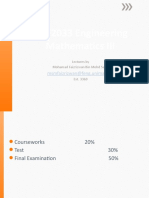
You might also like
- Matrix Theory and Applications for Scientists and EngineersFrom EverandMatrix Theory and Applications for Scientists and EngineersNo ratings yet
- Quantitative MethodsDocument42 pagesQuantitative Methodsravich9No ratings yet
- Matrices 1Document29 pagesMatrices 1Alexander CorvinusNo ratings yet
- 1.4 Matrices and Matrix Operations: Definition: A Matrix Is A Rectangular Array of Numbers. The Numbers in The ArrayDocument6 pages1.4 Matrices and Matrix Operations: Definition: A Matrix Is A Rectangular Array of Numbers. The Numbers in The ArrayAMIR ALINo ratings yet
- Excel DemasDocument16 pagesExcel DemasDavidAlejoNo ratings yet
- Chapter TwoDocument176 pagesChapter TwoHailemariamNo ratings yet
- Math-149 MatricesDocument26 pagesMath-149 MatricesKurl Vincent GamboaNo ratings yet
- Linear Algebra - Module 1Document52 pagesLinear Algebra - Module 1TestNo ratings yet
- All About MatricesDocument14 pagesAll About MatricesMyla MuddiNo ratings yet
- Chapter 1 Matrix Theory and Its ApplicationDocument18 pagesChapter 1 Matrix Theory and Its Applicationyonas100% (1)
- Chapter Two: Matrix Algebra and Its ApplicationsDocument14 pagesChapter Two: Matrix Algebra and Its ApplicationsAbrha636No ratings yet
- MGMT 221, Ch. IIDocument33 pagesMGMT 221, Ch. IIMulugeta Girma67% (6)
- Matrix ManipulateDocument59 pagesMatrix ManipulatesudhirNo ratings yet
- CH 2 MatrixDocument11 pagesCH 2 Matrixsamita2721No ratings yet
- Matrices, Determinant and InverseDocument12 pagesMatrices, Determinant and InverseRIZKIKI100% (1)
- Module 1 Determinants:: F (A) K, Where ADocument0 pagesModule 1 Determinants:: F (A) K, Where AManish MishraNo ratings yet
- Introduction To Matrix AlgebraDocument14 pagesIntroduction To Matrix Algebrabd87glNo ratings yet
- Basic Matrix AlgebraDocument11 pagesBasic Matrix Algebrawgy9xkkbgqNo ratings yet
- Summary QM2 Math IBDocument50 pagesSummary QM2 Math IBIvetteNo ratings yet
- Algebra MatricialDocument17 pagesAlgebra MatricialjoelmulatosanchezNo ratings yet
- Determinants and MatricesDocument13 pagesDeterminants and MatricesIsha MancenidoNo ratings yet
- Course: Calculus Ii CODE: Z0190 YEAR: 2014Document47 pagesCourse: Calculus Ii CODE: Z0190 YEAR: 2014Tasy WijayaNo ratings yet
- Chapter 3Document13 pagesChapter 3kawibep229No ratings yet
- Business Maths - BBA - 1yr - Unit 3Document141 pagesBusiness Maths - BBA - 1yr - Unit 3ADISH JAINNo ratings yet
- Math Majorship LinearDocument12 pagesMath Majorship LinearMaybelene NavaresNo ratings yet
- Lecture 1 - Special Matrix OperationDocument20 pagesLecture 1 - Special Matrix OperationJordan Empensando OliverosNo ratings yet
- Engineering Mathematics Iii: KNF 2033 Semester 1 2011/2012Document30 pagesEngineering Mathematics Iii: KNF 2033 Semester 1 2011/2012tulis88No ratings yet
- Linear Algebra Chapter 1 MatricesDocument13 pagesLinear Algebra Chapter 1 MatricesEugemy GrulloNo ratings yet
- AI in MathDocument32 pagesAI in MathSruthi Sundar100% (1)
