You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Developer Guide - BitcoinDocument55 pagesDeveloper Guide - BitcoinOserNo ratings yet
- Wireless Sensor Networks Application Centric DesignDocument504 pagesWireless Sensor Networks Application Centric Designaminkhan830% (1)
- Configuring and Deploying Mongodb Sharded Cluster in 30 MinutesDocument11 pagesConfiguring and Deploying Mongodb Sharded Cluster in 30 Minutesbenben08No ratings yet
- Mie 1628H - Big Data Final Project Report Apple Stock Price PredictionDocument10 pagesMie 1628H - Big Data Final Project Report Apple Stock Price Predictionbenben08No ratings yet
- Test CertifDocument41 pagesTest Certifbenben08No ratings yet
- Demo MDMDocument1 pageDemo MDMbenben08No ratings yet
- NoSQL Overview ExamplesDocument15 pagesNoSQL Overview Examplesbenben08No ratings yet
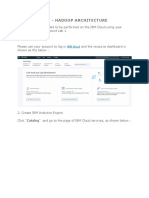
- HANDS Hadoop CloudDocument10 pagesHANDS Hadoop Cloudbenben08No ratings yet
- Practice Test 3 NewDocument22 pagesPractice Test 3 Newbenben08No ratings yet
- Cloudlab Exercise 11 Lesson 11Document2 pagesCloudlab Exercise 11 Lesson 11benben08No ratings yet
- Lab Distributed Big Data Analytics: Worksheet-3: Spark Graphx and Spark SQL OperationsDocument5 pagesLab Distributed Big Data Analytics: Worksheet-3: Spark Graphx and Spark SQL Operationsbenben08No ratings yet
- Hands-On Lab - Hadoop ComponentsDocument2 pagesHands-On Lab - Hadoop Componentsbenben08No ratings yet
- Using Bayes Network For Prediction of Type-2 Diabetes: Yan HuDocument5 pagesUsing Bayes Network For Prediction of Type-2 Diabetes: Yan Hubenben08No ratings yet
- Cognos Query StudioDocument48 pagesCognos Query Studiobenben08No ratings yet
- Exercise 2Document8 pagesExercise 2benben08No ratings yet
- Getting Started With IBM SPSS Statistics For Windows: A Training Manual For BeginnersDocument56 pagesGetting Started With IBM SPSS Statistics For Windows: A Training Manual For Beginnersbenben08No ratings yet
- Draft Program ICCAD18Document22 pagesDraft Program ICCAD18benben08No ratings yet
- Which Statistical Test: S1 S2 S3 S4 S5 S6 S7 S8 S9 S10Document5 pagesWhich Statistical Test: S1 S2 S3 S4 S5 S6 S7 S8 S9 S10benben08No ratings yet
- 1' Ere Feuille D'exercices: Travaux Dirig Es "Entrep Ots de Don Ees Et OLAP " Hiver 2012/13Document4 pages1' Ere Feuille D'exercices: Travaux Dirig Es "Entrep Ots de Don Ees Et OLAP " Hiver 2012/13benben08No ratings yet
- 5468.amba Axi Ahb ApbDocument2 pages5468.amba Axi Ahb ApbLohith CoreelNo ratings yet
- Continuity Patrol PPTv2Document14 pagesContinuity Patrol PPTv2Cast100% (1)
- Snap Upgrade Process and Installation Help GuideDocument15 pagesSnap Upgrade Process and Installation Help Guideapi-27057209No ratings yet
- Practice Test GR 11Document2 pagesPractice Test GR 11Prateek Goyal Computer5No ratings yet
- iRADV 4200 Srs 4251 4245 4235 4225 Setup GuideDocument88 pagesiRADV 4200 Srs 4251 4245 4235 4225 Setup GuidesarbihNo ratings yet
- SQL Reporting Services ArchitectureDocument6 pagesSQL Reporting Services Architectureapi-3705054100% (1)
- Solaris 10 TCP TuningDocument7 pagesSolaris 10 TCP TuningThanawoot Tinkies SongtongNo ratings yet
- Dbms Trace OutputDocument17 pagesDbms Trace Outputsalman1arif1No ratings yet
- V1600G Series OLT CLI User Manual - v1.1Document115 pagesV1600G Series OLT CLI User Manual - v1.1Krlos Andres PulgarinNo ratings yet
- 1st Summary-ICT and MM FundamentalsDocument15 pages1st Summary-ICT and MM FundamentalsAinul SyahirahNo ratings yet
- Grasp 10.0.0 Manual Ch8Document6 pagesGrasp 10.0.0 Manual Ch8Maddy MelvinNo ratings yet
- GUI Programming Using TkinterDocument62 pagesGUI Programming Using TkinterDudala NishithaNo ratings yet
- Sample UNIX Installation Directories: File DescriptionDocument2 pagesSample UNIX Installation Directories: File DescriptionSudheer GangisettyNo ratings yet
- Chatter-Cheatsheet FinalDocument4 pagesChatter-Cheatsheet Finalrajababhu3205No ratings yet
- The Posting Date For Period 2011 For Payroll Area SP Is Not MaintainedDocument2 pagesThe Posting Date For Period 2011 For Payroll Area SP Is Not MaintainedNisha KhandelwalNo ratings yet
- Ram Luitel: 221 S OAK AVE # 4, AMES, IA, 50010 515-735-2357 RLUITEL@IASTATE - EDUDocument1 pageRam Luitel: 221 S OAK AVE # 4, AMES, IA, 50010 515-735-2357 RLUITEL@IASTATE - EDUapi-377864784No ratings yet
- Free PDF Maps IndiaDocument2 pagesFree PDF Maps IndiaHeatherNo ratings yet
- cFosSpeed Setup LogDocument9 pagescFosSpeed Setup LogDimas Maulana HamzahNo ratings yet
- 1.1 Background: Web Lab Mini Project - TRAILERS WEBSITEDocument19 pages1.1 Background: Web Lab Mini Project - TRAILERS WEBSITEArun KumarNo ratings yet
- Trustwave Intrusion Detection System - Data SheetDocument2 pagesTrustwave Intrusion Detection System - Data SheetCan dien tu Thai Binh DuongNo ratings yet
- Onlin CD StoreDocument11 pagesOnlin CD StoreJetesh DevgunNo ratings yet
- Summer Training Proposal From Linux Scrappers Technologies (P) LTDDocument6 pagesSummer Training Proposal From Linux Scrappers Technologies (P) LTDAbhishek SumanNo ratings yet
- Ecg Semiconductor Replacement Guide PDFDocument78 pagesEcg Semiconductor Replacement Guide PDFJoab Max Apaza Martinez67% (9)
- Oracle Application Express: Tutorial: Building An Application Release 5.1Document98 pagesOracle Application Express: Tutorial: Building An Application Release 5.1Mardonio Jr Mangaser AgustinNo ratings yet
- Opmn Ebs 11Document11 pagesOpmn Ebs 11hgopalanNo ratings yet
- Stanford University ACM Team NotebookDocument46 pagesStanford University ACM Team Notebookthanhtam3819No ratings yet
- ICSE Java Quick ReferenceDocument2 pagesICSE Java Quick ReferenceGreatAkbar1No ratings yet
- Ethem Alpaydin Machine Learning PDFDocument2 pagesEthem Alpaydin Machine Learning PDFNiki50% (4)