You might also like
- Biostatistics and Computer-based Analysis of Health Data Using SASFrom EverandBiostatistics and Computer-based Analysis of Health Data Using SASNo ratings yet
- Stat QuizDocument79 pagesStat QuizJanice BulaoNo ratings yet
- Applied Statistics Manual: A Guide to Improving and Sustaining Quality with MinitabFrom EverandApplied Statistics Manual: A Guide to Improving and Sustaining Quality with MinitabNo ratings yet
- 6 Basic Statistical ToolsDocument30 pages6 Basic Statistical ToolsRose Ann MendigorinNo ratings yet
- HerramientasBasicas FAODocument86 pagesHerramientasBasicas FAOVíctor A. Huamaní LeónNo ratings yet
- HerramientasBasicas FAODocument86 pagesHerramientasBasicas FAODenys Rivera GuevaraNo ratings yet
- Basic Statistical Tools: There Are Lies, Damn Lies, and Statistics...... (Anonnymous)Document37 pagesBasic Statistical Tools: There Are Lies, Damn Lies, and Statistics...... (Anonnymous)Doods GaldoNo ratings yet
- Basic Statistical ToolsDocument43 pagesBasic Statistical ToolsHaytham Janoub HamoudaNo ratings yet
- 6 Basic Statistical ToolsDocument30 pages6 Basic Statistical Toolsdrs_mdu48No ratings yet
- Bchet 141 em GPDocument34 pagesBchet 141 em GPmohnish aryanNo ratings yet
- What Calculations?Document7 pagesWhat Calculations?rose_almonteNo ratings yet
- BSChem-Statistics in Chemical Analysis PDFDocument6 pagesBSChem-Statistics in Chemical Analysis PDFKENT BENEDICT PERALESNo ratings yet
- Uncertain and Sensitivity in LCADocument7 pagesUncertain and Sensitivity in LCALiming WangNo ratings yet
- Some Basic Qa QC Concepts: Quality Assurance (QA) Refers To The Overall ManagementDocument8 pagesSome Basic Qa QC Concepts: Quality Assurance (QA) Refers To The Overall ManagementUltrichNo ratings yet
- Analyze PhaseDocument33 pagesAnalyze PhasePatricia Ann FelicianoNo ratings yet
- Measurement System AnalysisDocument5 pagesMeasurement System AnalysisRahul BenkeNo ratings yet
- Chem 26.1 Formal Report Expt 1Document8 pagesChem 26.1 Formal Report Expt 1kristiaa_1No ratings yet
- Quality Engineering and Management System Accounting EssayDocument12 pagesQuality Engineering and Management System Accounting EssayvasudhaaaaaNo ratings yet
- Measurement System AnalysisDocument15 pagesMeasurement System AnalysisIndian MHNo ratings yet
- Unit-1 Statistical Quality Control: Learning ObjectivesDocument69 pagesUnit-1 Statistical Quality Control: Learning ObjectivesHarnitNo ratings yet
- 6.mass BalancingDocument36 pages6.mass BalancingRaul Dionicio100% (1)
- An Introduction To Quality Assurance in Analytical Science: DR Irene Mueller-Harvey MR Richard Baker MR Brian WoodgetDocument25 pagesAn Introduction To Quality Assurance in Analytical Science: DR Irene Mueller-Harvey MR Richard Baker MR Brian Woodgetvrcom100% (1)
- Experiment 1Document4 pagesExperiment 1Charls DeimoyNo ratings yet
- Overview Six Sigma PhasesDocument3 pagesOverview Six Sigma Phaseshans_106No ratings yet
- 52) Statistical AnalysisDocument11 pages52) Statistical Analysisbobot80No ratings yet
- Six Sigma Tools in A Excel SheetDocument19 pagesSix Sigma Tools in A Excel SheetMichelle Morgan LongstrethNo ratings yet
- Measurement System AnalysisDocument7 pagesMeasurement System AnalysisselvamNo ratings yet
- Regression ValidationDocument3 pagesRegression Validationharrison9No ratings yet
- Test PDFDocument4 pagesTest PDFferonika_cNo ratings yet
- What Is A GageDocument12 pagesWhat Is A GageMohini MaratheNo ratings yet
- Measurement System AnalysisDocument29 pagesMeasurement System AnalysissidwalNo ratings yet
- Module 1 Fundamentals of Pre Analyses UNIT 1: Theory of ErrorsDocument94 pagesModule 1 Fundamentals of Pre Analyses UNIT 1: Theory of ErrorsJessica ZafraNo ratings yet