- 2matrices Its OperationsDocument27 pages2matrices Its OperationsJoelar OndaNo ratings yet
- Quantitative Methods (10 Chapters)Document54 pagesQuantitative Methods (10 Chapters)Ravish Chandra67% (3)
- Matrices and Determinants: Ij Ij Ij Ij IjDocument23 pagesMatrices and Determinants: Ij Ij Ij Ij Ijumeshmalla2006No ratings yet
- MatricesDocument76 pagesMatricesNaveenNo ratings yet
- Theory of Errors and AdjustmentDocument80 pagesTheory of Errors and AdjustmentGabriela CanareNo ratings yet
- محاظره 10و11و12Document8 pagesمحاظره 10و11و12zpdcvinNo ratings yet
- Linear Algebra IDocument43 pagesLinear Algebra IDaniel GreenNo ratings yet
- "Just The Maths" Unit Number 9.1 Matrices 1 (Definitions & Elementary Matrix Algebra) by A.J.HobsonDocument9 pages"Just The Maths" Unit Number 9.1 Matrices 1 (Definitions & Elementary Matrix Algebra) by A.J.HobsonMayank SanNo ratings yet
- Matrix PrimerDocument12 pagesMatrix Primermir emmettNo ratings yet
- Notes On Matric AlgebraDocument11 pagesNotes On Matric AlgebraMaesha ArmeenNo ratings yet
- Maths For Finance CHAPTER 2 PDFDocument31 pagesMaths For Finance CHAPTER 2 PDFWonde Biru100% (1)
- Introduction To Matrix AlgebraDocument100 pagesIntroduction To Matrix AlgebraDèřæ Ô MáNo ratings yet
- Unit3 NotesDocument34 pagesUnit3 NotesSruthi SundarNo ratings yet
- Chapter 15 Linear AlgebraDocument59 pagesChapter 15 Linear AlgebraAk ChintuNo ratings yet
- KNF2033 Engineering Mathematics III: Msmfaizrizwan@feng - Unimas.myDocument26 pagesKNF2033 Engineering Mathematics III: Msmfaizrizwan@feng - Unimas.myChing On HuaNo ratings yet
- Matrices: Joseph Sylvester. Now, Matrices Have Become A Useful Tool in Solving BusinessDocument13 pagesMatrices: Joseph Sylvester. Now, Matrices Have Become A Useful Tool in Solving BusinessSubhamNo ratings yet
- Maths Chapter TwoDocument25 pagesMaths Chapter TwoAsanti AhmedNo ratings yet
- 2-Matrices and DeterminantsDocument42 pages2-Matrices and DeterminantsslowjamsNo ratings yet
- Matrix Algebra ReviewDocument16 pagesMatrix Algebra ReviewGourav GuptaNo ratings yet
- Matlab 2Document40 pagesMatlab 2Husam AL-QadasiNo ratings yet
- Usme, Dtu Project On Matrices and Determinants Analysis BY Bharat Saini Tanmay ChhikaraDocument17 pagesUsme, Dtu Project On Matrices and Determinants Analysis BY Bharat Saini Tanmay ChhikaraTanmay ChhikaraNo ratings yet
- Matrix Multiplication: Hyun Lee, Eun Kim, Jedd HakimiDocument47 pagesMatrix Multiplication: Hyun Lee, Eun Kim, Jedd HakimiMike KuNo ratings yet
- Matrix and Matrices OperationsDocument6 pagesMatrix and Matrices OperationsZoldi3rNo ratings yet
- Basic Simulation Lab FileDocument53 pagesBasic Simulation Lab FileBharat67% (3)
- This Section Describe The Matrix Algebra, Especially MultiplicationDocument23 pagesThis Section Describe The Matrix Algebra, Especially MultiplicationkarimtejaniNo ratings yet
- Chapter OneDocument14 pagesChapter OneBiruk YidnekachewNo ratings yet
- Module 1 Determinants:: F (A) K, Where ADocument10 pagesModule 1 Determinants:: F (A) K, Where ARupa PaulNo ratings yet
