You might also like
- CS1Ah Lecture Note 20 Recursion and Stacks: 20.1 The Towers of HanoiDocument4 pagesCS1Ah Lecture Note 20 Recursion and Stacks: 20.1 The Towers of HanoientewasteNo ratings yet
- Fixed points and diagonal arguments in category theoryDocument11 pagesFixed points and diagonal arguments in category theoryΓιάννης ΣτεργίουNo ratings yet
- Recursion and StacksDocument4 pagesRecursion and StacksqwedcfNo ratings yet
- Chapter 6 - StackDocument8 pagesChapter 6 - StackDifferent AngleNo ratings yet
- Data Structures AssDocument11 pagesData Structures AssFiraol TesfayeNo ratings yet
- Stacks: A Last-In First-Out Data StructureDocument18 pagesStacks: A Last-In First-Out Data StructureNikhil KotagiriNo ratings yet
- Stacks and Queues: Limited Access Data StructuresDocument6 pagesStacks and Queues: Limited Access Data StructuresRatulNo ratings yet
- MITOCW - MITRES2 - 002s10nonlinear - Lec12 - 300k-mp4: NarratorDocument16 pagesMITOCW - MITRES2 - 002s10nonlinear - Lec12 - 300k-mp4: NarratorBastian DewiNo ratings yet
- Problem: Suppose That For EachDocument13 pagesProblem: Suppose That For EachRaymundo CedanoNo ratings yet
- Chapter06 PDFDocument20 pagesChapter06 PDFAbdela Aman MtechNo ratings yet
- CSCI 3104 Longest Increasing Subsequence AlgorithmDocument3 pagesCSCI 3104 Longest Increasing Subsequence AlgorithmModernZenNo ratings yet
- Quick way to prove a set is countableDocument3 pagesQuick way to prove a set is countableHimraj BachooNo ratings yet
- QueueDocument55 pagesQueueNewNo ratings yet
- CS2040_Tutorial3_AnsDocument7 pagesCS2040_Tutorial3_Ansjoanna tayNo ratings yet
- Bubble SortDocument10 pagesBubble SortGiezel RevisNo ratings yet
- Lecture2-PropositionalDeductionDocument3 pagesLecture2-PropositionalDeductionAthulNo ratings yet
- Vuckovac Unpredictability ADocument10 pagesVuckovac Unpredictability ASaif HasanNo ratings yet
- MIT Problem Set 4 Solutions for Introduction to AlgorithmsDocument5 pagesMIT Problem Set 4 Solutions for Introduction to Algorithmsrully1234No ratings yet
- Strategies For Deduction: Part I: Rules and ToolsDocument34 pagesStrategies For Deduction: Part I: Rules and ToolsĐang Muốn ChếtNo ratings yet
- DSA Stacks Lecture: Abstract Data Types, Interfaces, ExceptionsDocument34 pagesDSA Stacks Lecture: Abstract Data Types, Interfaces, ExceptionsKamesh Singh JadounNo ratings yet
- Chapter 3 NotesDocument34 pagesChapter 3 NotesNoreen YinNo ratings yet
- Stack Compiled NoteDocument9 pagesStack Compiled NotesyabseeshoesNo ratings yet
- Data Structures SampleDocument8 pagesData Structures SampleHebrew JohnsonNo ratings yet
- Solution: Struct Nodetype (Itemtype Info Nodetype Next )Document3 pagesSolution: Struct Nodetype (Itemtype Info Nodetype Next )mahir ChowdhuryNo ratings yet
- Abstract Data StructureDocument18 pagesAbstract Data StructureVedant PatilNo ratings yet
- .4.2 Optimal Solution For TSP Using Branch and Bound: PrincipleDocument14 pages.4.2 Optimal Solution For TSP Using Branch and Bound: Principleleeza_goyalNo ratings yet
- Ans CH08Document8 pagesAns CH08Felipe VergaraNo ratings yet
- 3.1 Why Boolean Algebra?Document18 pages3.1 Why Boolean Algebra?Giri PrasadNo ratings yet
- Bubble SortDocument9 pagesBubble SortMohammed GhNo ratings yet
- Bubble Sort Cocktail Sort: A Group Project On Fundamentals of Computing 1Document13 pagesBubble Sort Cocktail Sort: A Group Project On Fundamentals of Computing 1Mariebeth SenoNo ratings yet