- Statistics: Error (Chpt. 5)Document16 pagesStatistics: Error (Chpt. 5)Amit SahaNo ratings yet
- How To Prepare Data For Predictive AnalysisDocument5 pagesHow To Prepare Data For Predictive AnalysisMahak KathuriaNo ratings yet
- Statistical Quality Control Is Defined As "TheDocument17 pagesStatistical Quality Control Is Defined As "TheDeepak KumarNo ratings yet
- Six Sigma ToolsDocument24 pagesSix Sigma ToolsDave HanleyNo ratings yet
- Is Audit Report - Chapter 9Document49 pagesIs Audit Report - Chapter 9Mary Grace Caguioa AgasNo ratings yet
- Manufacturing Technology AssignmentDocument15 pagesManufacturing Technology AssignmentDan Kiama MuriithiNo ratings yet
- Qual For Researchgate StatisticsDocument22 pagesQual For Researchgate Statisticsrusudanzazadze7No ratings yet
- Quality Control 4. What Are Meant by Median and Mode? Give Examples From A Set of Data Characterize The Other Types of QC ChartsDocument2 pagesQuality Control 4. What Are Meant by Median and Mode? Give Examples From A Set of Data Characterize The Other Types of QC ChartsDennis ValdezNo ratings yet
- Pages From SPSS For BeginnersDocument58 pagesPages From SPSS For BeginnersWaqas NadeemNo ratings yet
- Summary of Coleman and Steele Uncertainty MethodsDocument6 pagesSummary of Coleman and Steele Uncertainty MethodsAli Al-hamalyNo ratings yet
- Why You Never Really Validate Your Analytical Method Unless You Use The Total Error Approach (Part I: Concept)Document10 pagesWhy You Never Really Validate Your Analytical Method Unless You Use The Total Error Approach (Part I: Concept)ConnieNo ratings yet
- Quality Management MethodologiesDocument8 pagesQuality Management Methodologiesselinasimpson3001No ratings yet
- Radiology Quality ManagementDocument7 pagesRadiology Quality Managementselinasimpson361No ratings yet
- Statistical Quality ControlDocument91 pagesStatistical Quality ControlJabir Aghadi100% (3)
- 5 - Pca & Garett RankDocument14 pages5 - Pca & Garett RankWilliam Veloz DiazNo ratings yet
- MSA Training Material - 18 - 04 - 2018Document10 pagesMSA Training Material - 18 - 04 - 2018Mark AntonyNo ratings yet
- Quality Management MethodologyDocument8 pagesQuality Management Methodologyselinasimpson2201No ratings yet
- IVT Network - Statistical Analysis in Analytical Method Validation - 2014-07-10Document11 pagesIVT Network - Statistical Analysis in Analytical Method Validation - 2014-07-10Jose Luis Huaman100% (1)
- A. Cause and Effect Diagram: Assignment-Set 1Document26 pagesA. Cause and Effect Diagram: Assignment-Set 1Hariharan RajaramanNo ratings yet
- 191 29Document10 pages191 29putcallparityNo ratings yet
- Quality Data ManagementDocument7 pagesQuality Data Managementselinasimpson0301No ratings yet
- Jsmith Microbe 09Document0 pagesJsmith Microbe 09Lionel PinuerNo ratings yet
- Quality Health ManagementDocument7 pagesQuality Health Managementselinasimpson0601No ratings yet
- Ora Laboratory Manual: Section 4 Section 4Document25 pagesOra Laboratory Manual: Section 4 Section 4Armando SaldañaNo ratings yet
- NLS Tools ForDocument21 pagesNLS Tools ForTylerNo ratings yet
- Six Sigma Reference Tool: DefinitionDocument24 pagesSix Sigma Reference Tool: DefinitionDeJuana CobbNo ratings yet
- Statistical Process Control (SPC) TutorialDocument10 pagesStatistical Process Control (SPC) TutorialRob WillestoneNo ratings yet
- Analysis of Error in Measurement SystemDocument8 pagesAnalysis of Error in Measurement SystemHimanshuKalbandheNo ratings yet
- Frequencies: Statistics Designation Department Gender Age Qualification ExperienceDocument6 pagesFrequencies: Statistics Designation Department Gender Age Qualification ExperienceBhagwati ShuklaNo ratings yet
