You might also like
- Records Management StagesDocument2 pagesRecords Management StagesChuck RothmanNo ratings yet
- Japanese Army's Fighting Vehicles (ModelArt 630) PDFDocument59 pagesJapanese Army's Fighting Vehicles (ModelArt 630) PDFChuck RothmanNo ratings yet
- Armour in Profile - 002 - PanzerKampfwagen VI Tiger 1 (H)Document12 pagesArmour in Profile - 002 - PanzerKampfwagen VI Tiger 1 (H)Chuck Rothman100% (1)
- The E-Discovery Maturity Model The Electronic Discovery Reference ModelDocument2 pagesThe E-Discovery Maturity Model The Electronic Discovery Reference ModelChuck RothmanNo ratings yet
- The Growing Need For Mobile Device ArchivingDocument11 pagesThe Growing Need For Mobile Device ArchivingChuck RothmanNo ratings yet
- The False Dichotomy of RelevanceDocument5 pagesThe False Dichotomy of RelevanceChuck RothmanNo ratings yet
- IGC Native FormatDocument6 pagesIGC Native FormatChuck RothmanNo ratings yet
- Preservation Case LawDocument38 pagesPreservation Case LawChuck Rothman100% (1)
- Blair and Maron - 1985 - An Evaluation of Retrieval Effectiveness For A Full-Text Document-Retrieval SystemDocument11 pagesBlair and Maron - 1985 - An Evaluation of Retrieval Effectiveness For A Full-Text Document-Retrieval SystemChuck RothmanNo ratings yet
- Armour in Profile - 006 - M24 ChaffeeDocument12 pagesArmour in Profile - 006 - M24 ChaffeeChuck RothmanNo ratings yet
- 10 - Chenillette LorraineDocument12 pages10 - Chenillette LorraineTxapilla Sb100% (2)
- British and Commonwealth Armoured Formations 1919-46Document106 pagesBritish and Commonwealth Armoured Formations 1919-46csosus100% (6)
- SocialMedia Ediscovery LexisNexisDocument20 pagesSocialMedia Ediscovery LexisNexisChuck RothmanNo ratings yet
- The Discovry Process Should Account For Iterative Search StrategyDocument2 pagesThe Discovry Process Should Account For Iterative Search StrategyChuck RothmanNo ratings yet
- Semantic Search in E-DiscoveryDocument4 pagesSemantic Search in E-DiscoveryChuck RothmanNo ratings yet
- Seriosity White Paper - Information OverloadDocument17 pagesSeriosity White Paper - Information OverloadChuck RothmanNo ratings yet
- Search Vs Culling StudyDocument10 pagesSearch Vs Culling StudyChuck RothmanNo ratings yet
- Social Networks and EdiscoveryDocument3 pagesSocial Networks and EdiscoveryChuck RothmanNo ratings yet
- Sampling - The Key To Process ValidationDocument3 pagesSampling - The Key To Process ValidationChuck RothmanNo ratings yet
- Retrospective and Prospective Statistical Sampling in Legal DiscoveryDocument9 pagesRetrospective and Prospective Statistical Sampling in Legal DiscoveryChuck RothmanNo ratings yet
- Law Technology News - Harvesting Evidence From The Sea of Text MessagesDocument4 pagesLaw Technology News - Harvesting Evidence From The Sea of Text MessagesChuck RothmanNo ratings yet
- Predictive ReviewDocument4 pagesPredictive ReviewChuck RothmanNo ratings yet
- Email Stats Report Exec SummaryDocument5 pagesEmail Stats Report Exec SummaryChuck RothmanNo ratings yet
- Planning For Variation and E-Discovery CostsDocument4 pagesPlanning For Variation and E-Discovery CostsChuck RothmanNo ratings yet
- IT and RIMDocument2 pagesIT and RIMChuck RothmanNo ratings yet
- BakeOffs SolomonDocument7 pagesBakeOffs SolomonChuck RothmanNo ratings yet
- Once Is Not Enough: The Case For Using An Iterative Approach To Choosing and Applying Selection Criteria in DiscoveryDocument4 pagesOnce Is Not Enough: The Case For Using An Iterative Approach To Choosing and Applying Selection Criteria in DiscoveryChuck RothmanNo ratings yet
- Discovery of Related Terms in A Corpus Using Reflective Random IndexingDocument8 pagesDiscovery of Related Terms in A Corpus Using Reflective Random IndexingChuck RothmanNo ratings yet
- Cloud Ediscovery AutonomyDocument7 pagesCloud Ediscovery AutonomyChuck RothmanNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Unit 27: Solving Multi-Step EquationsDocument1 pageUnit 27: Solving Multi-Step EquationsweranNo ratings yet