- Dsa VivaDocument9 pagesDsa VivaAnthony MooreNo ratings yet
- STARKs, Part II: Thank Goodness It's FRI-dayDocument8 pagesSTARKs, Part II: Thank Goodness It's FRI-dayRIYA SINGHNo ratings yet
- Solution Manual For Java Software Solutions For AP Computer Science A 2 e 2nd Edition John Lewis William Loftus Cara CockingDocument26 pagesSolution Manual For Java Software Solutions For AP Computer Science A 2 e 2nd Edition John Lewis William Loftus Cara CockingStevenRobertsonideo100% (35)
- Adaptive Resonance Theory (ART) : An Introduction by L.G. Heins & D.R. Tauritz May/June 1995Document15 pagesAdaptive Resonance Theory (ART) : An Introduction by L.G. Heins & D.R. Tauritz May/June 1995Chittineni Sai SandeepNo ratings yet
- Chapter-4. Stack & QueueDocument26 pagesChapter-4. Stack & QueueQuazi Hasnat IrfanNo ratings yet
- Solving N-queen and Josephus Problem using Backtracking, Stack and Queue respectivelyDocument22 pagesSolving N-queen and Josephus Problem using Backtracking, Stack and Queue respectivelyManan HudeNo ratings yet
- Turing ReducibilityDocument2 pagesTuring ReducibilityRahul ChatterjeeNo ratings yet
- Sorting ALGODocument5 pagesSorting ALGOSanketNo ratings yet
- Assissgment - 2 Topic:: Google'S Mehanicsim For Ranking Web Pages AimDocument7 pagesAssissgment - 2 Topic:: Google'S Mehanicsim For Ranking Web Pages AimBOGGARAPU KUSHALKUMAR 15MIS0446No ratings yet
- Stacks and QueueDocument17 pagesStacks and QueuemuralikonathamNo ratings yet
- Computer Science An Overview 12th Edition Brookshear Solutions Manual 1Document36 pagesComputer Science An Overview 12th Edition Brookshear Solutions Manual 1davidescobarjbgomrycit100% (26)
- Computer Science An Overview 12Th Edition Brookshear Solutions Manual Full Chapter PDFDocument30 pagesComputer Science An Overview 12Th Edition Brookshear Solutions Manual Full Chapter PDFtracy.wright772100% (10)
- Knowledge Representation and Logic - (Rule Based Systems) : Version 2 CSE IIT, KharagpurDocument14 pagesKnowledge Representation and Logic - (Rule Based Systems) : Version 2 CSE IIT, KharagpurVanu ShaNo ratings yet
- CH 4Document14 pagesCH 4Nazia EnayetNo ratings yet
- Assignment 2 by Roll No 44Document35 pagesAssignment 2 by Roll No 44Sailesh ArvapalliNo ratings yet
- Notes On Heap SortDocument16 pagesNotes On Heap SortLenin GangwalNo ratings yet
- ANALYSIS3: WED, SEP 11, 2013 Printed: September 12, 2013 (LEC# 3)Document11 pagesANALYSIS3: WED, SEP 11, 2013 Printed: September 12, 2013 (LEC# 3)ramboriNo ratings yet
- Stack and QueuesDocument24 pagesStack and Queuesmbr4v0vNo ratings yet
- Java Programming For BSC It 4th Sem Kuvempu UniversityDocument52 pagesJava Programming For BSC It 4th Sem Kuvempu UniversityUsha Shaw100% (1)
- W. D. Joyner - Mathematics of The RubikDocument80 pagesW. D. Joyner - Mathematics of The RubikpahelwanNo ratings yet
- Answers For AdsDocument16 pagesAnswers For Adsrajaprasad2No ratings yet
- Applications of StackDocument5 pagesApplications of StackKavishree RNo ratings yet
- Understanding Neural Networks From ScratchDocument15 pagesUnderstanding Neural Networks From Scratchsurajdhunna100% (1)
- SubtitleDocument3 pagesSubtitleHarshad BalajiNo ratings yet
- Microsoft Interview Questions & AnswersDocument3 pagesMicrosoft Interview Questions & Answersmwsfc3No ratings yet
