You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Salads: 300 Salad Recipes For Rapid Weight Loss & Clean Eating (PDFDrive) PDFDocument1,092 pagesSalads: 300 Salad Recipes For Rapid Weight Loss & Clean Eating (PDFDrive) PDFDebora PanzarellaNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Manual s10 PDFDocument402 pagesManual s10 PDFLibros18No ratings yet
- Lesson 5 Designing and Developing Social AdvocacyDocument27 pagesLesson 5 Designing and Developing Social Advocacydaniel loberizNo ratings yet
- Turn Around Coordinator Job DescriptionDocument2 pagesTurn Around Coordinator Job DescriptionMikeNo ratings yet
- IEC ShipsDocument6 pagesIEC ShipsdimitaringNo ratings yet
- Kahneman & Tversky Origin of Behavioural EconomicsDocument25 pagesKahneman & Tversky Origin of Behavioural EconomicsIan Hughes100% (1)
- Log Building News - Issue No. 76Document32 pagesLog Building News - Issue No. 76ursindNo ratings yet
- Monergism Vs SynsergismDocument11 pagesMonergism Vs SynsergismPam AgtotoNo ratings yet
- Mark Garside Resume May 2014Document3 pagesMark Garside Resume May 2014api-199955558No ratings yet
- Organization and Management Module 3: Quarter 1 - Week 3Document15 pagesOrganization and Management Module 3: Quarter 1 - Week 3juvelyn luegoNo ratings yet
- Syllabusecon5072011 PDFDocument1 pageSyllabusecon5072011 PDFRoger Asencios NuñezNo ratings yet
- Lecture-1 Econometria de La PobrezaDocument11 pagesLecture-1 Econometria de La PobrezaRoger Asencios NuñezNo ratings yet
- PanelDocument29 pagesPanelRoger Asencios NuñezNo ratings yet
- Nonlinear G MMDocument19 pagesNonlinear G MMRoger Asencios NuñezNo ratings yet
- Ner LoveDocument16 pagesNer LoveRoger Asencios NuñezNo ratings yet
- Ols GeometryDocument30 pagesOls GeometryRoger Asencios NuñezNo ratings yet
- L Sample InferenceDocument27 pagesL Sample InferenceRoger Asencios NuñezNo ratings yet
- Final Lecture 507Document8 pagesFinal Lecture 507Roger Asencios NuñezNo ratings yet
- Large Sample Results For The Linear Model: Walter Sosa-EscuderoDocument32 pagesLarge Sample Results For The Linear Model: Walter Sosa-EscuderoRoger Asencios NuñezNo ratings yet
- Finite-Sample Properties of OLS in The Classical Linear ModelDocument16 pagesFinite-Sample Properties of OLS in The Classical Linear ModelRoger Asencios NuñezNo ratings yet
- EffectsofPollution PDFDocument16 pagesEffectsofPollution PDFRoger Asencios NuñezNo ratings yet
- Exact InferenceDocument18 pagesExact InferenceRoger Asencios NuñezNo ratings yet
- CX Programmer Operation ManualDocument536 pagesCX Programmer Operation ManualVefik KaraegeNo ratings yet
- Global Geo Reviewer MidtermDocument29 pagesGlobal Geo Reviewer Midtermbusinesslangto5No ratings yet
- User Manual For Speed Control of BLDC Motor Using DspicDocument12 pagesUser Manual For Speed Control of BLDC Motor Using DspicTrung TrựcNo ratings yet
- Lesson PlanDocument2 pagesLesson Plannicole rigonNo ratings yet
- V737 OverheadDocument50 pagesV737 OverheadnewahNo ratings yet
- Environmental Economics Pollution Control: Mrinal Kanti DuttaDocument253 pagesEnvironmental Economics Pollution Control: Mrinal Kanti DuttashubhamNo ratings yet
- Dynamics of Machinery PDFDocument18 pagesDynamics of Machinery PDFThomas VictorNo ratings yet
- Quantitative Methods For Economics and Business Lecture N. 5Document20 pagesQuantitative Methods For Economics and Business Lecture N. 5ghassen msakenNo ratings yet
- Monkey Says, Monkey Does Security andDocument11 pagesMonkey Says, Monkey Does Security andNudeNo ratings yet
- UTP Student Industrial ReportDocument50 pagesUTP Student Industrial ReportAnwar HalimNo ratings yet
- Opc PPT FinalDocument22 pagesOpc PPT FinalnischalaNo ratings yet
- Task 3 - LPDocument21 pagesTask 3 - LPTan S YeeNo ratings yet
- Residual Power Series Method For Obstacle Boundary Value ProblemsDocument5 pagesResidual Power Series Method For Obstacle Boundary Value ProblemsSayiqa JabeenNo ratings yet
- MASONRYDocument8 pagesMASONRYJowelyn MaderalNo ratings yet
- Activity # 1 (DRRR)Document2 pagesActivity # 1 (DRRR)Juliana Xyrelle FutalanNo ratings yet
- The Use of Air Cooled Heat Exchangers in Mechanical Seal Piping Plans - SnyderDocument7 pagesThe Use of Air Cooled Heat Exchangers in Mechanical Seal Piping Plans - SnyderJaime Ocampo SalgadoNo ratings yet
- Tplink Eap110 Qig EngDocument20 pagesTplink Eap110 Qig EngMaciejNo ratings yet
- 13 Adsorption of Congo Red A Basic Dye by ZnFe-CO3Document10 pages13 Adsorption of Congo Red A Basic Dye by ZnFe-CO3Jorellie PetalverNo ratings yet
- 74HC00D 74HC00D 74HC00D 74HC00D: CMOS Digital Integrated Circuits Silicon MonolithicDocument8 pages74HC00D 74HC00D 74HC00D 74HC00D: CMOS Digital Integrated Circuits Silicon MonolithicAssistec TecNo ratings yet
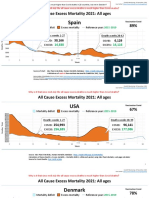
- Countries EXCESS DEATHS All Ages - 15nov2021Document21 pagesCountries EXCESS DEATHS All Ages - 15nov2021robaksNo ratings yet