
n Y
5.7.3.
La funcin de verosimilitud
Las funciones p(x1 , ..., xn , ) y f (x1 , ..., xn , ) pueden utilizarse de dos formas distintas. Por una parte las podemos utilizar para, a partir de unos valores concretos de obtener una funcin que de valores diferentes en muestras diferentes. Es decir p(x1 , ..., xn |) o f (x1 , ..., xn |). De esta forma podremos calcular la probabilidad o densidad de unas muestras u otras para cada . Esta es precisamente la forma en que hemos utilizado estas funciones hasta ahora. Sin embargo, lo que nosotros necesitamos es justo la utilizacin inversa: dada una muestra que consideraremos ya ja, observada, obtener el valor de que maximiza dichas funciones, es decir p(|x1 , ..., xn ) o f (|x1 , ..., xn ). Estas funciones sern las mismas que las anteriores, slo estamos cambiando la forma de usarlas. Cuando a la funcin de probabilidad o de densidad conjuntas las usamos de esta manera les llamaremos Funcin de Verosimilitud l(). La funcin de verosimilitud nos proporciona, para una muestra dada, la verosimilitud de cada valor del parmetro. Por ejemplo, usando la informacin del Ejemplo 6 de la velocidad de una molcula se tiene la funcin de verosimilitud siguiente l() = Pn n i=1 x2 4n 1 Y 2 i . x exp 2 n/2 3n i=1 i
sta ser la funcin que tendremos que maximizar para consegir un estimador de .
5.7.4.
El mtodo de mxima verosimilitud
Maximizar l() a veces puede ser complicado. En el ejemplo anterior tenemos que l() es una funcin no lineal de . Hay en el denominador, con potencias, e incluso dentro de una exponencial. Con frecuencia suele ser ms sencillo maximizar ln(l()) que l(). Como el logaritmo es una funcin montona, el mximo de ln(l()) y el de l() se darn para el mismo valor de . Llamaremos funcin soporte a L() = ln(l()).
18
CAPTULO 5. INTRODUCCIN A LA INFERENCIA ESTADSTICA
Siguiendo con el ejemplo anterior de la velocidad de una molcula, se tiene la siguiente funcin soporte: Pn x2 i L() = k 3n log i=1 . (5.5) 2 Podemos ya aplicar el mtodo de mxima verosimilitud. El estimador de mxima verosimilitud de lo denotaremos por MV y ser el mximo de L(), es decir ax L(). MV = arg m Si lo aplicamos a nuestro ejemplo de la ecuacin de Maxwell para la velocidad de una molcula, derivaremos la funcin soporte (5.5). Se obtiene Pn dL 3n 2 i=1 x2 i = + 3 d dL = 0 d = MV y resolviendo esta ecuacin se halla el estimador mximo verosmil de : r Pn 2 2 i=1 Xi MV = . 3n
. De esta forma, a partir de una muestra X1 , ..., Xn podemos tener un valor de
5.7.5.
Propiedades de los estimadores de mxima verosimilitud
Los estimadores de mxima verosimilitud verican: Son insesgados, o asintticamente insesgados Son asintticamente ecientes (de menor error cuadrtico medio) Son asintticamente normales Su varianza asinttica es 1 2 L() Var(MV ) = 2 1
Utilizando el ejemplo anerior tenemos que Var( MV ) = como d2 L d2 ,
P 2 3n2 6 n d2 L i=1 xi = , d2 4 Var( MV ) = 6 P 4 2 3n2 . Xi
5.7. EL MTODO DE MXIMA VEROSIMILITUD
19
sustituyendo por MV y operando se obtiene un estimador de esta varianza asinttica: d ( Var M V ) = P 4 MV 2 3n Xi 2 MV
Ejemplo 7 Veamos otro ejemplo. Queremos estimar el parmetro p de una variable aleatoria binomial X B (n, p), a partir de la muestra X1 , ..., XN , donde Xi es el nmero de sucesos observados, en la muestra i-sima, de tamao n (tenemos N datos, basados en n elementos cada uno). Por ejemplo, nmero de artculos defectuosos en el lote i-simo de n artculos, de un total de N lotes. La funcin de probabilidad es n xi p (1 p)nxi . P (Xi = xi ) = xi La funcin de verosimilitud ser l(p) =
N Y n
2 d ( Var MV ) = MV . 6n
i=1
xi
pxi (1 p)nxi =
n x1
P P n n p xi (1 p) (nxi ) x2 xN !
y la funcin soporte: L(p) = cte + Derivando respecto a p tenemos dL dp = = y particularizando para p MV tenemos PN
i=1
N X
i=1
xi
ln p +
N X
i=1
(n xi ) ln(1 p).
