You might also like
- John P. Nolan - Stable DistributionsDocument34 pagesJohn P. Nolan - Stable DistributionsDániel KincsesNo ratings yet
- Building Blocks For Theoretical Computer ScienceDocument268 pagesBuilding Blocks For Theoretical Computer ScienceDavid JamesNo ratings yet
- Lecture NotesDocument138 pagesLecture NotesAmine HadjiNo ratings yet
- STAT501 Multivariate AnalysisDocument196 pagesSTAT501 Multivariate AnalysislbenitesanchezNo ratings yet
- Thesis TemplateDocument42 pagesThesis TemplateAnđela TodorovićNo ratings yet
- Stat 378Document73 pagesStat 378MUHAMMAD ZEESHAN TARIQNo ratings yet
- R For Statistical LearningDocument301 pagesR For Statistical LearningNemNo ratings yet
- Dart Language SpecificationDocument123 pagesDart Language SpecificationSantiago Carmona LópezNo ratings yet
- Matlab NotesDocument189 pagesMatlab Notesbinghuan liNo ratings yet
- ANOVA3Document194 pagesANOVA3Yamou HMNo ratings yet
- ExercisesDocument69 pagesExercisesYehorNo ratings yet
- Making Sense of Data Statistic CourseDocument57 pagesMaking Sense of Data Statistic Coursewangx0800No ratings yet
- Ms 236 N 0Document63 pagesMs 236 N 0Amsalu WalelignNo ratings yet
- JB Ies 109 Exercises AnswersDocument246 pagesJB Ies 109 Exercises AnswersLaura GillisNo ratings yet
- Stat 331 Course NotesDocument79 pagesStat 331 Course NotesthemanzamanNo ratings yet
- Automatic Speech and Speaker Recognition: Large Margin and Kernel MethodsFrom EverandAutomatic Speech and Speaker Recognition: Large Margin and Kernel MethodsJoseph KeshetNo ratings yet
- 10 1 1 672 7118 PDFDocument35 pages10 1 1 672 7118 PDFkhikuNo ratings yet
- Bio Stat MethodsDocument592 pagesBio Stat MethodsPablo Calderón MartínezNo ratings yet
- Stat PDFDocument132 pagesStat PDFGerman ChiappeNo ratings yet
- MatrixcookbookDocument72 pagesMatrixcookbookBukaNo ratings yet
- Matrixcookbook PDFDocument72 pagesMatrixcookbook PDFeetahaNo ratings yet
- Z Thesis Erikboss FinalDocument49 pagesZ Thesis Erikboss FinalJanus FebriNo ratings yet
- ECE2191 Lecture NotesDocument106 pagesECE2191 Lecture NotesJason CruzNo ratings yet
- Risk-Efficient Portfolios Estimation Error in Essence PDFDocument69 pagesRisk-Efficient Portfolios Estimation Error in Essence PDFPetar ĆirkovićNo ratings yet
- Queueing SystemsDocument182 pagesQueueing SystemsКлара АндрееваNo ratings yet
- Patrick Siarry (Editor) - Metaheuristics-Springer (2016) PDFDocument497 pagesPatrick Siarry (Editor) - Metaheuristics-Springer (2016) PDFCarmen PeraltaNo ratings yet
- MiniZinc - Tutorial PDFDocument82 pagesMiniZinc - Tutorial PDFDavidNo ratings yet
- Introduction To Econometrics-64336113Document153 pagesIntroduction To Econometrics-64336113Minaw BelayNo ratings yet
- Notes LogicDocument93 pagesNotes LogicGernNo ratings yet
- Machine Learning and Data Mining University of TorontoDocument134 pagesMachine Learning and Data Mining University of TorontoDhruv KhannaNo ratings yet
- Aviation Propulsive Lithium-Ion Battery Packs State-Of-Charge andDocument96 pagesAviation Propulsive Lithium-Ion Battery Packs State-Of-Charge andAntonio BatataNo ratings yet
- An Introduction To The Usa Computing Olympiad: Darren YaoDocument87 pagesAn Introduction To The Usa Computing Olympiad: Darren YaocristianNo ratings yet
- Palamadai eDocument79 pagesPalamadai eAndony Reyes SánchezNo ratings yet
- Operations Research PDFDocument121 pagesOperations Research PDFravinderreddynNo ratings yet
- CAM625 2019 s1 Module1Document31 pagesCAM625 2019 s1 Module1Kelvin LeongNo ratings yet
