You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- HW 2Document8 pagesHW 2api-285777244No ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- HW 6Document14 pagesHW 6api-285777244No ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- HW 3Document10 pagesHW 3api-285777244No ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- HW 5Document1 pageHW 5api-285777244No ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- HW 7Document11 pagesHW 7api-285777244No ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- SQL StatementDocument1 pageSQL Statementapi-285777244No ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- HW 4Document12 pagesHW 4api-285777244No ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- HW 2Document13 pagesHW 2api-285777244No ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- How To Import From Saleforce To PardotDocument3 pagesHow To Import From Saleforce To Pardotapi-285777244No ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Point of TangencyDocument5 pagesPoint of Tangencyapi-285777244No ratings yet
- HW 1Document6 pagesHW 1api-285777244No ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
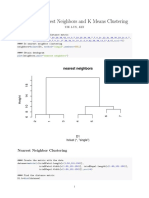
- ClusteringDocument8 pagesClusteringapi-285777244No ratings yet
- Stats101a Homework8Document7 pagesStats101a Homework8api-285777244No ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Coordinate Descent and Golden Selection SearchDocument2 pagesCoordinate Descent and Golden Selection Searchapi-285777244No ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Harmonic Seasonal ModelsDocument10 pagesHarmonic Seasonal Modelsapi-285777244No ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Adjusting BetasDocument2 pagesAdjusting Betasapi-285777244No ratings yet
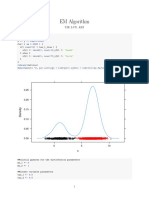
- Em AlgorithmDocument4 pagesEm Algorithmapi-285777244No ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Conditional Heteroscedastic ModelsDocument20 pagesConditional Heteroscedastic Modelsapi-285777244No ratings yet
- PCR and Pls RegressionDocument5 pagesPCR and Pls Regressionapi-285777244No ratings yet
- Handwriting RecognitionDocument10 pagesHandwriting Recognitionapi-285777244No ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Non-Stationary ModelsDocument13 pagesNon-Stationary Modelsapi-285777244No ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Generalized Additive ModelDocument10 pagesGeneralized Additive Modelapi-285777244No ratings yet
- Monte Carlo IntegrationDocument3 pagesMonte Carlo Integrationapi-285777244No ratings yet
- Variable SelectionDocument15 pagesVariable Selectionapi-285777244No ratings yet
- Gradient Steepest DescentDocument7 pagesGradient Steepest Descentapi-285777244No ratings yet
- Multivariate Monte Carlo IntegrationDocument2 pagesMultivariate Monte Carlo Integrationapi-285777244No ratings yet
- Random ForestsDocument10 pagesRandom Forestsapi-285777244No ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Practice 2 From Introductory Time Series With RDocument18 pagesPractice 2 From Introductory Time Series With Rapi-285777244No ratings yet
- Splash25 Winner InstructionsDocument8 pagesSplash25 Winner InstructionsRamkrishna PaulNo ratings yet
- Trox Quick Selection GuideDocument47 pagesTrox Quick Selection GuideErwin LouisNo ratings yet
- Chemistry For Changing Times 14th Edition Hill Mccreary Solution ManualDocument24 pagesChemistry For Changing Times 14th Edition Hill Mccreary Solution ManualElaineStewartieog100% (50)
- Army Public School No.1 Jabalpur Practical List - Computer Science Class - XIIDocument4 pagesArmy Public School No.1 Jabalpur Practical List - Computer Science Class - XIIAdityaNo ratings yet
