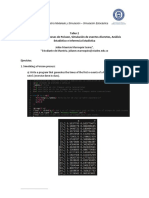
You might also like
- Grade 11 - Statistics and ProbabilityDocument9 pagesGrade 11 - Statistics and ProbabilityaminM197769% (36)
- Bootstrap UpDocument5 pagesBootstrap UpVijay BokadeNo ratings yet
- Lecture 9 PDFDocument22 pagesLecture 9 PDFTiago MartinsNo ratings yet
- R Chap3Document11 pagesR Chap3fatihy73No ratings yet
- Comparison of Resampling Method Applied To Censored DataDocument8 pagesComparison of Resampling Method Applied To Censored DataIlya KorsunskyNo ratings yet
- Generating random samples from user-defined distributionsDocument6 pagesGenerating random samples from user-defined distributionsNam LêNo ratings yet
- Bootstrapping Examples and CounterexamplesDocument63 pagesBootstrapping Examples and CounterexamplesJoe OgleNo ratings yet
- PTSP Lab RecordDocument27 pagesPTSP Lab RecordAnonymousNo ratings yet
- Unit 3 (SAMPLE AND SAMPLE DISTRIBUTIONS)Document32 pagesUnit 3 (SAMPLE AND SAMPLE DISTRIBUTIONS)Zara Nabilah100% (2)
- Random Variable & Probability DistributionDocument48 pagesRandom Variable & Probability DistributionRISHAB NANGIANo ratings yet
- An Introduction To The Bootstrap: Teaching Statistics May 2001Document7 pagesAn Introduction To The Bootstrap: Teaching Statistics May 2001Cyprian OmariNo ratings yet
- Introduction To Monte Carlo Procedures: The Non-Parametric and Parametric Bootstrap 1. Review of The Non-Parametric BootstrapDocument10 pagesIntroduction To Monte Carlo Procedures: The Non-Parametric and Parametric Bootstrap 1. Review of The Non-Parametric BootstrapFanny Sylvia C.100% (1)
- Bootstrap Methods for Estimating Standard Errors and Confidence IntervalsDocument7 pagesBootstrap Methods for Estimating Standard Errors and Confidence Intervalshytsang123No ratings yet
- Chapter 3 RadiationDocument36 pagesChapter 3 Radiationlilmadhu100% (1)
- Sampling & EstimationDocument19 pagesSampling & EstimationKumail Al KhuraidahNo ratings yet
- MIT18 05S14 Class24-Slde-ADocument16 pagesMIT18 05S14 Class24-Slde-AchiragNo ratings yet
- Application of The Bootstrap Method in The Site Characterization ProgramDocument14 pagesApplication of The Bootstrap Method in The Site Characterization ProgramSebestyén ZoltánNo ratings yet
- Gharamani PcaDocument8 pagesGharamani PcaLeonardo L. ImpettNo ratings yet
- Igual-SeguÃ2017_Chapter_StatisticalInferenceDocument15 pagesIgual-SeguÃ2017_Chapter_StatisticalInferenceBacem ChNo ratings yet
- Chapter 6: How to Do Forecasting Regression by AnalysisDocument7 pagesChapter 6: How to Do Forecasting Regression by AnalysisSarah Sally SarahNo ratings yet
- 03 Statistical Inference v0 0 22052022 050030pmDocument17 pages03 Statistical Inference v0 0 22052022 050030pmSaif ali KhanNo ratings yet
- Lecture On Sampling DistributionsDocument31 pagesLecture On Sampling DistributionsshahidanahmadNo ratings yet
- Project Costing With The Triangular Distribution and Moment MatchingDocument7 pagesProject Costing With The Triangular Distribution and Moment MatchingHamit AydınNo ratings yet
- XSTK Câu hỏiDocument19 pagesXSTK Câu hỏiimaboneofmyswordNo ratings yet
- CHAPTER 7 Sampling DistributionsDocument8 pagesCHAPTER 7 Sampling DistributionsPark MinaNo ratings yet
- Theta - A Framework For Template-Based Modeling and InferenceDocument28 pagesTheta - A Framework For Template-Based Modeling and InferenceShahzad AliNo ratings yet
- Error and Uncertainty: General Statistical PrinciplesDocument8 pagesError and Uncertainty: General Statistical Principlesdéborah_rosalesNo ratings yet
- 6.1 IntrodutionDocument3 pages6.1 IntrodutionSaĸυra HarυnoNo ratings yet
- Unlock Scilab13Document38 pagesUnlock Scilab13djatoyzNo ratings yet