- Stochastic Processes and Simulations - A Machine Learning PerspectiveDocument96 pagesStochastic Processes and Simulations - A Machine Learning Perspectivee2wi67sy4816pahnNo ratings yet
- Data Mining NotesDocument134 pagesData Mining NotesMalay ShikshaNo ratings yet
- Mathematical Finance: Hiroshi Toyoizumi September 26, 2012Document87 pagesMathematical Finance: Hiroshi Toyoizumi September 26, 2012Dewi Yuliana FitriNo ratings yet
- FULLTEXT01Document58 pagesFULLTEXT01jose pazNo ratings yet
- Probability StatisticsDocument125 pagesProbability StatisticsSunil ChoudharyNo ratings yet
- MultivariateDocument319 pagesMultivariateLucas Gallindo0% (1)
- Myhdl Manual: Release 0.11Document112 pagesMyhdl Manual: Release 0.11mehrNo ratings yet
- Programming in CsharpDocument175 pagesProgramming in CsharpSoumya Jyoti Bhattacharya100% (1)
- GeodezieDocument87 pagesGeodezieCodrutaNo ratings yet
- Stochastic Methods and their Applications to Communications: Stochastic Differential Equations ApproachFrom EverandStochastic Methods and their Applications to Communications: Stochastic Differential Equations ApproachNo ratings yet
- Basic Research and Technologies for Two-Stage-to-Orbit Vehicles: Final Report of the Collaborative Research Centres 253, 255 and 259From EverandBasic Research and Technologies for Two-Stage-to-Orbit Vehicles: Final Report of the Collaborative Research Centres 253, 255 and 259No ratings yet
- Simulation Statistical Foundations and MethodologyFrom EverandSimulation Statistical Foundations and MethodologyNo ratings yet
- Graphical Models: Representations for Learning, Reasoning and Data MiningFrom EverandGraphical Models: Representations for Learning, Reasoning and Data MiningNo ratings yet
- Quasi-Monte Carlo Methods in Finance: With Application to Optimal Asset AllocationFrom EverandQuasi-Monte Carlo Methods in Finance: With Application to Optimal Asset AllocationNo ratings yet
- Uncertainty Analysis with High Dimensional Dependence ModellingFrom EverandUncertainty Analysis with High Dimensional Dependence ModellingNo ratings yet
- Template Matching Techniques in Computer Vision: Theory and PracticeFrom EverandTemplate Matching Techniques in Computer Vision: Theory and PracticeNo ratings yet
- Semiparametric Regression for the Social SciencesFrom EverandSemiparametric Regression for the Social SciencesRating: 3 out of 5 stars3/5 (1)
- Financial Decisions and Markets: A Course in Asset PricingFrom EverandFinancial Decisions and Markets: A Course in Asset PricingRating: 4.5 out of 5 stars4.5/5 (6)
- Markov Processes and Applications: Algorithms, Networks, Genome and FinanceFrom EverandMarkov Processes and Applications: Algorithms, Networks, Genome and FinanceNo ratings yet
- Economic Report WeightingsDocument5 pagesEconomic Report Weightings951m753mNo ratings yet
- Syllabus 2006 Ebook PDFDocument29 pagesSyllabus 2006 Ebook PDF951m753m100% (1)
- Andrea Unger Asia Tour SlidesDocument72 pagesAndrea Unger Asia Tour Slides951m753m100% (2)
- 05 Consulting PathwayDocument42 pages05 Consulting Pathway951m753mNo ratings yet
- Johari WindowDocument9 pagesJohari Window951m753mNo ratings yet
- Understanding Your Inner SelfDocument12 pagesUnderstanding Your Inner Self951m753mNo ratings yet
- 15 10 0242 00 004g LDPC Code ProposalDocument7 pages15 10 0242 00 004g LDPC Code Proposal951m753mNo ratings yet
- Project: Ieee P802.15 Working Group For Wireless Personal Area Networks (Wpans)Document12 pagesProject: Ieee P802.15 Working Group For Wireless Personal Area Networks (Wpans)951m753mNo ratings yet
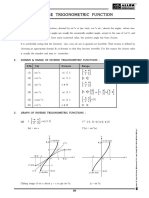