- Enterprise GRC Solutions 2012 Executive SummaryDocument5 pagesEnterprise GRC Solutions 2012 Executive SummarySanath FernandoNo ratings yet
- 60 Plan of DepopulationDocument32 pages60 Plan of DepopulationMorena Eresh100% (1)
- KKS Equipment Matrik No PM Description PM StartDocument3 pagesKKS Equipment Matrik No PM Description PM StartGHAZY TUBeNo ratings yet
- Datasheet Brahma (2023)Document8 pagesDatasheet Brahma (2023)Edi ForexNo ratings yet
- Decolonization DBQDocument3 pagesDecolonization DBQapi-493862773No ratings yet
- TOPIC 2 - Fans, Blowers and Air CompressorDocument69 pagesTOPIC 2 - Fans, Blowers and Air CompressorCllyan ReyesNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Alliance For ProgressDocument19 pagesAlliance For ProgressDorian EusseNo ratings yet
- Notes 3 Mineral Dressing Notes by Prof. SBS Tekam PDFDocument3 pagesNotes 3 Mineral Dressing Notes by Prof. SBS Tekam PDFNikhil SinghNo ratings yet
- You'Re My Everything - Glenn FredlyDocument2 pagesYou'Re My Everything - Glenn FredlyTommy Juliansyah MarsenoNo ratings yet
- Mywizard For AIOps - Virtual Agent (ChatBOT)Document27 pagesMywizard For AIOps - Virtual Agent (ChatBOT)Darío Aguirre SánchezNo ratings yet
- Case Study On "Unilever in Brazil-Marketing Strategies For Low Income Consumers "Document15 pagesCase Study On "Unilever in Brazil-Marketing Strategies For Low Income Consumers "Deepak BajpaiNo ratings yet
- The Path Vol 9 - William JudgeDocument472 pagesThe Path Vol 9 - William JudgeMark R. JaquaNo ratings yet
- Interventional Studies 2Document28 pagesInterventional Studies 2Abdul RazzakNo ratings yet
- CHAPTER THREE-Teacher's PetDocument3 pagesCHAPTER THREE-Teacher's PetTaylor ComansNo ratings yet
- Grade 8 Least Mastered Competencies Sy 2020-2021: Handicraft Making Dressmaking CarpentryDocument9 pagesGrade 8 Least Mastered Competencies Sy 2020-2021: Handicraft Making Dressmaking CarpentryHJ HJNo ratings yet
- Kalitantra-Shava Sadhana - WikipediaDocument5 pagesKalitantra-Shava Sadhana - WikipediaGiano BellonaNo ratings yet
- Hydraulic Excavator: Engine WeightsDocument28 pagesHydraulic Excavator: Engine WeightsFelipe Pisklevits LaubeNo ratings yet
- Exchange 2010 UnderstandDocument493 pagesExchange 2010 UnderstandSeKoFieNo ratings yet
- Mge - Ex11rt - Installation and User Manual PDFDocument38 pagesMge - Ex11rt - Installation and User Manual PDFRafa TejedaNo ratings yet
- Specific Instuctions To BiddersDocument37 pagesSpecific Instuctions To BiddersShahed Hussain100% (1)
- ZEROPAY WhitepaperDocument15 pagesZEROPAY WhitepaperIlham NurrohimNo ratings yet
- Speaking Quý 1 2024Document43 pagesSpeaking Quý 1 2024Khang HoàngNo ratings yet
- The Meanings of Goddess PT IIIDocument14 pagesThe Meanings of Goddess PT IIILevonce68No ratings yet
- Title - Dating Virtual To Coffee Table Keywords - Dating, Application BlogDocument3 pagesTitle - Dating Virtual To Coffee Table Keywords - Dating, Application BlogRajni DhimanNo ratings yet
- Activity 4 - Energy Flow and Food WebDocument4 pagesActivity 4 - Energy Flow and Food WebMohamidin MamalapatNo ratings yet
- Is.2750.1964 SCAFFOLDING PDFDocument32 pagesIs.2750.1964 SCAFFOLDING PDFHiren JoshiNo ratings yet
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- Coders at Work: Reflections on the Craft of ProgrammingFrom EverandCoders at Work: Reflections on the Craft of ProgrammingRating: 4 out of 5 stars4/5 (151)
- How to Make a Video Game All By Yourself: 10 steps, just you and a computerFrom EverandHow to Make a Video Game All By Yourself: 10 steps, just you and a computerRating: 5 out of 5 stars5/5 (1)
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet