You might also like
- Genesys NoSkills Fillable Character Sheet PDFDocument3 pagesGenesys NoSkills Fillable Character Sheet PDFMasterWallwalkerNo ratings yet
- House Prices Prediction in King CountyDocument10 pagesHouse Prices Prediction in King CountyJun ZhangNo ratings yet
- Review QuestionsDocument9 pagesReview Questionsacr2944No ratings yet
- Project Report On e BikesDocument57 pagesProject Report On e Bikesrh21940% (5)
- Multiple Regression Analysis Using SPSS LaerdDocument14 pagesMultiple Regression Analysis Using SPSS LaerdsonuNo ratings yet
- Chapter 15 ANCOVA For Dichotomous Dependent VariablesDocument12 pagesChapter 15 ANCOVA For Dichotomous Dependent Variablesisaac_maykovichNo ratings yet
- Johnson Claims Against Eaton AsphaltDocument39 pagesJohnson Claims Against Eaton AsphaltCincinnatiEnquirerNo ratings yet
- Determination of Distribution Coefficient of Iodine Between Two Immiscible SolventsDocument6 pagesDetermination of Distribution Coefficient of Iodine Between Two Immiscible SolventsRafid Jawad100% (1)
- Block RosaryDocument9 pagesBlock RosaryRendine Rex Vizcayno100% (1)
- SPSS Binary Logistic Regression Demo 1 TerminateDocument22 pagesSPSS Binary Logistic Regression Demo 1 Terminatefahadraja78No ratings yet
- Dissertation Using Logistic RegressionDocument6 pagesDissertation Using Logistic RegressionBuyCheapPapersSingapore100% (1)
- Literature Review On Logistic RegressionDocument7 pagesLiterature Review On Logistic Regressionc5mr3mxf100% (2)
- EDA 4th ModuleDocument26 pagesEDA 4th Module205Abhishek KotagiNo ratings yet
- Thesis Multiple Linear RegressionDocument5 pagesThesis Multiple Linear Regressionlesliesanchezanchorage100% (1)
- Chapter 7Document39 pagesChapter 7Mohammed AbdurehmanNo ratings yet
- Thesis Using Linear RegressionDocument7 pagesThesis Using Linear Regressionpamelawrightvirginiabeach100% (1)
- Thesis Using Logistic RegressionDocument7 pagesThesis Using Logistic RegressionMartha Brown100% (2)
- Final Term Paper BY Muhammad Umer (18201513-043) Course Title Regression Analysis II Course Code Stat-326 Submitted To Mam Erum Shahzadi Dgree Program/Section Bs Stats - 6Th Department of StatisticsDocument11 pagesFinal Term Paper BY Muhammad Umer (18201513-043) Course Title Regression Analysis II Course Code Stat-326 Submitted To Mam Erum Shahzadi Dgree Program/Section Bs Stats - 6Th Department of StatisticsProf Bilal HassanNo ratings yet
- The Seven Classical OLS Assumptions: Ordinary Least SquaresDocument7 pagesThe Seven Classical OLS Assumptions: Ordinary Least SquaresUsama RajaNo ratings yet
- Module 4: Regression Shrinkage MethodsDocument5 pagesModule 4: Regression Shrinkage Methods205Abhishek KotagiNo ratings yet
- Dissertation Ordinal Logistic RegressionDocument5 pagesDissertation Ordinal Logistic RegressionPayToDoMyPaperCanada100% (1)
- Lesson 1: Introduction and Review of ConceptsDocument11 pagesLesson 1: Introduction and Review of ConceptsAJ AJNo ratings yet
- Linear Models BiasDocument17 pagesLinear Models BiasChathura DewenigurugeNo ratings yet
- RegressionDocument34 pagesRegressionRavi goel100% (1)
- Thesis Using Multiple Linear RegressionDocument7 pagesThesis Using Multiple Linear Regressiontmexyhikd100% (2)
- 049 Stat 326 Regression Final PaperDocument17 pages049 Stat 326 Regression Final PaperProf Bilal HassanNo ratings yet
- U.S Medical Insurance Costs: Wesley F. MaiaDocument30 pagesU.S Medical Insurance Costs: Wesley F. MaiaWesley MaiaNo ratings yet
- Bias Varience Trade OffDocument35 pagesBias Varience Trade Offmobeen100% (1)
- Statistics Interview Questions & Answers For Data ScientistsDocument43 pagesStatistics Interview Questions & Answers For Data ScientistsmlissaliNo ratings yet
- Research Paper Logistic RegressionDocument7 pagesResearch Paper Logistic Regressionfvf2ffp6100% (1)
- Linear Regression Assumptions and LimitationsDocument10 pagesLinear Regression Assumptions and Limitationsyt peekNo ratings yet
- Thesis With Multiple Regression AnalysisDocument6 pagesThesis With Multiple Regression Analysiszehlobifg100% (2)
- Logistic Regression From MalhotraDocument24 pagesLogistic Regression From MalhotraSiddharth SwainNo ratings yet
- 7-Multiple RegressionDocument17 pages7-Multiple Regressionحاتم سلطانNo ratings yet
- Regression AnalysisDocument7 pagesRegression AnalysisshoaibNo ratings yet
- Chapter Seven Multiple Regression An Introduction To Multiple Regression Performing A Multiple Regression On SpssDocument20 pagesChapter Seven Multiple Regression An Introduction To Multiple Regression Performing A Multiple Regression On SpssAkshit AroraNo ratings yet
- Literature Review On Multiple Linear RegressionDocument4 pagesLiterature Review On Multiple Linear Regressionfdnmffvkg100% (1)
- MINITAB Which Is BetterDocument6 pagesMINITAB Which Is BetterRoberto Carlos Chuquilín GoicocheaNo ratings yet
- Sample Thesis Using Regression AnalysisDocument6 pagesSample Thesis Using Regression Analysisgj4m3b5b100% (2)
- Dissertation Logistic RegressionDocument4 pagesDissertation Logistic RegressionIWillPayYouToWriteMyPaperSingapore100% (1)
- DASDocument3 pagesDASMuhammad Arif HassanNo ratings yet
- Final Paper Guide For PS, Spring : e Source File For This Document Is Not Yet Available atDocument13 pagesFinal Paper Guide For PS, Spring : e Source File For This Document Is Not Yet Available atjake bowersNo ratings yet
- Dissertation BoxplotDocument8 pagesDissertation BoxplotPaySomeoneToWriteMyPaperCanada100% (1)
- Research Paper Using Linear RegressionDocument5 pagesResearch Paper Using Linear Regressionh02rj3ek100% (1)
- Chapter4 SolutionsDocument8 pagesChapter4 SolutionsAi Lian TanNo ratings yet
- Thesis Linear RegressionDocument5 pagesThesis Linear Regressionmelissabuckleyomaha100% (2)
- REPORTING ReliabilityDocument5 pagesREPORTING ReliabilityCheasca AbellarNo ratings yet
- David A. Kenny June 5, 2020Document9 pagesDavid A. Kenny June 5, 2020Anonymous 85jwqjNo ratings yet
- Introduction To Econometrics - SummaryDocument23 pagesIntroduction To Econometrics - SummaryRajaram P RNo ratings yet
- Chapter 4Document2 pagesChapter 4Hari VenkateshNo ratings yet
- Research Paper With Regression AnalysisDocument5 pagesResearch Paper With Regression Analysisafnhbijlzdufjj100% (1)
- Lasso and Ridge RegressionDocument30 pagesLasso and Ridge RegressionAartiNo ratings yet
- DSR Notes 3 To 5Document70 pagesDSR Notes 3 To 5lila puchariNo ratings yet
- Discriminant Analysis 1 PDFDocument8 pagesDiscriminant Analysis 1 PDFLucy Copa GeronimoNo ratings yet
- Master Thesis Multiple Regression AnalysisDocument7 pagesMaster Thesis Multiple Regression Analysisqfsimwvff100% (2)
- Literature Review On Logistic Regression ModelDocument5 pagesLiterature Review On Logistic Regression Modelafmzadevfeeeat100% (1)
- Name: Adewole Oreoluwa Adesina Matric. No.: RUN/ACC/19/8261 Course Code: Eco 307Document13 pagesName: Adewole Oreoluwa Adesina Matric. No.: RUN/ACC/19/8261 Course Code: Eco 307oreoluwa adewoleNo ratings yet
- Correlation of StatisticsDocument6 pagesCorrelation of StatisticsHans Christer RiveraNo ratings yet
- Statistics Interview QuestionsDocument20 pagesStatistics Interview QuestionssairameshtNo ratings yet
- Thesis Using Multiple RegressionDocument5 pagesThesis Using Multiple Regressionrwzhdtief100% (2)
- Inferential StatisticsDocument2 pagesInferential StatisticsPROVENANCE MASUKWEDZANo ratings yet
- Termpaper EconometricsDocument21 pagesTermpaper EconometricsBasanta RaiNo ratings yet