- How Many Samples To Learn A Finite Class?Document4 pagesHow Many Samples To Learn A Finite Class?Muhammad Al KahfiNo ratings yet
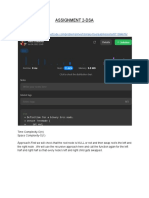
- Assignment 2-DSADocument5 pagesAssignment 2-DSAparul chaddhaNo ratings yet
- The Classes: P P P Pandnp NP NP NPDocument11 pagesThe Classes: P P P Pandnp NP NP NPtheresa.painterNo ratings yet
- Python Basic1Document25 pagesPython Basic1Gobara DhanNo ratings yet
- Step by Step Smart FormsDocument45 pagesStep by Step Smart FormscyberabadNo ratings yet
- Test2fall99 PDFDocument10 pagesTest2fall99 PDFGobara DhanNo ratings yet
- Abap ObjectsDocument35 pagesAbap ObjectsGobara DhanNo ratings yet
- Test 2 Spring 01Document11 pagesTest 2 Spring 01Gobara DhanNo ratings yet
- Owen Astrachan and Dee Ramm November 19, 1996Document11 pagesOwen Astrachan and Dee Ramm November 19, 1996Gobara DhanNo ratings yet
- CPS 100 Exam 2 Solutions Fall 2002Document18 pagesCPS 100 Exam 2 Solutions Fall 2002Gobara DhanNo ratings yet
- Function Modules in SAP ABAPDocument11 pagesFunction Modules in SAP ABAPGobara DhanNo ratings yet
- Most Frequently Asked Interview DIFFERENCES AbapDocument5 pagesMost Frequently Asked Interview DIFFERENCES AbapRıdvan YiğitNo ratings yet
- CPS 100 J. Forbes Fall 2001 Test #2: PROBLEM 1: (Drawing (10 Points) )Document4 pagesCPS 100 J. Forbes Fall 2001 Test #2: PROBLEM 1: (Drawing (10 Points) )Gobara DhanNo ratings yet
- BDC Program For Open Sales Order - SD (VA01)Document7 pagesBDC Program For Open Sales Order - SD (VA01)alronuNo ratings yet
- WD A complete+Example+with+ScreenshotsDocument29 pagesWD A complete+Example+with+ScreenshotsGobara DhanNo ratings yet
- Compsci 100 Test 2: Tree Problems and RecurrencesDocument9 pagesCompsci 100 Test 2: Tree Problems and RecurrencesGobara DhanNo ratings yet
- Test 2 Fall 98Document8 pagesTest 2 Fall 98Gobara DhanNo ratings yet
- Test 2 Fall 04Document16 pagesTest 2 Fall 04Gobara DhanNo ratings yet
- Test 2: Compsci 100: Owen Astrachan November 14, 2006Document17 pagesTest 2: Compsci 100: Owen Astrachan November 14, 2006Gobara DhanNo ratings yet
- Test 2 Fall 03 AnswersDocument8 pagesTest 2 Fall 03 AnswersGobara DhanNo ratings yet
- Test 2: Compsci 100: Owen Astrachan November 12, 2008Document10 pagesTest 2: Compsci 100: Owen Astrachan November 12, 2008Gobara DhanNo ratings yet
- Test 2 Fall 02Document7 pagesTest 2 Fall 02Gobara DhanNo ratings yet
- CPS 100 Test Sorts DNA Strands Using Insertion Sort and TreesDocument9 pagesCPS 100 Test Sorts DNA Strands Using Insertion Sort and TreesGobara DhanNo ratings yet
- Test 1 Spring 99Document7 pagesTest 1 Spring 99Gobara DhanNo ratings yet
- Test 2 e Fall 07 SolutionDocument6 pagesTest 2 e Fall 07 SolutionGobara DhanNo ratings yet
- Call Adobe Form Through ABAP Web DynproDocument47 pagesCall Adobe Form Through ABAP Web DynproGobara DhanNo ratings yet
- Test 2 Efall 07Document12 pagesTest 2 Efall 07Gobara DhanNo ratings yet
- CPS 100 Exam 1 Solutions and AnalysisDocument7 pagesCPS 100 Exam 1 Solutions and AnalysisGobara DhanNo ratings yet
- Test 1 Spring 94Document10 pagesTest 1 Spring 94Gobara DhanNo ratings yet
- Test 1 Spring 2010Document15 pagesTest 1 Spring 2010Gobara DhanNo ratings yet
- CPS 100 Test 1: Stack, Queue, Linked List, and Binary Tree ProblemsDocument9 pagesCPS 100 Test 1: Stack, Queue, Linked List, and Binary Tree ProblemsGobara DhanNo ratings yet
- Test 1 Spring 96Document8 pagesTest 1 Spring 96Gobara DhanNo ratings yet