- MRPDocument56 pagesMRPBhagwati Shukla100% (1)
- CorrelationsDocument3 pagesCorrelationsBhagwati ShuklaNo ratings yet
- New Microsoft Office Word DocumentDocument1 pageNew Microsoft Office Word DocumentBhagwati ShuklaNo ratings yet
- MRPDocument56 pagesMRPBhagwati Shukla100% (1)
- Summary of ResponsesBBBJBJS VJDocument9 pagesSummary of ResponsesBBBJBJS VJBhagwati ShuklaNo ratings yet
- Literature ReviewDocument15 pagesLiterature ReviewBhagwati ShuklaNo ratings yet
- QuestionnaireDocument4 pagesQuestionnaireBhagwati ShuklaNo ratings yet
- List of HR Topics For ProjectDocument2 pagesList of HR Topics For ProjectBhagwati ShuklaNo ratings yet
- Final Edited AnnexuresDocument26 pagesFinal Edited AnnexuresBhagwati ShuklaNo ratings yet
- Introductionjsdbkdfnlk naANDocument14 pagesIntroductionjsdbkdfnlk naANBhagwati ShuklaNo ratings yet
- Summary of ResponsesBBBJBJS VJDocument9 pagesSummary of ResponsesBBBJBJS VJBhagwati ShuklaNo ratings yet
- Scanning Business EnvironmentDocument31 pagesScanning Business EnvironmentBhagwati ShuklaNo ratings yet
- Entrepreneurs Characteristics Functions TypesDocument85 pagesEntrepreneurs Characteristics Functions TypesBhagwati ShuklaNo ratings yet
- Research Paper On Student Support ServicesDocument10 pagesResearch Paper On Student Support ServicesBhagwati Shukla0% (1)
- BRTS Indore Some DrawbacksDocument10 pagesBRTS Indore Some DrawbacksBhagwati ShuklaNo ratings yet
- Sadhak Sanjivin 1Document12 pagesSadhak Sanjivin 1sckulkarni@varshaNo ratings yet
- Summary of FindingsDocument2 pagesSummary of FindingsBhagwati ShuklaNo ratings yet
- CHAPTER - 12.6 Pilot Study QuestionnaireDocument2 pagesCHAPTER - 12.6 Pilot Study QuestionnaireBhagwati ShuklaNo ratings yet
- Spss SyllabusDocument2 pagesSpss SyllabusBhagwati ShuklaNo ratings yet
- Development of The Indore Bus Rapid Transit (BRT) System: A Learning ExperienceDocument25 pagesDevelopment of The Indore Bus Rapid Transit (BRT) System: A Learning ExperienceBhagwati ShuklaNo ratings yet
- 3GDocument124 pages3GBhagwati ShuklaNo ratings yet
- Briefing PaperDocument59 pagesBriefing PaperRaj DeshmukhNo ratings yet
- Economic CorridorDocument12 pagesEconomic CorridorMohit Sharma100% (1)
- S 01 p1 MR - Dimmts Jan10Document22 pagesS 01 p1 MR - Dimmts Jan10Bhagwati ShuklaNo ratings yet
- Synopsis Ahmedabad BRTSDocument2 pagesSynopsis Ahmedabad BRTSKeyur KhoontNo ratings yet
- Draw BacksDocument1 pageDraw BacksBhagwati ShuklaNo ratings yet
- UAE0 B 54459Document1 pageUAE0 B 54459Bhagwati ShuklaNo ratings yet
- Rewa Sidhi Gramin BankDocument11 pagesRewa Sidhi Gramin BankAjay KumarNo ratings yet
- STA215 STA220 Practice TestDocument13 pagesSTA215 STA220 Practice TestRevownSadaNo ratings yet
- NEP Syllabus 1 - 24082023Document117 pagesNEP Syllabus 1 - 24082023tejasshelke629No ratings yet
- Poisson Regression Analysis 136Document8 pagesPoisson Regression Analysis 136George AdongoNo ratings yet
- Chap 06Document66 pagesChap 06hejuradoNo ratings yet
- Documents Civtren Trip DistributionDocument34 pagesDocuments Civtren Trip DistributionJeyvie Cabrera OdiameNo ratings yet
- Test Plan and CalibrationDocument8 pagesTest Plan and CalibrationDaniel LiawNo ratings yet
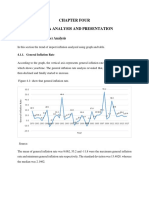
- Chapter Four 4. Data Analysis and PresentationDocument14 pagesChapter Four 4. Data Analysis and PresentationAbdurohmanNo ratings yet
- Bbs14ege ch07 Sampling DistributionsDocument47 pagesBbs14ege ch07 Sampling DistributionsMickeyNo ratings yet
- Final Paper Summer II - KeyDocument14 pagesFinal Paper Summer II - KeyMuhammad GulfamNo ratings yet