(n xi ) 1p PN PN N n i=1 xi i=1 xi p 1p
i=1
PN
xi
PN
i=1
xi
PN Por tanto
i=1
xi p MV
PN
p MV
MV i=1 xi N np p MV (1 p MV )
PN N n i=1 xi 1p MV PN + i=1 xi p MV PN
i=1
= 0 = 0
Xi Nn i=1 PN que es la proporcin muestral de artculos defectuosos, pues i=1 Xi es el nmero de artculos defectuosos encontrados en la N muestras, y N n es el nmero total de artculos analizados. Vemos que el resultado es el mismo que con el mtodo de los momentos. xi N np MV = 0 p MV =
N X
You might also like
- Actividad I - Diagrama de Dispersión y Coeficiente de Correlación.Document5 pagesActividad I - Diagrama de Dispersión y Coeficiente de Correlación.karla C100% (1)
- Deber 9 Distribución Uniforme y NormalDocument3 pagesDeber 9 Distribución Uniforme y NormalAlejo Castro50% (2)
- Intervalo de Confianza para La Varianza Ejercicios ResueltosDocument3 pagesIntervalo de Confianza para La Varianza Ejercicios ResueltosHumberto Ramos50% (12)
- MSA-Webinar Feb 2022Document27 pagesMSA-Webinar Feb 2022Marisol RubioNo ratings yet
- Tablas MooreDocument6 pagesTablas MooreyouisNo ratings yet
- Prob InferGrandesDocument6 pagesProb InferGrandesElMisterioDeCalendaNo ratings yet
- Prob VAleatoriasDocument8 pagesProb VAleatoriasElMisterioDeCalendaNo ratings yet
- Prob ProbabilidadDocument4 pagesProb ProbabilidadElMisterioDeCalendaNo ratings yet
- Prob InferNormalDocument3 pagesProb InferNormalElMisterioDeCalendaNo ratings yet
- Prob IntroInferDocument5 pagesProb IntroInferElMisterioDeCalendaNo ratings yet
- Prob ModelosDocument9 pagesProb ModelosElMisterioDeCalendaNo ratings yet
- Prob DescriptivaDocument10 pagesProb DescriptivaElMisterioDeCalendaNo ratings yet
- Pres ProbabilidadDocument40 pagesPres ProbabilidadElMisterioDeCalendaNo ratings yet
- Pres ValeatoriasDocument55 pagesPres ValeatoriasElMisterioDeCalendaNo ratings yet
- Prob CalidadDocument7 pagesProb CalidadElMisterioDeCalendaNo ratings yet
- Prob ComparaPoblDocument3 pagesProb ComparaPoblElMisterioDeCalendaNo ratings yet
- Pres IntroInferDocument46 pagesPres IntroInferElMisterioDeCalendaNo ratings yet
- Pres ModelosDocument59 pagesPres ModelosElMisterioDeCalendaNo ratings yet
- Pres ComparaPoblDocument32 pagesPres ComparaPoblElMisterioDeCalendaNo ratings yet
- Apuntes VAleatoriasDocument20 pagesApuntes VAleatoriasElMisterioDeCalendaNo ratings yet
- Pres EstDescriptivaDocument94 pagesPres EstDescriptivaElMisterioDeCalendaNo ratings yet
- Pres InferNormalDocument26 pagesPres InferNormalElMisterioDeCalendaNo ratings yet
- Pres InferGrandesDocument58 pagesPres InferGrandesElMisterioDeCalendaNo ratings yet
- Pres CalidadDocument89 pagesPres CalidadElMisterioDeCalendaNo ratings yet
- Apuntes InferNormalDocument13 pagesApuntes InferNormalElMisterioDeCalendaNo ratings yet
- Apuntes ProbabilidadDocument15 pagesApuntes ProbabilidadElMisterioDeCalendaNo ratings yet
- Apuntes ModelosDocument22 pagesApuntes ModelosElMisterioDeCalendaNo ratings yet
- Apuntes EstDescriptivaDocument43 pagesApuntes EstDescriptivaElMisterioDeCalendaNo ratings yet
- Apuntes CalidadDocument36 pagesApuntes CalidadElMisterioDeCalendaNo ratings yet