- Test 1 Spring 95Document9 pagesTest 1 Spring 95Gobara DhanNo ratings yet
- RBT Knowledge DimensionDocument3 pagesRBT Knowledge Dimension5cr1bdNo ratings yet
- Data Structure (DS) Solved MCQ's With PDF Download (Set-2)Document8 pagesData Structure (DS) Solved MCQ's With PDF Download (Set-2)30. Suraj IngaleNo ratings yet
- Monitoring Loads Duration Flowcurve TutorialDocument35 pagesMonitoring Loads Duration Flowcurve TutorialmimahmoudNo ratings yet
- For Microsoft: Lexis Office Tip Sheet-Check Cite FormatDocument2 pagesFor Microsoft: Lexis Office Tip Sheet-Check Cite FormatMehboob UsmanNo ratings yet
- Chapter 6: Implementing Group Policy (Presentation)Document30 pagesChapter 6: Implementing Group Policy (Presentation)Muhammad Iqrash Awan100% (1)
- OOAD Lab Manual for CS2357 (CSE III YearDocument138 pagesOOAD Lab Manual for CS2357 (CSE III YearKarthik KeyanNo ratings yet
- All Digital FPGA Based Lock-In AmplifierDocument15 pagesAll Digital FPGA Based Lock-In AmplifiersastrakusumawijayaNo ratings yet
- Unit 5 PWCDocument29 pagesUnit 5 PWCGuru RockzzNo ratings yet
- Hao-Ran Lin, Bing-Yuan Cao, Yun-Zhang Liao (Auth.) - Fuzzy Sets Theory Preliminary - Can A Washing Machine Think - Springer International Publishing (2018)Document170 pagesHao-Ran Lin, Bing-Yuan Cao, Yun-Zhang Liao (Auth.) - Fuzzy Sets Theory Preliminary - Can A Washing Machine Think - Springer International Publishing (2018)gagah100% (2)
- Bluecat Networks Whitepaper - How To Integrate Active Directory and DNSDocument11 pagesBluecat Networks Whitepaper - How To Integrate Active Directory and DNSRahmiAmaliaNo ratings yet
- DVG 5121SPDocument3 pagesDVG 5121SPLalit AroraNo ratings yet
- Geodatabase Topology Rules and Topology Error FixeDocument29 pagesGeodatabase Topology Rules and Topology Error FixeRahul DekaNo ratings yet
- HRM - Knowledge ManagementDocument9 pagesHRM - Knowledge Managementcons theNo ratings yet
- Cell DirectoryDocument26 pagesCell DirectoryHussnain Azam Abdali100% (1)
- St. Martin's Engineering College covers software process maturity models in CMM, CMMI, and PCMMDocument45 pagesSt. Martin's Engineering College covers software process maturity models in CMM, CMMI, and PCMMtejaswini73% (22)
- AlphaGo Tutorial SlidesDocument16 pagesAlphaGo Tutorial SlidesDaniel Andrés CrespoNo ratings yet
- Sicso Networking Academy Chapter 6 v5Document6 pagesSicso Networking Academy Chapter 6 v5Sopheap SangNo ratings yet
- C++ NotesDocument144 pagesC++ NotesSuchit KumarNo ratings yet
- Processing of Satellite Image Using Digital Image ProcessingDocument21 pagesProcessing of Satellite Image Using Digital Image ProcessingSana UllahNo ratings yet
- Tax Does Not Calculate in R12 E-Business Tax (EBTAX)Document4 pagesTax Does Not Calculate in R12 E-Business Tax (EBTAX)msalahscribdNo ratings yet
- Numerical Analysis - MTH603 Handouts Lecture 21Document5 pagesNumerical Analysis - MTH603 Handouts Lecture 21roshanpateliaNo ratings yet
- Playboy Philippines Mocha Girls PDF 154Document4 pagesPlayboy Philippines Mocha Girls PDF 154Glen S. Reyes0% (2)
- Design Pattern Mock Test IDocument6 pagesDesign Pattern Mock Test IAhmad RamadanNo ratings yet
- 3com WX1200 DatasheetDocument646 pages3com WX1200 DatasheetTheerapong ChansopaNo ratings yet
- N FN DJFF NJ FKF HFDF KFH KDJFH Ehru U FHF SDFH Sduf H Eifdhsf DSFJKDSSDKF DSJDocument6 pagesN FN DJFF NJ FKF HFDF KFH KDJFH Ehru U FHF SDFH Sduf H Eifdhsf DSFJKDSSDKF DSJzuritovNo ratings yet
