
You might also like
- 100 Excel Simulations: Using Excel to Model Risk, Investments, Genetics, Growth, Gambling and Monte Carlo AnalysisFrom Everand100 Excel Simulations: Using Excel to Model Risk, Investments, Genetics, Growth, Gambling and Monte Carlo AnalysisRating: 4.5 out of 5 stars4.5/5 (5)
- Practice Problems AnsDocument16 pagesPractice Problems AnsSanskar SinghalNo ratings yet
- Data Structures: Will It Work?Document9 pagesData Structures: Will It Work?Hamed NilforoshanNo ratings yet
- Binary Tree Research PaperDocument7 pagesBinary Tree Research Paperlbiscyrif100% (1)
- DSAL_Ass5_writeupDocument10 pagesDSAL_Ass5_writeupGaurav ShindeNo ratings yet
- Heaps, Heapsort and Priority Queues: No Gaps in It. The Last Two Conditions Give A Heap A Weak Amount of OrderDocument24 pagesHeaps, Heapsort and Priority Queues: No Gaps in It. The Last Two Conditions Give A Heap A Weak Amount of Orderawadhesh.kumarNo ratings yet
- Binary Search TreesDocument39 pagesBinary Search Treesআরব বেদুঈনNo ratings yet
- 1 Preliminaries: Data Structures and AlgorithmsDocument21 pages1 Preliminaries: Data Structures and AlgorithmsPavan RsNo ratings yet
- Assignment Set - 2: Data Structures Including Queues, Binary Trees, Searching and HashingDocument7 pagesAssignment Set - 2: Data Structures Including Queues, Binary Trees, Searching and HashingSumitavo NagNo ratings yet
- Segment Tree PDFDocument5 pagesSegment Tree PDFNeeraj SharmaNo ratings yet
- Unit 11 Dynamic Programming - 2: StructureDocument25 pagesUnit 11 Dynamic Programming - 2: StructureRaj SinghNo ratings yet
- DataStructures NotesDocument43 pagesDataStructures NotesfcmitcNo ratings yet
- TCS and InfosysDocument5 pagesTCS and InfosysAmanpreet 2003052No ratings yet
- Data Structure MaterialDocument22 pagesData Structure Materialgani525No ratings yet
- 01Document12 pages01Shubham KumarNo ratings yet
- DSA & DAA Fast StudyDocument6 pagesDSA & DAA Fast StudyrkpythonNo ratings yet
- mcs-021 3 SemDocument19 pagesmcs-021 3 Semhimanshu yadavNo ratings yet
- Swapping Variables Without Additional Space: Previous EntriesDocument13 pagesSwapping Variables Without Additional Space: Previous EntriesUtkarsh BhardwajNo ratings yet
- DS ImportentDocument17 pagesDS Importentgoswamiakshay777No ratings yet
- Fast Algorithms For Mining Association RulesDocument2 pagesFast Algorithms For Mining Association Rulesगोपाल शर्माNo ratings yet
- Online Mining of Data To Generate Association Rule Mining in Large DatabasesDocument6 pagesOnline Mining of Data To Generate Association Rule Mining in Large Databasessravya_373771414No ratings yet
- 1.when A Sparse Matrix Is Represented With A 2-Dimensional Array, WeDocument6 pages1.when A Sparse Matrix Is Represented With A 2-Dimensional Array, Wekhushinagar9009No ratings yet
- BINARY Search TreeDocument22 pagesBINARY Search TreeMallinath KhondeNo ratings yet
- DS Class Notes PDFDocument17 pagesDS Class Notes PDFpardeshisankalp1804No ratings yet
- DS - Unit 3 - NotesDocument13 pagesDS - Unit 3 - NotesManikyarajuNo ratings yet
- Ex. No. 6 Implementation of Binary Search TreeDocument8 pagesEx. No. 6 Implementation of Binary Search TreeaddssdfaNo ratings yet
- Assignment 03Document9 pagesAssignment 03dilhaniNo ratings yet
- Comp 258: Assignment 2Document9 pagesComp 258: Assignment 2Hamza SheikhNo ratings yet
- Mcoo68 Smu Mca Sem2 2011Document23 pagesMcoo68 Smu Mca Sem2 2011Nitin SivachNo ratings yet
- Dsmaterials VasuDocument49 pagesDsmaterials VasuKiran All Iz Well100% (1)
- DsMahiwaya PDFDocument21 pagesDsMahiwaya PDFMahiwaymaNo ratings yet
- Abstract Data StructureDocument18 pagesAbstract Data StructureVedant PatilNo ratings yet