- Apuntes InferGrandesDocument24 pagesApuntes InferGrandesElMisterioDeCalendaNo ratings yet
- Apuntes ComparaPoblDocument19 pagesApuntes ComparaPoblElMisterioDeCalendaNo ratings yet
- Apuntes CalidadDocument36 pagesApuntes CalidadElMisterioDeCalendaNo ratings yet
- TuringDocument15 pagesTuringElMisterioDeCalendaNo ratings yet
- 1expocicion de Teori de ProbabilidadesDocument8 pages1expocicion de Teori de ProbabilidadesJose LuisNo ratings yet
- GeologiaDocument27 pagesGeologiaJoseNo ratings yet
- Prieto Acosta Angie Jeannekarla, Velasquez Cuestas Luisa Fernanda 2016Document172 pagesPrieto Acosta Angie Jeannekarla, Velasquez Cuestas Luisa Fernanda 2016Elsa Ximena Chalan GualanNo ratings yet
- Ejercicios de La Esperanza Matemática..Document11 pagesEjercicios de La Esperanza Matemática..RosDel SanchezNo ratings yet
- Caso Práctico Unidad3 - EstadisticaDocument9 pagesCaso Práctico Unidad3 - EstadisticaAndresNo ratings yet
- Taller - Libey Garcia - 20192197077Document9 pagesTaller - Libey Garcia - 20192197077Libey Garcia BohorquezNo ratings yet
- Weibull Matlab Paso A PasoDocument12 pagesWeibull Matlab Paso A PasoNormitaMiaCasTroNo ratings yet
- Prueba de Diagnostico 3º MedioDocument7 pagesPrueba de Diagnostico 3º MedioCatherine Lobos MendezNo ratings yet
- Tarea 3 PYE115 2022Document6 pagesTarea 3 PYE115 2022dindo0% (1)
- Mate 1252Document11 pagesMate 1252Carlos CarantónNo ratings yet
- Tarea 2 Estadistica AplicadaDocument8 pagesTarea 2 Estadistica AplicadaannjelNo ratings yet
- Diseno Bloques Completo RandomizadoDocument18 pagesDiseno Bloques Completo RandomizadoLuis Castro Aguilar100% (2)
- Laboratorio Ii Pac 2021Document43 pagesLaboratorio Ii Pac 2021stephany corrales100% (3)
- Tarea4.2 - PrácticasTema4 - Jose Gutierrez PDFDocument128 pagesTarea4.2 - PrácticasTema4 - Jose Gutierrez PDFJuan AgustínNo ratings yet
- EjerciciosDocument86 pagesEjerciciosSILVANA CASTILLO MENESESNo ratings yet
- AsignaturaDocument10 pagesAsignaturaAndy Brayan Ninacondor CNo ratings yet
- Analisis Descriptivo de Datos Con Correcciones de ActualidadDocument22 pagesAnalisis Descriptivo de Datos Con Correcciones de Actualidadjimer sayagoNo ratings yet
- Ejercicio 4Document2 pagesEjercicio 4Andrés Felipe Maestre MielesNo ratings yet
- Probabilidad 1Document17 pagesProbabilidad 1MONICA LILIANA SANDOVAL MARTINEZ100% (1)
- Formulario Control de Calidad 2parcialDocument2 pagesFormulario Control de Calidad 2parcialJhonny Zurita GonzalesNo ratings yet
- Cuestionarios de EstadisticaDocument18 pagesCuestionarios de EstadisticaAndrea J. Elli OsunaNo ratings yet
- Modulo de ProbabilidadDocument128 pagesModulo de Probabilidadadriana villegasNo ratings yet
- Sel 2023-2024-Orientaciones Matematicas AplicadasDocument12 pagesSel 2023-2024-Orientaciones Matematicas Aplicadaslauramontero026No ratings yet
- Estadígrafos de Dispersión 1Document35 pagesEstadígrafos de Dispersión 1Sergio Sivila PizarroNo ratings yet
- Espe Electronica EXCT MVU42 Estadistica Descriptiva TECDocument3 pagesEspe Electronica EXCT MVU42 Estadistica Descriptiva TECuitNo ratings yet
- Teorica 4 Procesos de BernoulliDocument25 pagesTeorica 4 Procesos de BernoulliMati MenisNo ratings yet