You might also like
- Excerpt-from-UVS-Part-2-Powers-of-the-Vibrational-Bands Vesica PiscisDocument10 pagesExcerpt-from-UVS-Part-2-Powers-of-the-Vibrational-Bands Vesica PiscishaimkichikNo ratings yet
- Mystical Shaman Oracle CardsDocument161 pagesMystical Shaman Oracle CardsBiodanza Pamela Ubeda Cid100% (10)
- The Satisfiability Problem: Cook's Theorem: An NP-Complete Problem Restricted SAT: CSAT, 3SATDocument44 pagesThe Satisfiability Problem: Cook's Theorem: An NP-Complete Problem Restricted SAT: CSAT, 3SATLalalalalalaNo ratings yet
- 6 - 3 - 22. Specific NP-complete Problems (33 Min.)Document13 pages6 - 3 - 22. Specific NP-complete Problems (33 Min.)LalalalalalaNo ratings yet
- 22 pnp3Document37 pages22 pnp3LalalalalalaNo ratings yet
- 6 - 1 - 20. P and NP (25 Min.)Document10 pages6 - 1 - 20. P and NP (25 Min.)LalalalalalaNo ratings yet
- 22 pnp3Document37 pages22 pnp3LalalalalalaNo ratings yet
- Keepers of The Light Oracle CardsDocument131 pagesKeepers of The Light Oracle Cardslina89% (28)
- Past Life Oracle Cards GuidebookDocument56 pagesPast Life Oracle Cards GuidebookNhi Chan Canh66% (62)
- The Satisfiability Problem: Cook's Theorem: An NP-Complete Problem Restricted SAT: CSAT, 3SATDocument44 pagesThe Satisfiability Problem: Cook's Theorem: An NP-Complete Problem Restricted SAT: CSAT, 3SATLalalalalalaNo ratings yet
- PNP 1Document28 pagesPNP 1GauriNo ratings yet
- PNP 1Document28 pagesPNP 1GauriNo ratings yet
- 19 tm4Document60 pages19 tm4LalalalalalaNo ratings yet
- 6 - 2 - 21. Satisfiability and Cook's Theorem (44 Min.)Document16 pages6 - 2 - 21. Satisfiability and Cook's Theorem (44 Min.)LalalalalalaNo ratings yet
- 18 tm3Document26 pages18 tm3LalalalalalaNo ratings yet
- 18 tm3Document26 pages18 tm3LalalalalalaNo ratings yet
- Turing Machines Programming TricksDocument54 pagesTuring Machines Programming TricksLalalalalalaNo ratings yet
- More Undecidable Problems: Rice's Theorem Post's Correspondence Problem Some Real ProblemsDocument60 pagesMore Undecidable Problems: Rice's Theorem Post's Correspondence Problem Some Real ProblemsLalalalalalaNo ratings yet
- Turing Machines Programming TricksDocument54 pagesTuring Machines Programming TricksLalalalalalaNo ratings yet
- 5 - 3 - 19. Specific Undecidable Problems (56 Min.)Document20 pages5 - 3 - 19. Specific Undecidable Problems (56 Min.)LalalalalalaNo ratings yet
- 5 - 2 - 18. Decidability (18 Min.)Document7 pages5 - 2 - 18. Decidability (18 Min.)LalalalalalaNo ratings yet
- Pumping Lemma for CFLsDocument14 pagesPumping Lemma for CFLsLalalalalalaNo ratings yet
- 5 - 1 - 17. Extensions and Properties of Turing Machines (37 Min.)Document14 pages5 - 1 - 17. Extensions and Properties of Turing Machines (37 Min.)LalalalalalaNo ratings yet
- Properties of Context-Free Languages: Decision Properties Closure PropertiesDocument35 pagesProperties of Context-Free Languages: Decision Properties Closure PropertiesLalalalalalaNo ratings yet
- Conversion of CFG To PDA Conversion of PDA To CFGDocument23 pagesConversion of CFG To PDA Conversion of PDA To CFGLalalalalalaNo ratings yet
- Properties of Context-Free Languages: Decision Properties Closure PropertiesDocument35 pagesProperties of Context-Free Languages: Decision Properties Closure PropertiesLalalalalalaNo ratings yet
- Pumping Lemma for CFLsDocument14 pagesPumping Lemma for CFLsLalalalalalaNo ratings yet