- Analyzing Housing Data and Building an RNN Model to Predict Stock PricesDocument6 pagesAnalyzing Housing Data and Building an RNN Model to Predict Stock PricesRishikesh ThakurNo ratings yet
- CS301FinaltermMCQsbyDr TariqHanifDocument15 pagesCS301FinaltermMCQsbyDr TariqHanifRizwanIlyasNo ratings yet
- Adsa-2unit Heap ContinueDocument20 pagesAdsa-2unit Heap Continuesharmilahema33No ratings yet
- Binary Search TreesDocument19 pagesBinary Search Treessmitrajsinh1873No ratings yet
- Data Structures - CS301 Power Point Slides Lecture 01Document48 pagesData Structures - CS301 Power Point Slides Lecture 01anumNo ratings yet
- Advanced PascalDocument38 pagesAdvanced PascalMichalis IrakleousNo ratings yet
- Python For Data Science Nympy and PandasDocument4 pagesPython For Data Science Nympy and PandasStocknEarnNo ratings yet
- CS301 Lec01Document48 pagesCS301 Lec01vp97btsm9jNo ratings yet
- Machine Learning and Pattern Recognition week 8 Neural Net IntroDocument3 pagesMachine Learning and Pattern Recognition week 8 Neural Net IntrozeliawillscumbergNo ratings yet
- Hashing Refers To The Process of Generating A Fixed-Size Output From An Input of Variable SizeDocument10 pagesHashing Refers To The Process of Generating A Fixed-Size Output From An Input of Variable SizeManthena Narasimha RajuNo ratings yet
- Implementing Machine Learning AlgorithmsDocument43 pagesImplementing Machine Learning AlgorithmsPankaj Singh100% (1)
- About TreesDocument19 pagesAbout TreesAkhilesh ChittoraNo ratings yet
- Worksheet On Data StructureDocument8 pagesWorksheet On Data StructureWiki EthiopiaNo ratings yet
- AbInitio FAQsDocument14 pagesAbInitio FAQssarvesh_mishraNo ratings yet
- Trees: Binary Search (BST), Insertion and Deletion in BST: Unit VDocument26 pagesTrees: Binary Search (BST), Insertion and Deletion in BST: Unit VDheresh SoniNo ratings yet
- JNTUA Advanced Data Structures and Algorithms Lab Manual R20Document71 pagesJNTUA Advanced Data Structures and Algorithms Lab Manual R20sandeepabi25No ratings yet
- Research Paper On Binary Search TreeDocument4 pagesResearch Paper On Binary Search Treec9qw1cjs100% (1)
- Topic 5 - Abstract Data Structures HLDocument10 pagesTopic 5 - Abstract Data Structures HL6137 DenizeNo ratings yet
- Advance Data Structure ASSIGNMENTDocument13 pagesAdvance Data Structure ASSIGNMENTMudasir KhanNo ratings yet
- 21 Collections of Data: Standard "Collection Classes"Document66 pages21 Collections of Data: Standard "Collection Classes"api-3745065No ratings yet
- Data Structure1Document8 pagesData Structure1SelvaKrishnanNo ratings yet
- Program 3Document5 pagesProgram 3api-515961562No ratings yet
- Labsheet 9Document16 pagesLabsheet 9SANJANA SANJANANo ratings yet
- Design Analysis AlgorithmDocument8 pagesDesign Analysis Algorithmshruti5488No ratings yet
- 06linked ListDocument47 pages06linked ListAmrendra SinghNo ratings yet
- Viva 1Document21 pagesViva 1arefkNo ratings yet
- CC204Document8 pagesCC204Shen VillNo ratings yet
- Case Interview Sample QuestionsDocument2 pagesCase Interview Sample Questionssnaren77767% (3)
- Capital One PDFDocument32 pagesCapital One PDFPallav AnandNo ratings yet
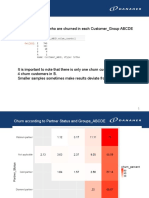
- No of Customers Who Are Churned in Each Customer - Group ABCDEDocument27 pagesNo of Customers Who Are Churned in Each Customer - Group ABCDEPallav AnandNo ratings yet
- TX DL 2016Document96 pagesTX DL 2016vreddy123No ratings yet
- Churned A Matrix V 3Document29 pagesChurned A Matrix V 3Pallav AnandNo ratings yet
- Data Processing With Dplyr TidyrDocument25 pagesData Processing With Dplyr TidyrPallav AnandNo ratings yet
- Churned A Matrix V 3Document29 pagesChurned A Matrix V 3Pallav AnandNo ratings yet
- Interview Questions ExperiencesDocument9 pagesInterview Questions ExperiencesPallav AnandNo ratings yet