- Fast and Robust Bootstrap for Multivariate Inference: The R Package FRBDocument32 pagesFast and Robust Bootstrap for Multivariate Inference: The R Package FRBD PNo ratings yet
- Bootstrap: Estimate Statistical UncertaintiesDocument22 pagesBootstrap: Estimate Statistical UncertaintiesChristian Holm ChristensenNo ratings yet
- Maxbox - Starter67 Machine LearningDocument7 pagesMaxbox - Starter67 Machine LearningMax KleinerNo ratings yet
- Nomor 3 UtsDocument6 pagesNomor 3 UtsNita FerdianaNo ratings yet
- Chapter 7Document15 pagesChapter 7Khay OngNo ratings yet
- Algorithms For Calculating VarianceDocument11 pagesAlgorithms For Calculating Varianceisabella343No ratings yet
- Statistical Estimation Methods in Hydrological EngineeringDocument41 pagesStatistical Estimation Methods in Hydrological EngineeringshambelNo ratings yet
- Estimation Through Bootstrapping Without Distributional AssumptionsDocument6 pagesEstimation Through Bootstrapping Without Distributional Assumptionsmayankmittal27No ratings yet
- Tutprac 1Document8 pagesTutprac 1Pham Truong Thinh LeNo ratings yet
- Detecting Multiple Outliers in Multivariate Samples With S-Estimation MethodDocument10 pagesDetecting Multiple Outliers in Multivariate Samples With S-Estimation MethodDen MAs KampretNo ratings yet
- Maestría Modelado y Simulación – Simulación Estocástica Taller 2Document10 pagesMaestría Modelado y Simulación – Simulación Estocástica Taller 2MAURICIOMS1982No ratings yet
- Statistics For Data SciencesDocument10 pagesStatistics For Data Sciencesgaldo2No ratings yet
- System Simulation and Modeling LabDocument23 pagesSystem Simulation and Modeling LabPavleen KaurNo ratings yet
- STATISTICSDocument8 pagesSTATISTICSmesfindukedomNo ratings yet
- Answers Review Questions EconometricsDocument59 pagesAnswers Review Questions EconometricsZX Lee84% (25)
- Maximum Likelihood Estimation by R: Instructor: Songfeng ZhengDocument5 pagesMaximum Likelihood Estimation by R: Instructor: Songfeng ZhengayushNo ratings yet
- Lecture 3 - Sampling-Distribution & Central Limit TheoremDocument5 pagesLecture 3 - Sampling-Distribution & Central Limit TheoremNilo Galvez Jr.No ratings yet
- Assignment On Estimating A Population Mean Course Title: Research Methodology Course Code: REM - 312Document10 pagesAssignment On Estimating A Population Mean Course Title: Research Methodology Course Code: REM - 312Mohammad Jewel RanaNo ratings yet
- Monte Carlo Experiments: Version: 4-10-2010, 20:37Document6 pagesMonte Carlo Experiments: Version: 4-10-2010, 20:37Mian AlmasNo ratings yet
- 6.sample-means-finalDocument13 pages6.sample-means-finaldorothyjoy103No ratings yet
- Computer Lab Tutorial 1 - Solutions: Statistics 2, Winter Semester 2021/22Document14 pagesComputer Lab Tutorial 1 - Solutions: Statistics 2, Winter Semester 2021/22SazaNo ratings yet
- Devore Ch. 1 Navidi Ch. 1Document16 pagesDevore Ch. 1 Navidi Ch. 1chinchouNo ratings yet
- CHAPTER 5 - Sampling Distributions Sections: 5.1 & 5.2: AssumptionsDocument9 pagesCHAPTER 5 - Sampling Distributions Sections: 5.1 & 5.2: Assumptionssound05No ratings yet
- Resampled Inference Resampled InferenceDocument21 pagesResampled Inference Resampled InferencedkbradleyNo ratings yet
- CooksDocument5 pagesCooksPatricia Calvo PérezNo ratings yet
- Point and Interval Estimation-26!08!2011Document28 pagesPoint and Interval Estimation-26!08!2011Syed OvaisNo ratings yet
- Problem Set #1Document6 pagesProblem Set #1cflores48No ratings yet
- Sampling DistributionDocument127 pagesSampling DistributionForsythe LearningNo ratings yet
- Statistical Inference Chapter 01Document71 pagesStatistical Inference Chapter 01Asra AsgharNo ratings yet