- Chemical Engineering Science Volume 27 Issue 10 1972 (Doi 10.1016/0009-2509 (72) 85046-2) Jaroslav Votruba Vladimír Hlaváček Miloš Marek - Packed Bed Axial Thermal ConductivityDocument7 pagesChemical Engineering Science Volume 27 Issue 10 1972 (Doi 10.1016/0009-2509 (72) 85046-2) Jaroslav Votruba Vladimír Hlaváček Miloš Marek - Packed Bed Axial Thermal ConductivityAdriano HenriqueNo ratings yet
- Jackson and Pollock, 1978Document9 pagesJackson and Pollock, 1978oldvan2No ratings yet
- SigmaPlot - Fitting Controlled Release and Dissolution DataDocument3 pagesSigmaPlot - Fitting Controlled Release and Dissolution DataSuraj ChoudharyNo ratings yet
- Lec2 Linear Regression With One VariableDocument48 pagesLec2 Linear Regression With One VariableZakaria AllitoNo ratings yet
- Materi Eksplorasi Pengolahan Data - KTI Banten-CompressedDocument36 pagesMateri Eksplorasi Pengolahan Data - KTI Banten-Compressedbudaya kota tangerangNo ratings yet
- MCQDocument2 pagesMCQebenesarb100% (2)
- CUHK STAT5102 Ch3Document73 pagesCUHK STAT5102 Ch3Tsoi Yun PuiNo ratings yet
- Chapter 1. Introduction To Medical ResearchDocument10 pagesChapter 1. Introduction To Medical ResearchbencleeseNo ratings yet
- Eda - Final Assessment #3 - SaludarDocument15 pagesEda - Final Assessment #3 - SaludarChristian John SaludarNo ratings yet
- Linear Regression in R - R TutorialDocument33 pagesLinear Regression in R - R TutorialSai SanthoshNo ratings yet
- Solutions Odd For CategoricalDocument28 pagesSolutions Odd For CategoricalShi LijiaNo ratings yet
- Sample Sol Mcd2080-Fat-2Document4 pagesSample Sol Mcd2080-Fat-2Dennys TNo ratings yet
- Forest Ecology and Management: A B A C A A A BDocument9 pagesForest Ecology and Management: A B A C A A A BIvankaNo ratings yet
- Impact of HR On Employees PerformanceDocument11 pagesImpact of HR On Employees PerformanceMuhammad Bilal100% (1)
- Arima Modeling With R ListendataDocument12 pagesArima Modeling With R ListendataHarshalKolhatkarNo ratings yet
- A A RegressionDocument28 pagesA A RegressionRobin GuptaNo ratings yet
- AbstractDocument24 pagesAbstractRyan Dave SuganoNo ratings yet
- Calibration of Ground-Based Lidar Instrument Wls866!26!0Document27 pagesCalibration of Ground-Based Lidar Instrument Wls866!26!0ekoNo ratings yet
- 2017 - Fault Location Method For Distribution Networks Using Smart MetersDocument8 pages2017 - Fault Location Method For Distribution Networks Using Smart Metersmcel_2aNo ratings yet
- Statistical Modeling With R - Fall 2016 Homework 3: Wells in BangladeshDocument10 pagesStatistical Modeling With R - Fall 2016 Homework 3: Wells in BangladeshSahil BhagatNo ratings yet
- Chapter 8Document7 pagesChapter 8ebustosfNo ratings yet
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryFrom EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNo ratings yet
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)From EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)No ratings yet
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathFrom EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathRating: 5 out of 5 stars5/5 (1)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsFrom EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsRating: 3.5 out of 5 stars3.5/5 (9)
- Magic Multiplication: Discover the Ultimate Formula for Fast MultiplicationFrom EverandMagic Multiplication: Discover the Ultimate Formula for Fast MultiplicationNo ratings yet
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (80)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- Who Tells the Truth?: Collection of Logical Puzzles to Make You ThinkFrom EverandWho Tells the Truth?: Collection of Logical Puzzles to Make You ThinkRating: 5 out of 5 stars5/5 (1)