- Factors Behind Cost Differences in Similar Software ProductsDocument5 pagesFactors Behind Cost Differences in Similar Software ProductsMary Joy Paclibar BustamanteNo ratings yet
- Multimedia Project StagesDocument12 pagesMultimedia Project StagesMuhammad TahaNo ratings yet
- Eoffice TrainingDocument28 pagesEoffice TraininganantNo ratings yet
- RxControl ManualDocument77 pagesRxControl ManualMoni ZaNo ratings yet
- Paper Windy Aristiani PDFDocument8 pagesPaper Windy Aristiani PDFjasmineNo ratings yet
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- The Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!From EverandThe Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!Rating: 4.5 out of 5 stars4.5/5 (2)
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet
- Linux: The Ultimate Beginner's Guide to Learn Linux Operating System, Command Line and Linux Programming Step by StepFrom EverandLinux: The Ultimate Beginner's Guide to Learn Linux Operating System, Command Line and Linux Programming Step by StepRating: 4.5 out of 5 stars4.5/5 (9)
- Software Engineering at Google: Lessons Learned from Programming Over TimeFrom EverandSoftware Engineering at Google: Lessons Learned from Programming Over TimeRating: 4 out of 5 stars4/5 (11)
- Generative Art: A practical guide using ProcessingFrom EverandGenerative Art: A practical guide using ProcessingRating: 4 out of 5 stars4/5 (4)
- Introducing Python: Modern Computing in Simple Packages, 2nd EditionFrom EverandIntroducing Python: Modern Computing in Simple Packages, 2nd EditionRating: 4 out of 5 stars4/5 (7)
- Monitored: Business and Surveillance in a Time of Big DataFrom EverandMonitored: Business and Surveillance in a Time of Big DataRating: 4 out of 5 stars4/5 (1)
- Nine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersFrom EverandNine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersRating: 5 out of 5 stars5/5 (7)
- What Algorithms Want: Imagination in the Age of ComputingFrom EverandWhat Algorithms Want: Imagination in the Age of ComputingRating: 3.5 out of 5 stars3.5/5 (41)
- GROKKING ALGORITHMS: Simple and Effective Methods to Grokking Deep Learning and Machine LearningFrom EverandGROKKING ALGORITHMS: Simple and Effective Methods to Grokking Deep Learning and Machine LearningNo ratings yet
- CODING FOR ABSOLUTE BEGINNERS: How to Keep Your Data Safe from Hackers by Mastering the Basic Functions of Python, Java, and C++ (2022 Guide for Newbies)From EverandCODING FOR ABSOLUTE BEGINNERS: How to Keep Your Data Safe from Hackers by Mastering the Basic Functions of Python, Java, and C++ (2022 Guide for Newbies)No ratings yet
- Python Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsFrom EverandPython Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsRating: 3.5 out of 5 stars3.5/5 (54)
- Tiny Python Projects: Learn coding and testing with puzzles and gamesFrom EverandTiny Python Projects: Learn coding and testing with puzzles and gamesRating: 5 out of 5 stars5/5 (2)
- Python for Data Analysis: A Beginners Guide to Master the Fundamentals of Data Science and Data Analysis by Using Pandas, Numpy and IpythonFrom EverandPython for Data Analysis: A Beginners Guide to Master the Fundamentals of Data Science and Data Analysis by Using Pandas, Numpy and IpythonNo ratings yet