- Econometrics 4Document37 pagesEconometrics 4Anunay ChoudharyNo ratings yet
- Oral 08 Jose StapeDocument54 pagesOral 08 Jose StapeJulie FinchNo ratings yet
- Gerunds and InfinitivesDocument1 pageGerunds and InfinitivesJulie FinchNo ratings yet
- Programming in RDocument85 pagesProgramming in RJulie FinchNo ratings yet
- Another Cautionary Note About R2Document3 pagesAnother Cautionary Note About R2Julie FinchNo ratings yet
- STELLA v9 Tutorial 1Document20 pagesSTELLA v9 Tutorial 1Julie FinchNo ratings yet
- The Ways Tree Uses WaterDocument92 pagesThe Ways Tree Uses WaterJulie Finch100% (1)
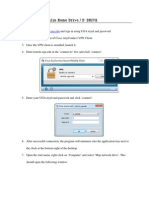
- HOW TO MAP Franklin Home Drive / S: DRIVEDocument3 pagesHOW TO MAP Franklin Home Drive / S: DRIVEJulie FinchNo ratings yet
- Gartner Magic Quadrant Report For SFA - Aug 2016Document31 pagesGartner Magic Quadrant Report For SFA - Aug 2016Francisco LSNo ratings yet
- The Doctrine of ForgivenessDocument6 pagesThe Doctrine of ForgivenessNkor IokaNo ratings yet
- Early Treatment of A Class III Malocclusion With The Myobrace SystemDocument1 pageEarly Treatment of A Class III Malocclusion With The Myobrace SystemThu Trang PhamNo ratings yet
- APPELANTDocument30 pagesAPPELANTTAS MUNNo ratings yet
- Master of Arts in Education Major in Education Management: Development Administration and Education SubjectDocument12 pagesMaster of Arts in Education Major in Education Management: Development Administration and Education SubjectJeai Rivera EvangelistaNo ratings yet
- 1 - Pre-Bid Clarifications 16dec - 2016Document13 pages1 - Pre-Bid Clarifications 16dec - 2016Anirban DubeyNo ratings yet
- Q400 PropellerDocument10 pagesQ400 PropellerMoshiurRahman100% (1)
- Pablo Gualberto Vs Gualberto VDocument2 pagesPablo Gualberto Vs Gualberto VNotaly Mae Paja BadtingNo ratings yet
- Erinnerungsmotive in Wagner's Der Ring Des NibelungenDocument14 pagesErinnerungsmotive in Wagner's Der Ring Des NibelungenLaur MatysNo ratings yet
- My Home Is My CastleDocument9 pagesMy Home Is My CastleNur ZhanNo ratings yet
- Unit - 5 - Trial BalanceDocument7 pagesUnit - 5 - Trial BalanceHANY SALEMNo ratings yet
- Impact of Government Policy and Regulations in BankingDocument65 pagesImpact of Government Policy and Regulations in BankingNiraj ThapaNo ratings yet
- Cryptocurrency: Presented By: Shashi KumarDocument15 pagesCryptocurrency: Presented By: Shashi KumaraabhasNo ratings yet
- Coronavirus Disease (COVID-19) : Situation Report - 125Document17 pagesCoronavirus Disease (COVID-19) : Situation Report - 125CityNewsTorontoNo ratings yet
- Name Caliber Base Penalties DMG Rate Clip Conceal Range CostDocument23 pagesName Caliber Base Penalties DMG Rate Clip Conceal Range CostLars Pedersen100% (1)
- CONTEXTUALIZED DLP Q1 W1 Day1Document6 pagesCONTEXTUALIZED DLP Q1 W1 Day1QUEENIE BUTALIDNo ratings yet
- Additive ManufactDocument61 pagesAdditive ManufactAnca Maria TruscaNo ratings yet
- Legal AgreementDocument2 pagesLegal AgreementMohd NadeemNo ratings yet
- Teaching The GospelDocument50 pagesTeaching The GospelgabrielpoulsonNo ratings yet
- Setting An Audit StrategyDocument14 pagesSetting An Audit Strategyyamiseto0% (1)
- Chapter 18 Metric and Imperial Measures: Scheme of WorkDocument2 pagesChapter 18 Metric and Imperial Measures: Scheme of WorkrightwayNo ratings yet
- Matisse As Printmaker: Matisse'S Printmaking ProcessesDocument2 pagesMatisse As Printmaker: Matisse'S Printmaking ProcessesWriterIncNo ratings yet
- Map of Jeju: For Muslim TouristsDocument7 pagesMap of Jeju: For Muslim TouristslukmannyeoNo ratings yet
- 01 B744 B1 ATA 23 Part2Document170 pages01 B744 B1 ATA 23 Part2NadirNo ratings yet
- IPTV-Bbc TVP What Is IptvDocument32 pagesIPTV-Bbc TVP What Is IptvSachin KumarNo ratings yet