You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
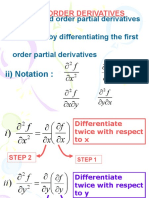
- Higher Order Derivatives Week2-DegreeDocument48 pagesHigher Order Derivatives Week2-DegreeMohamad Azizuddin100% (1)
- SPM - IntegrationDocument8 pagesSPM - IntegrationFatin NabilaNo ratings yet
- Introduction To 3+1 Numerical RelativityDocument456 pagesIntroduction To 3+1 Numerical RelativityBraw AntonioNo ratings yet
- Consciousness DK FM FinalDocument113 pagesConsciousness DK FM FinalLucas SilvaNo ratings yet
- Abellanosa-Activity2 5Document3 pagesAbellanosa-Activity2 5Venesse Aulga AbellanosaNo ratings yet
- Dips GroupTheory PrintedNotes 72pagesDocument72 pagesDips GroupTheory PrintedNotes 72pagesAnaNkineNo ratings yet
- Algebra and Number Theory Exam: Part I Multiple Choice TestDocument4 pagesAlgebra and Number Theory Exam: Part I Multiple Choice TestAnaNkineNo ratings yet
- Precis MathsDocument432 pagesPrecis MathsAnaNkineNo ratings yet
- Automorphisms of Det (X,) : The Group Scheme ApproachDocument33 pagesAutomorphisms of Det (X,) : The Group Scheme ApproachAnaNkineNo ratings yet
- Automorphisms of Det (X,) : The Group Scheme ApproachDocument33 pagesAutomorphisms of Det (X,) : The Group Scheme ApproachAnaNkineNo ratings yet
- 8.325: Relativistic Quantum Field Theory III Problem Set 2Document1 page8.325: Relativistic Quantum Field Theory III Problem Set 2belderandover09No ratings yet
- Infrared Spectroscopy RCDocument22 pagesInfrared Spectroscopy RCSricharanNo ratings yet
- 3-D Rotations: Using Euler AnglesDocument17 pages3-D Rotations: Using Euler AnglestafNo ratings yet
- Chapter 12Document6 pagesChapter 12Asad SaeedNo ratings yet
- Parametric CurvesDocument9 pagesParametric CurvesShashank PathakNo ratings yet
- Rutherford's Contribution to the Atomic ModelDocument9 pagesRutherford's Contribution to the Atomic ModelUmme farwaNo ratings yet
- Rubber Band Thermodynamics: Relating Force to Entropy and Temperature ChangeDocument7 pagesRubber Band Thermodynamics: Relating Force to Entropy and Temperature ChangeLuciano Sánchez AramburuNo ratings yet
- Decay Mechanisms and SchemeDocument14 pagesDecay Mechanisms and SchemeOscarNo ratings yet
- Worksheet 9 - Electromagnetic Radiation and The Bohr AtomDocument4 pagesWorksheet 9 - Electromagnetic Radiation and The Bohr Atomvisa1032No ratings yet
- Gauss' LawDocument37 pagesGauss' LawArsetonikaNo ratings yet
- PerspectivitiesDocument7 pagesPerspectivitiesShiva KommagoniNo ratings yet
- Schrodingers Cat ThesisDocument5 pagesSchrodingers Cat Thesisafkomeetd100% (2)
- Inverse Laplace Transform Lecture-3Document22 pagesInverse Laplace Transform Lecture-3SingappuliNo ratings yet
- HW # 9 CH - 37: RelativityDocument5 pagesHW # 9 CH - 37: RelativityPhysicist ManojNo ratings yet
- Worksheet Matrices 2022 2023Document8 pagesWorksheet Matrices 2022 2023SmitNo ratings yet
- Modern Atomic TheoryDocument2 pagesModern Atomic TheorySamantha Chim ParkNo ratings yet
- Mathematical Methods II Homework Sheet 5 Orthogonality and Least-Squares ProblemDocument7 pagesMathematical Methods II Homework Sheet 5 Orthogonality and Least-Squares ProblemBeatriz IzquierdoNo ratings yet
- Quantum Computing With Neutral AtomsDocument41 pagesQuantum Computing With Neutral AtomsVictor FestNo ratings yet
- Math1600 A3 21Document3 pagesMath1600 A3 21ANo ratings yet
- Hückel's MO Treatment of BenzeneDocument12 pagesHückel's MO Treatment of BenzeneRichard Allen0% (1)
- Classical Mechanics R Douglas PDFDocument12 pagesClassical Mechanics R Douglas PDFMOFEEZUR RAHMAN100% (1)
- Entangling Quantum Generative Adversarial NetworksDocument10 pagesEntangling Quantum Generative Adversarial Networksamir-alNo ratings yet
- Imperial College London Bsci/Msci Examination May 2016 Mph2 Mathematical MethodsDocument6 pagesImperial College London Bsci/Msci Examination May 2016 Mph2 Mathematical MethodsRoy VeseyNo ratings yet
- OrganizationDocument2 pagesOrganizationhulusi CengizNo ratings yet
- Fokker Plank EquationDocument7 pagesFokker Plank EquationSami UllahNo ratings yet