- Of Statistics Sampling Distribution Table Magsino, R. V. (2020) - Statistics and Probability Learner's MaterialDocument2 pagesOf Statistics Sampling Distribution Table Magsino, R. V. (2020) - Statistics and Probability Learner's MaterialJan RegenciaNo ratings yet
- Learn Statistics Fast: A Simplified Detailed Version for StudentsFrom EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsNo ratings yet
- FormulasDocument3 pagesFormulasLaura SerghiescuNo ratings yet
- Tel A 2012Document1 pageTel A 2012Laura SerghiescuNo ratings yet
- TGN ADocument1 pageTGN ALaura SerghiescuNo ratings yet
- European Central Bank - The EurosystemDocument36 pagesEuropean Central Bank - The Eurosystemdodge666No ratings yet
- Critical Value Tables: Z-Distribution TableDocument10 pagesCritical Value Tables: Z-Distribution TableAyush A. SinghalNo ratings yet
- Statistical TreatmentDocument22 pagesStatistical Treatmentzhahoneyjen ponioNo ratings yet
- IB Math AI SL Questionbank - ProbabilityDocument1 pageIB Math AI SL Questionbank - ProbabilityjuanfogedaNo ratings yet
- Probability & Statistics MCQsDocument17 pagesProbability & Statistics MCQsRohit SinghNo ratings yet
- Tuto 1 To 3 (Stats)Document27 pagesTuto 1 To 3 (Stats)Kelvin LeeNo ratings yet
- Stevenson 13e Chapter 10Document40 pagesStevenson 13e Chapter 10Harold WasinNo ratings yet
- Advanced Statistics and Probability-QADocument12 pagesAdvanced Statistics and Probability-QArawasthi29No ratings yet
- Study Guide 01Document4 pagesStudy Guide 01ldlewisNo ratings yet
- © 2011 Pearson Education, IncDocument41 pages© 2011 Pearson Education, IncSasi KumarNo ratings yet
- Written Report Stats 2 Project 1Document8 pagesWritten Report Stats 2 Project 1api-458912296No ratings yet
- TEST 3 Descriptive Statistics, Probability - SOLUTIONSDocument6 pagesTEST 3 Descriptive Statistics, Probability - SOLUTIONSX753No ratings yet
- LC M11 12SP-IVa-1Document20 pagesLC M11 12SP-IVa-1Jean S. FraserNo ratings yet
- Probability: S.S.HarichandanDocument137 pagesProbability: S.S.Harichandanamitkumar mohantyNo ratings yet
- Statistical Process Control (SPC)Document36 pagesStatistical Process Control (SPC)SYEDOUNMUHAMMAD ZAIDI100% (1)
- Assignment - 18 MAB 204T - PQT PDFDocument4 pagesAssignment - 18 MAB 204T - PQT PDFacasNo ratings yet
- Exercises in ProbabilityDocument11 pagesExercises in Probabilitysuhasnu deyNo ratings yet
- Biostatistics ReviewerDocument2 pagesBiostatistics ReviewerFil HynneyNo ratings yet
- Data Klorofil Spss KonversiDocument8 pagesData Klorofil Spss KonversiDestiAyuNo ratings yet
- 560-Article Text-2470-1-10-20200614Document13 pages560-Article Text-2470-1-10-20200614SILVIA GUNAWANNo ratings yet
- F-Test in Excel - EASY Excel TutorialDocument2 pagesF-Test in Excel - EASY Excel TutorialOsman AbhiNo ratings yet
- An Assignment of Case Study 12.1: (IIFT Mess and Dhaba Food) Submitted By: Name Roll. NoDocument5 pagesAn Assignment of Case Study 12.1: (IIFT Mess and Dhaba Food) Submitted By: Name Roll. NoKunal RajyaguruNo ratings yet
- UntitledDocument13 pagesUntitledAnalie MarceloNo ratings yet
- Levels of Measurement and Choosing The CDocument2 pagesLevels of Measurement and Choosing The Ccepc56No ratings yet
- Parameter and StatisticDocument15 pagesParameter and StatisticRakesh ChoudharyNo ratings yet
- STA 121 - Introduction to Probability Course OverviewDocument10 pagesSTA 121 - Introduction to Probability Course OverviewAbraham BanjoNo ratings yet
- 2010 AP Statistics Free Response SolutionsDocument3 pages2010 AP Statistics Free Response Solutionsvamsi_kcNo ratings yet
- Latihan statistika materi 5Document4 pagesLatihan statistika materi 5Agus HaryantoNo ratings yet
- Introduction To BiostatisticsDocument19 pagesIntroduction To BiostatisticsMuhammad ShahidNo ratings yet