- Matrices: Definition and ClassificationDocument4 pagesMatrices: Definition and ClassificationGyanendra VermaNo ratings yet
- Ch-2 Lecture NoteDocument55 pagesCh-2 Lecture Notedtesfaye6395No ratings yet
- Term 1 Chapter 3 - Matrices - New - 2013Document4 pagesTerm 1 Chapter 3 - Matrices - New - 2013sound05No ratings yet
- Tensors (Especially 2nd Order Ones) : Stress Tensor.Document5 pagesTensors (Especially 2nd Order Ones) : Stress Tensor.sayhigaurav07No ratings yet
- Tensors in MathematicaDocument6 pagesTensors in MathematicaDennis La Cotera0% (1)
- Math 250Document216 pagesMath 250omisheikhNo ratings yet
- Zwiebach Notes PDFDocument68 pagesZwiebach Notes PDFAram ShojaeiNo ratings yet
- Tensor NotationDocument26 pagesTensor NotationVictor Worch ArriagaNo ratings yet
- Tensor ProductDocument9 pagesTensor Productjj3problembearNo ratings yet
- AppliedOne PDFDocument266 pagesAppliedOne PDFnehabehlNo ratings yet
- A Brief Introduction To TensorsDocument12 pagesA Brief Introduction To TensorsJude JudeNo ratings yet
- Ejercicios de Tensores y Producto TensorialDocument3 pagesEjercicios de Tensores y Producto TensorialDiego Andres Gomez PoloNo ratings yet
- Scalar DefinitionDocument4 pagesScalar Definitioncircleteam123No ratings yet
- A Brief Introduction To Tensors and Their PropertiesDocument26 pagesA Brief Introduction To Tensors and Their Propertiesfazli80No ratings yet
- Matrix Multiplication: Non-Technical DetailsDocument10 pagesMatrix Multiplication: Non-Technical DetailsToprak AlemNo ratings yet
- Dot Product PDFDocument9 pagesDot Product PDFShahnaj ParvinNo ratings yet
- Part 03 Continuum MechanicsDocument75 pagesPart 03 Continuum Mechanicszakariyae el mourabitNo ratings yet
- Norm and Inner Products in C, and Abstract Inner Product Spaces Math 130 Linear AlgebraDocument2 pagesNorm and Inner Products in C, and Abstract Inner Product Spaces Math 130 Linear AlgebraEdwin LeónNo ratings yet
- Tensor Product - Wikipedia, The Free EncyclopediaDocument6 pagesTensor Product - Wikipedia, The Free EncyclopediaSuncreationsKkdiNo ratings yet
- IIT JEE Physics Free Notes: Mechanics - Vectors and ScalarsDocument4 pagesIIT JEE Physics Free Notes: Mechanics - Vectors and ScalarsDr.Balakrishnan Kishore67% (3)
- Chapter 1Document13 pagesChapter 1Daniel ParkerNo ratings yet
- Unit3 NotesDocument34 pagesUnit3 NotesSruthi SundarNo ratings yet
- Linear Algebra: Vectors and Vector SpacesDocument4 pagesLinear Algebra: Vectors and Vector SpacesRohit SahuNo ratings yet
- Unit 3Document21 pagesUnit 3Akash Varma JampanaNo ratings yet
- Chapter 2 For Book On Stress AnalysisDocument40 pagesChapter 2 For Book On Stress Analysisvishwajeet patilNo ratings yet
- Vector and Matrices - Some ArticlesDocument239 pagesVector and Matrices - Some ArticlesambergetNo ratings yet
- Khana KabaDocument25 pagesKhana KabaIMRAN SARWARNo ratings yet
- Python Notes by Jobhunter TeamDocument255 pagesPython Notes by Jobhunter TeamChinamayi ChinmayiNo ratings yet
- Linear Algebra - WikipediaDocument15 pagesLinear Algebra - Wikipediatsvmpm1765No ratings yet