- Modal Damping Estimation: An Alternative For Hilbert Spectral AnalysisDocument7 pagesModal Damping Estimation: An Alternative For Hilbert Spectral AnalysisMuhammad Hur RizviNo ratings yet
- Digital Signal Processing Systems, Basic Filtering Types, and Digital Filter RealizationsDocument21 pagesDigital Signal Processing Systems, Basic Filtering Types, and Digital Filter RealizationsmelkiNo ratings yet
- Classification of Word Levels With Usage Frequency, Expert Opinions and Machine LearningDocument5 pagesClassification of Word Levels With Usage Frequency, Expert Opinions and Machine Learningyahepan391No ratings yet
- Renewable and Sustainable Energy Reviews: Hegazy Rezk, Ahmed Fathy, Almoataz Y. AbdelazizDocument10 pagesRenewable and Sustainable Energy Reviews: Hegazy Rezk, Ahmed Fathy, Almoataz Y. AbdelazizDany ApablazaNo ratings yet
- 08 CFGDocument27 pages08 CFGshahwarNo ratings yet
- Fuzzification and Defuzzification 5Document27 pagesFuzzification and Defuzzification 5jyoti singh100% (1)
- CS 412 Intro. To Data MiningDocument55 pagesCS 412 Intro. To Data Miningshehzad AliNo ratings yet
- Computational Data Science: Advanced Programme inDocument15 pagesComputational Data Science: Advanced Programme inMA AgriNo ratings yet
- Ee5239 HW3-2Document8 pagesEe5239 HW3-2Sarthak JainNo ratings yet
- Multi-Tagging For Transition-Based Dependency ParsingDocument10 pagesMulti-Tagging For Transition-Based Dependency ParsingFreyja SigurgisladottirNo ratings yet
- Facebook - LeetCodeDocument20 pagesFacebook - LeetCodeNishit Attrey100% (2)
- 2.4 Select Life TableDocument11 pages2.4 Select Life Tablecaramel latteNo ratings yet
- International Journal of Mining Science and Technology: Yuanyuan Pu, Derek B. Apel, Victor Liu, Hani MitriDocument6 pagesInternational Journal of Mining Science and Technology: Yuanyuan Pu, Derek B. Apel, Victor Liu, Hani MitriColleen CallahanNo ratings yet
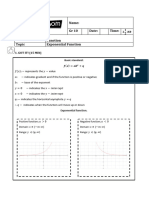
- gr10t2 Functions Exponential FunctionDocument6 pagesgr10t2 Functions Exponential FunctionaaronmaburutseNo ratings yet
- Saudi University CS Course Homework on Data Structures AlgorithmsDocument12 pagesSaudi University CS Course Homework on Data Structures AlgorithmshisadaNo ratings yet
- Looking For A Challenge 2 enDocument27 pagesLooking For A Challenge 2 enZaidNo ratings yet
- Hirbod Assa: Curriculum VitaeDocument9 pagesHirbod Assa: Curriculum Vitaeapi-352033253No ratings yet
- Optimum Structure Spotting & Optimum Pole Selector 14.1 Automatic Optimum Structure SpottingDocument1 pageOptimum Structure Spotting & Optimum Pole Selector 14.1 Automatic Optimum Structure Spottingsulav shresthaNo ratings yet
- TW 11 ADocument11 pagesTW 11 ASwapna ThoutiNo ratings yet
- Review 3 - Journal Submission Format: Team Number Title (New)Document28 pagesReview 3 - Journal Submission Format: Team Number Title (New)Ruchika SinghNo ratings yet
- Slide Case EDM03 - Group 3Document59 pagesSlide Case EDM03 - Group 3Dandza PradityaNo ratings yet
- ADDITION and MULTIPLICATIONDocument10 pagesADDITION and MULTIPLICATIONJan JosonNo ratings yet
- Regressao Linear Simples - Ipynb - ColaboratoryDocument2 pagesRegressao Linear Simples - Ipynb - ColaboratoryGestão Financeira Fatec Bragança100% (1)
- Highscore XRD Analysis Software GuideDocument3 pagesHighscore XRD Analysis Software GuideGanesh DongreNo ratings yet
- Feedforward ControlDocument73 pagesFeedforward ControlsathyaNo ratings yet
- Bisection Method PDFDocument24 pagesBisection Method PDFSyed Ali HaidarNo ratings yet
- Lesson 2 Arithmetic SequenceDocument27 pagesLesson 2 Arithmetic SequenceLady Ann LugoNo ratings yet
- Scalable Feature Learning for Networks with node2vecDocument30 pagesScalable Feature Learning for Networks with node2vecsiraj mohammedNo ratings yet
- 16.323 Principles of Optimal Control: Mit OpencoursewareDocument26 pages16.323 Principles of Optimal Control: Mit Opencoursewaremousa bagherpourjahromiNo ratings yet