- Churned A Matrix V 5Document30 pagesChurned A Matrix V 5Pallav AnandNo ratings yet
- Churned A Matrix V 3Document29 pagesChurned A Matrix V 3Pallav AnandNo ratings yet
- Artofdatascience PDFDocument162 pagesArtofdatascience PDForchid21No ratings yet
- Dates TimesDocument12 pagesDates TimesPallav AnandNo ratings yet
- Resume Ahmed ZaidiDocument2 pagesResume Ahmed ZaidiPallav AnandNo ratings yet
- 40 Interview Questions Asked at Startups in Machine Learning - Data ScienceDocument33 pages40 Interview Questions Asked at Startups in Machine Learning - Data SciencePallav Anand100% (3)
- Biological NewDocument5 pagesBiological NewPallav AnandNo ratings yet
- Machinelearningsalon Kit 28-12-2014Document155 pagesMachinelearningsalon Kit 28-12-2014Vladimir PodshivalovNo ratings yet
- Sanjay Natraj: Data Scientist/hadoop EngineerDocument2 pagesSanjay Natraj: Data Scientist/hadoop EngineerPallav AnandNo ratings yet
- Caltrain Fares Effective 2-28-16113161316Document1 pageCaltrain Fares Effective 2-28-16113161316Pallav AnandNo ratings yet
- IsenDocument4 pagesIsenPallav AnandNo ratings yet
- Machine Learning and Data Mining: Prof. Alexander Ihler Fall 2012Document36 pagesMachine Learning and Data Mining: Prof. Alexander Ihler Fall 2012Pallav AnandNo ratings yet
- 6 Chi SquareDocument3 pages6 Chi SquarePallav AnandNo ratings yet
- Lab 07Document15 pagesLab 07Pallav AnandNo ratings yet
- Pallav ReportDocument5 pagesPallav ReportPallav AnandNo ratings yet
- 2 Hypo TestingDocument4 pages2 Hypo TestingPallav AnandNo ratings yet
- Students As FormDocument2 pagesStudents As FormPallav AnandNo ratings yet
- 3 2 Review Sampling, CIDocument24 pages3 2 Review Sampling, CIPallav AnandNo ratings yet
- 4 HypoDocument4 pages4 HypoPallav AnandNo ratings yet
- 3.1 Hypothesis Testing (Critical Value Approach) : StatisticsDocument3 pages3.1 Hypothesis Testing (Critical Value Approach) : StatisticsPallav AnandNo ratings yet
- Chapter Parallel Prefix SumDocument21 pagesChapter Parallel Prefix SumAimee ReynoldsNo ratings yet
- The Tiled Quad Tree: A New Method For The Compression of Large Scale Terrain Data For Real Time Visualisation.Document77 pagesThe Tiled Quad Tree: A New Method For The Compression of Large Scale Terrain Data For Real Time Visualisation.Michael Platings100% (1)
- Segment Tree PDFDocument5 pagesSegment Tree PDFNeeraj SharmaNo ratings yet
- Programming Assignment #2: Decision Trees and Bagging for Data ClassificationDocument2 pagesProgramming Assignment #2: Decision Trees and Bagging for Data ClassificationY SAHITHNo ratings yet
- Threat Modeling in Web ApplicationDocument55 pagesThreat Modeling in Web ApplicationSoumya Ranjan Satapathy100% (1)
- KCS301 (DST) Blow UpDocument12 pagesKCS301 (DST) Blow UpShikha AryaNo ratings yet
- PAM - CompleteDocument322 pagesPAM - CompleteDaksh RawalNo ratings yet
- Classification: Decision Trees: Business Analytics Lecture 7/8Document35 pagesClassification: Decision Trees: Business Analytics Lecture 7/8Mecheal ThomasNo ratings yet
- Compilers and RTEDocument20 pagesCompilers and RTEwooDefyNo ratings yet
- C++ Lab MaualDocument89 pagesC++ Lab MaualRajat KumarNo ratings yet
- Buet Admission About TreeDocument26 pagesBuet Admission About TreeOporajitaNo ratings yet
- Advanced Form Sap AbapDocument25 pagesAdvanced Form Sap AbapJulio RafaelNo ratings yet
- Data Structure SyllabusDocument2 pagesData Structure Syllabussachin81185100% (1)
- DSA Lab ManualDocument41 pagesDSA Lab ManualVazeema SNo ratings yet
- Assignment 4Document5 pagesAssignment 4tremendoustushar_10No ratings yet
- The General Theory of General Intelligence: A Pragmatic Patternist PerspectiveDocument73 pagesThe General Theory of General Intelligence: A Pragmatic Patternist PerspectivedigmesNo ratings yet