- Inverse Jeemain - GuruDocument32 pagesInverse Jeemain - GuruNeetu GuptaNo ratings yet
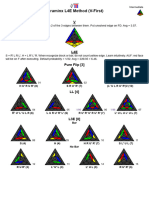
- Pyraminx L4E (V-First)Document2 pagesPyraminx L4E (V-First)tudorsebastian299No ratings yet
- General MathematicsDocument102 pagesGeneral MathematicsRaquel disomimbaNo ratings yet
- 2 ND UT Syllabus PDFDocument9 pages2 ND UT Syllabus PDFKillerrox GamingNo ratings yet
- 2.3. Venn Diagrams & Set OperationsDocument10 pages2.3. Venn Diagrams & Set OperationsJestin ManaloNo ratings yet
- Algorithmic Specified Complexity in The Game of LifeDocument11 pagesAlgorithmic Specified Complexity in The Game of LifeLelieth Martin CastroNo ratings yet
- Chapter 3 Differentiation - 2Document164 pagesChapter 3 Differentiation - 2dopeNo ratings yet
- Continuum MechanicsDocument1 pageContinuum MechanicsmurarivNo ratings yet
- Sobolev Gradients and Di Erential Equations: Author AddressDocument154 pagesSobolev Gradients and Di Erential Equations: Author AddresscocoaramirezNo ratings yet
- Kreyszig 10 PDFDocument328 pagesKreyszig 10 PDF박채연100% (1)
- Deathbound SubjectivityDocument109 pagesDeathbound SubjectivityAnonymous IfYLvzpmFeNo ratings yet
- Theory of Automata: Regular ExpressionsDocument43 pagesTheory of Automata: Regular ExpressionsHassan RazaNo ratings yet
- Hadamard Matrix Analysis and Synthesis With Applications To Communications and Signal Image ProcessingDocument119 pagesHadamard Matrix Analysis and Synthesis With Applications To Communications and Signal Image ProcessingEmerson MaucaNo ratings yet
- Sample CMATDocument3 pagesSample CMATmishradiwakarNo ratings yet
- ForecastingDocument35 pagesForecastingDarwin FloresNo ratings yet
- 2600 Legarda St. Sampaloc, ManilaDocument4 pages2600 Legarda St. Sampaloc, ManilaLuz Anne de GuzmanNo ratings yet
- Mathematical Fallacy - Wikipedia The Free EncyclopediaDocument14 pagesMathematical Fallacy - Wikipedia The Free EncyclopediaMohit ChoradiaNo ratings yet
- Ps 2Document7 pagesPs 2Anonymous bOvvH4No ratings yet
- Maths Today 4 RedDocument258 pagesMaths Today 4 Redadmire matariranoNo ratings yet
- Day2 - Session - 2 - Acropolis - NPPDocument55 pagesDay2 - Session - 2 - Acropolis - NPPVDRATNAKUMARNo ratings yet
- 9X MNCERT - A - Number System (Sol)Document10 pages9X MNCERT - A - Number System (Sol)ShdriveNo ratings yet
- 04 Intro To LMIDocument38 pages04 Intro To LMImamdouhkhNo ratings yet
- CSI 3104 Introduction To Formal Languages Winter 2021 Assignment 3Document3 pagesCSI 3104 Introduction To Formal Languages Winter 2021 Assignment 3Ren3rNo ratings yet
- Integral Cos 5 (2x) : Assuming "Integral" Is An Integral Use As InsteadDocument3 pagesIntegral Cos 5 (2x) : Assuming "Integral" Is An Integral Use As InsteadFranky Gonzalez HernandezNo ratings yet
- Test I - Multiple Choice. Direction: Write The Letter of The Correct Answer On The Space Provided Before The NumberDocument2 pagesTest I - Multiple Choice. Direction: Write The Letter of The Correct Answer On The Space Provided Before The NumberLador GiovanniNo ratings yet
- Research Papers On Fibonacci SequenceDocument7 pagesResearch Papers On Fibonacci Sequencefnwsnjznd100% (1)
- Power Series Solutions of Linear Differential EquationsDocument34 pagesPower Series Solutions of Linear Differential EquationsLeidy ArenasNo ratings yet
- Detailed Lesson PlanDocument9 pagesDetailed Lesson PlanMarcella Mae IdananNo ratings yet
- Homework Helper Chapter 1Document40 pagesHomework Helper Chapter 1linuxuser userNo ratings yet
- Maths PP1Document14 pagesMaths PP1Benjamin mwanikiNo ratings yet