You might also like
- 1-s2.0-S0022346814001894-m AinDocument7 pages1-s2.0-S0022346814001894-m AinleahbayNo ratings yet
- m0B6nSm 5GWsP0ektHN1hERm1veG8Document5 pagesm0B6nSm 5GWsP0ektHN1hERm1veG8leahbayNo ratings yet
- 1 - Marston ICVO JVS Paper FinadlDocument6 pages1 - Marston ICVO JVS Paper FinadlleahbayNo ratings yet
- Lateral Stress Dorsiflexion Viewb in PRESSDocument8 pagesLateral Stress Dorsiflexion Viewb in PRESSleahbayNo ratings yet
- Rotational Flap Closure of 1st and 5nth Met HeadDocument8 pagesRotational Flap Closure of 1st and 5nth Met HeadleahbayNo ratings yet
- Surgical Technique For Combined D Wyer Calcaneal Osteotomy and PeronealDocument6 pagesSurgical Technique For Combined D Wyer Calcaneal Osteotomy and PeronealleahbayNo ratings yet
- Flaps BoardsDocument56 pagesFlaps BoardsleahbayNo ratings yet
- Neuro 9 Clinical Correlates Headaches 2013Document37 pagesNeuro 9 Clinical Correlates Headaches 2013leahbayNo ratings yet
- Double Calcaneal Osteotomy Using Steimann Pin Fixation For FlatfootDocument5 pagesDouble Calcaneal Osteotomy Using Steimann Pin Fixation For FlatfootleahbayNo ratings yet
- PBBS502 Lecture7 Collagens and Fibrillar ProteinsDocument12 pagesPBBS502 Lecture7 Collagens and Fibrillar ProteinsleahbayNo ratings yet
- Neuro 5 Gross Structure of The Brain IV 2013Document13 pagesNeuro 5 Gross Structure of The Brain IV 2013leahbayNo ratings yet
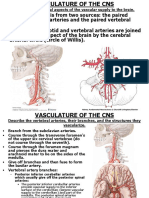
- Neuro 7 Vasculature of The CNS 2013Document17 pagesNeuro 7 Vasculature of The CNS 2013leahbayNo ratings yet
- PBBS502 Lecture3 Blood ProteinsDocument10 pagesPBBS502 Lecture3 Blood ProteinsleahbayNo ratings yet
- Guidelines For Evaluation of 5 Common Peds ProblemsDocument17 pagesGuidelines For Evaluation of 5 Common Peds ProblemsleahbayNo ratings yet
- PBBS502 Lecture6 ImmunoglobulinsDocument8 pagesPBBS502 Lecture6 ImmunoglobulinsleahbayNo ratings yet
- Review For Test 1 ProteinsDocument15 pagesReview For Test 1 ProteinsleahbayNo ratings yet
- HBDocument1 pageHBleahbayNo ratings yet
- Intro To Anatomy and Physiology VocabularyDocument13 pagesIntro To Anatomy and Physiology Vocabularywiredpsyche100% (1)
- Select The Single Best Answer: A. BioavailabilityDocument14 pagesSelect The Single Best Answer: A. BioavailabilityleahbayNo ratings yet
- Arterial Supply - CharlesPDF VersionDocument2 pagesArterial Supply - CharlesPDF VersionleahbayNo ratings yet
- Is (In My Opinion) More ComprehensiveDocument1 pageIs (In My Opinion) More ComprehensiveleahbayNo ratings yet
- How To Write A C.VDocument20 pagesHow To Write A C.VleahbayNo ratings yet
- DisorganizeDocument180 pagesDisorganizeleahbayNo ratings yet
- Ex BMT (Stem Cell Transplant)Document1 pageEx BMT (Stem Cell Transplant)leahbayNo ratings yet
- Adaptive vs. Innate ImmunityDocument1 pageAdaptive vs. Innate ImmunityleahbayNo ratings yet
- Exam 2 Sample QuestionsDocument2 pagesExam 2 Sample QuestionsleahbayNo ratings yet
- NDocument1 pageNleahbayNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- 6 - Polymer ChemistryDocument34 pages6 - Polymer ChemistryClarkNo ratings yet
- Protein Structure PredictionDocument52 pagesProtein Structure PredictionMudit MisraNo ratings yet
- Q1. The Diagrams Show Four Types of Linkage, A To D, Which Occur in Biological MoleculesDocument19 pagesQ1. The Diagrams Show Four Types of Linkage, A To D, Which Occur in Biological MoleculesiNo ratings yet