- 13 Pda2Document23 pages13 Pda2LalalalalalaNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- GRAMMAR Relative ClausesDocument16 pagesGRAMMAR Relative ClausesDiego MoraNo ratings yet
- Introduction To IEEE P1687/IJTAG: (Full 7 Pages Here)Document1 pageIntroduction To IEEE P1687/IJTAG: (Full 7 Pages Here)krats23No ratings yet
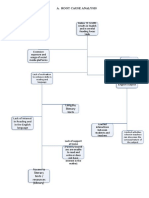
- Project REAP-Root Cause AnalysisDocument4 pagesProject REAP-Root Cause AnalysisAIRA NINA COSICONo ratings yet
- Paper 1 Comparative Commentary HLDocument1 pagePaper 1 Comparative Commentary HLapi-26226678683% (6)
- Humility in Prayer 2Document80 pagesHumility in Prayer 2Malik Saan BayramNo ratings yet
- Query Optimization With MySQL 8.0 and MariaDB 10.3 - The Basics - FileId - 160092 PDFDocument202 pagesQuery Optimization With MySQL 8.0 and MariaDB 10.3 - The Basics - FileId - 160092 PDFDwi Yulianto100% (1)
- Language Interrupted Signs of Non Native Acquisition in Standard Language Grammars PDFDocument332 pagesLanguage Interrupted Signs of Non Native Acquisition in Standard Language Grammars PDFjuramentatdo00No ratings yet
- Spanish SyllabusDocument7 pagesSpanish SyllabusKelsey LoontjerNo ratings yet
- 1920-2-PR1-Lesson 4Document30 pages1920-2-PR1-Lesson 4Ivy MuñozNo ratings yet
- Hbsc2203 - v2 - Tools of Learning of SciencesDocument10 pagesHbsc2203 - v2 - Tools of Learning of SciencesSimon RajNo ratings yet
- Sunday Worship ServiceDocument19 pagesSunday Worship ServiceKathleen OlmillaNo ratings yet
- IEO English Sample Paper 1 For Class 12Document37 pagesIEO English Sample Paper 1 For Class 12Santpal KalraNo ratings yet
- Introduction To Set Theory: Mr. Sanjay ShuklaDocument90 pagesIntroduction To Set Theory: Mr. Sanjay ShuklaUltramicNo ratings yet
- Completing Sentences Using Given WordsDocument4 pagesCompleting Sentences Using Given WordsTante DeviNo ratings yet
- Spare Part List - GF - NBG 150-125-315Document40 pagesSpare Part List - GF - NBG 150-125-315LenoiNo ratings yet
- OpenText Documentum Content Server 7.3 Administration and Configuration GuideDocument580 pagesOpenText Documentum Content Server 7.3 Administration and Configuration Guidedoaa faroukNo ratings yet
- Understanding homophones through prefixes, suffixes and root wordsDocument28 pagesUnderstanding homophones through prefixes, suffixes and root wordsAndreea LuluNo ratings yet
- תרגיל 2Document2 pagesתרגיל 2Kita MolNo ratings yet
- Voz Pasiva en InglésDocument5 pagesVoz Pasiva en InglésJose CastilloNo ratings yet
- 7 C's of Business LetterDocument3 pages7 C's of Business LetterGladys Forte100% (2)
- Kisi-Kisi Soal - KD 3.1 - KD 4.1 - Kls XiiDocument14 pagesKisi-Kisi Soal - KD 3.1 - KD 4.1 - Kls Xiisinyo201060% (5)
- Swift Level 1Document49 pagesSwift Level 1AceNo ratings yet
- Self Review CommentaryDocument3 pagesSelf Review CommentaryAdlinNo ratings yet
- Islamic StudiesDocument7 pagesIslamic StudiesShafeeq HakeemNo ratings yet
- MavenDocument28 pagesMavenniraj chavhanNo ratings yet
- English Model Test 1 10Document20 pagesEnglish Model Test 1 10wahid_040No ratings yet
- How To Get A High Score in IELTS WritingDocument16 pagesHow To Get A High Score in IELTS Writingpuji4nggr4eniNo ratings yet
- Hebrew To Kikongo Part 2Document63 pagesHebrew To Kikongo Part 2S Scott100% (1)
- Judd-Ofelt Theory in A New Light On Its (Almost) 40 AnniversaryDocument7 pagesJudd-Ofelt Theory in A New Light On Its (Almost) 40 AnniversaryMalek BombasteinNo ratings yet
- Form 3 Ar2 Speaking Exam PaperDocument5 pagesForm 3 Ar2 Speaking Exam PaperGrace WongNo ratings yet