- cs2110 15 TreesDocument42 pagescs2110 15 TreesSteve McCnamyNo ratings yet
- Expected ValueDocument41 pagesExpected ValueNikhil Kaushik100% (1)
- Merge Sort SeminarDocument22 pagesMerge Sort SeminarChaitanya BharadwajNo ratings yet
- Data Structure Question Bank and JNTU WorldDocument9 pagesData Structure Question Bank and JNTU WorldBabu GiriNo ratings yet
- Unit 3Document106 pagesUnit 3A Good YoutuberNo ratings yet
- Ec6301 - Object Oriented Programming and Data StructureDocument22 pagesEc6301 - Object Oriented Programming and Data Structurevivekpandian01No ratings yet
- CS (ECE) 301 2017 Model QuestionDocument3 pagesCS (ECE) 301 2017 Model QuestionSayani ChandraNo ratings yet
- Final Exam-InstructionsDocument3 pagesFinal Exam-Instructionsapi-335343479No ratings yet
- Programming Assignment 4Document16 pagesProgramming Assignment 4girishlalwani2010No ratings yet
- Treeview TutorialDocument37 pagesTreeview TutorialAxelFoolyNo ratings yet
- Solutions To ExercisesDocument34 pagesSolutions To ExercisesPramod PujariNo ratings yet
- Data Structure and Algorithms Syllabus DrafDocument17 pagesData Structure and Algorithms Syllabus DrafBrittaney BatoNo ratings yet
- Neto 2002Document11 pagesNeto 2002overloadNo ratings yet
- Calcutta University MBM SyllabusDocument52 pagesCalcutta University MBM SyllabusdeysayandipNo ratings yet
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- ITIL 4: Digital and IT strategy: Reference and study guideFrom EverandITIL 4: Digital and IT strategy: Reference and study guideRating: 5 out of 5 stars5/5 (1)
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveFrom EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveRating: 5 out of 5 stars5/5 (5)
- Agile Metrics in Action: How to measure and improve team performanceFrom EverandAgile Metrics in Action: How to measure and improve team performanceNo ratings yet
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Monitored: Business and Surveillance in a Time of Big DataFrom EverandMonitored: Business and Surveillance in a Time of Big DataRating: 4 out of 5 stars4/5 (1)
- Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]From EverandMicrosoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]Rating: 5 out of 5 stars5/5 (8)
- COBOL Basic Training Using VSAM, IMS and DB2From EverandCOBOL Basic Training Using VSAM, IMS and DB2Rating: 5 out of 5 stars5/5 (2)
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLFrom EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLRating: 4.5 out of 5 stars4.5/5 (46)
- DB2 11 for z/OS: SQL Basic Training for Application DevelopersFrom EverandDB2 11 for z/OS: SQL Basic Training for Application DevelopersRating: 4 out of 5 stars4/5 (1)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- Pragmatic Enterprise Architecture: Strategies to Transform Information Systems in the Era of Big DataFrom EverandPragmatic Enterprise Architecture: Strategies to Transform Information Systems in the Era of Big DataNo ratings yet
- Joe Celko's SQL for Smarties: Advanced SQL ProgrammingFrom EverandJoe Celko's SQL for Smarties: Advanced SQL ProgrammingRating: 3 out of 5 stars3/5 (1)
- Oracle Database 12c Install, Configure & Maintain Like a Professional: Install, Configure & Maintain Like a ProfessionalFrom EverandOracle Database 12c Install, Configure & Maintain Like a Professional: Install, Configure & Maintain Like a ProfessionalNo ratings yet

























































































































![Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]](https://imgv2-1-f.scribdassets.com/img/word_document/610686937/149x198/9ccfa6158e/1713743787?v=1)



