- Investigation of Plasma Protein DisordersDocument10 pagesInvestigation of Plasma Protein DisordersJosiah BimabamNo ratings yet
- BIO213-Introduction To Quantitative BiologyDocument14 pagesBIO213-Introduction To Quantitative BiologyMansi SharmaNo ratings yet
- Biomolecules: Module - 7Document26 pagesBiomolecules: Module - 7TeachingTrainingCoaching KnowledgeSharingSessionNo ratings yet
- DBT-JRF BET Part A Aptitude and General Biotechnology PDFDocument5 pagesDBT-JRF BET Part A Aptitude and General Biotechnology PDFambuNo ratings yet
- Levels of Structural OrganizationDocument26 pagesLevels of Structural OrganizationKeanna ZurriagaNo ratings yet
- Science: Whole Brain Learning SystemDocument20 pagesScience: Whole Brain Learning SystemKayrell AquinoNo ratings yet
- Inter-I Bio FULL BOOK McqsDocument23 pagesInter-I Bio FULL BOOK McqsHNi QureshiNo ratings yet
- SBL100 Minor I Questions AnswersDocument25 pagesSBL100 Minor I Questions AnswersApoorva DevNo ratings yet
- Chapter 3 Biochemistry Exam: Amino Acids, Peptides, and ProteinsDocument17 pagesChapter 3 Biochemistry Exam: Amino Acids, Peptides, and ProteinsJessie90% (77)
- MSC Biotechnology Assignment QuestionpapersDocument1 pageMSC Biotechnology Assignment QuestionpapersAISHA MUHAMMADNo ratings yet
- CBSE Class 12 Chemistry Biomolecules Questions Answers PDFDocument7 pagesCBSE Class 12 Chemistry Biomolecules Questions Answers PDFLakshmi DesikanNo ratings yet
- GENERAL BIOLOGY Module PDFDocument245 pagesGENERAL BIOLOGY Module PDFKim Gyeoljong100% (1)
- Amino Acids and Proteins ReviewerDocument5 pagesAmino Acids and Proteins ReviewerDaine MarconNo ratings yet
- Chapter 25 - Synthetic and Natural Organic PolymersDocument14 pagesChapter 25 - Synthetic and Natural Organic Polymersmaniz442100% (1)
- Molecular Biology IB ReviewerDocument28 pagesMolecular Biology IB ReviewerCeline Garin ColadaNo ratings yet
- The Molecules of Cells: Campbell Biology: Concepts & ConnectionsDocument132 pagesThe Molecules of Cells: Campbell Biology: Concepts & ConnectionsIris Dinah BacaramanNo ratings yet
- Docking: Placing Ligands into Protein CavitiesDocument34 pagesDocking: Placing Ligands into Protein CavitiesAnanda VijayasarathyNo ratings yet
- Molecular Modeling of Proteins PDFDocument474 pagesMolecular Modeling of Proteins PDFLê Ngọc Chính100% (1)
- Biomolecules Chemistry AssignmentDocument28 pagesBiomolecules Chemistry AssignmentAmarendra Shukla74% (237)
- Sample Ch05Document53 pagesSample Ch05mb_13_throwawayNo ratings yet
- Mark Scheme (Results) Summer 2019: Pearson GCE in Biology (8BN0) Paper 01 Lifestyle, Transport, Genes and HealthDocument27 pagesMark Scheme (Results) Summer 2019: Pearson GCE in Biology (8BN0) Paper 01 Lifestyle, Transport, Genes and HealthMariam HasanNo ratings yet
- Quiz 1 - MacromoleculesDocument2 pagesQuiz 1 - MacromoleculesIerdna RamosNo ratings yet
- The 20 Common Amino Acids That Build ProteinsDocument50 pagesThe 20 Common Amino Acids That Build ProteinsGurdeep SinghNo ratings yet
- Biochemistry The Chemical Reactions of Living Cells 2d Ed Vols 1 2 David E. MetzlerDocument1,977 pagesBiochemistry The Chemical Reactions of Living Cells 2d Ed Vols 1 2 David E. MetzlerEvelyn Biscari100% (7)
- Bioinformatics ManualDocument117 pagesBioinformatics ManualHazo FemberaiNo ratings yet
- VRsec BIOINFORMATICSDocument2 pagesVRsec BIOINFORMATICSKudipudi SrinivasNo ratings yet
- Chapter 22 Test BankDocument46 pagesChapter 22 Test BankManas100% (1)