You might also like
- String Algorithms in C: Efficient Text Representation and SearchFrom EverandString Algorithms in C: Efficient Text Representation and SearchNo ratings yet
- Efficient Implementation of The Generalized Tunstall Code Generation AlgorithmDocument5 pagesEfficient Implementation of The Generalized Tunstall Code Generation AlgorithmexppurposeexpNo ratings yet
- Priority Queues and MultisetsDocument18 pagesPriority Queues and MultisetsfirefoxextslurperNo ratings yet
- Topic 4 - Randomized Algorithms, II: 4.1.1 Clustering Via Graph CutsDocument6 pagesTopic 4 - Randomized Algorithms, II: 4.1.1 Clustering Via Graph CutspreethiNo ratings yet
- Josephvan ResearchsemesterfinalDocument8 pagesJosephvan Researchsemesterfinalapi-540705173No ratings yet
- CS213: Data Structures and Algorithms Shortest Path to Ghastly CheckpointDocument4 pagesCS213: Data Structures and Algorithms Shortest Path to Ghastly Checkpointarvind muraliNo ratings yet
- Daa Module 1Document26 pagesDaa Module 1Abhishek DubeyNo ratings yet
- Liniar Time Disjoint-Set by TarjanDocument13 pagesLiniar Time Disjoint-Set by TarjanAdrian BudauNo ratings yet
- Vermelho Vs AmareloDocument18 pagesVermelho Vs AmareloAlhepSoftAlhepNo ratings yet
- Answer Key DSADocument24 pagesAnswer Key DSAMathumathiNo ratings yet
- Convolution Codes: An IntroductionDocument26 pagesConvolution Codes: An IntroductionGourgobinda Satyabrata AcharyaNo ratings yet
- Balaji Problem SolvingDocument10 pagesBalaji Problem SolvingAnuj MoreNo ratings yet
- As Needed For Those Other Classes (So If You Get Lucky and Find A Solution in One ofDocument12 pagesAs Needed For Those Other Classes (So If You Get Lucky and Find A Solution in One ofYogendra MishraNo ratings yet
- Direction of Arrival Estimation Using MUSIC AlgorithmDocument14 pagesDirection of Arrival Estimation Using MUSIC AlgorithmilgisizalakasizNo ratings yet
- El Moufatich PapemjhjlklkllllllllrDocument9 pagesEl Moufatich PapemjhjlklkllllllllrNeerav AroraNo ratings yet
- MIMO Part of Module 4 NotesDocument14 pagesMIMO Part of Module 4 NotesNikhilNo ratings yet
- Bangladesh Olympiad in Informatics 2019: 1 Welcome To Bdoi 2019Document7 pagesBangladesh Olympiad in Informatics 2019: 1 Welcome To Bdoi 2019Dalia YesminNo ratings yet
- Basic PRAM Algorithm Design TechniquesDocument13 pagesBasic PRAM Algorithm Design TechniquessandeeproseNo ratings yet
- Basic of Algorithms Analysis: Computational TractabilityDocument4 pagesBasic of Algorithms Analysis: Computational TractabilityMengistu KetemaNo ratings yet
- Matlogix Question 2012Document12 pagesMatlogix Question 2012Aman04509No ratings yet
- CS1114: Study Guide 1: 1 Finding The Center of Things: Bounding Boxes, Cen-Troids, Trimmed Means, and MediansDocument9 pagesCS1114: Study Guide 1: 1 Finding The Center of Things: Bounding Boxes, Cen-Troids, Trimmed Means, and Medianslightsaber5No ratings yet
- A New Data Structure For Cumulative Frequency Tables: Peter M. FenwickDocument10 pagesA New Data Structure For Cumulative Frequency Tables: Peter M. FenwickhackerwoNo ratings yet
- Helping Hand for BeginnersDocument11 pagesHelping Hand for BeginnersOvi Poddar AntorNo ratings yet
- Measuring Computational Complexity with Time and Space BoundsDocument7 pagesMeasuring Computational Complexity with Time and Space Boundstheresa.painterNo ratings yet
- AOADocument3 pagesAOARagini KarunaNo ratings yet
- A4: Short-Time Fourier Transform (STFT) : Audio Signal Processing For Music ApplicationsDocument6 pagesA4: Short-Time Fourier Transform (STFT) : Audio Signal Processing For Music ApplicationsjcvoscribNo ratings yet
- Application of Graph Theory in Communication NetworksDocument5 pagesApplication of Graph Theory in Communication NetworksInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Experiment No.2: Aim: Introduction of Elementary and Complex Signals. TheoryDocument4 pagesExperiment No.2: Aim: Introduction of Elementary and Complex Signals. TheorySaloni Agarwal100% (1)
- Exercise 4: Self-Organizing Maps: Articial Neural Networks and Other Learning Systems, 2D1432Document7 pagesExercise 4: Self-Organizing Maps: Articial Neural Networks and Other Learning Systems, 2D1432Durai ArunNo ratings yet
- Chapter 3 AADocument13 pagesChapter 3 AAselemon GamoNo ratings yet
- Deep Learning ModelsDocument21 pagesDeep Learning Modelssajid8887570788No ratings yet
- BST 4Document7 pagesBST 4Tanya VermaNo ratings yet
- Fast Heuristic Algorithm For Travelling Salesman ProblemDocument5 pagesFast Heuristic Algorithm For Travelling Salesman ProblemSalsabila ShasaNo ratings yet
- CSE Course Algorithm AssignmentDocument20 pagesCSE Course Algorithm AssignmentMASUDUR RAHMANNo ratings yet
- Experiment No. 2Document4 pagesExperiment No. 2Sandeep KumarNo ratings yet
- CS 2420 Program 2 – Fun With RecursionDocument4 pagesCS 2420 Program 2 – Fun With Recursionishu gargNo ratings yet
- COMP 171 Data Structures and Algorithms Spring 2005Document12 pagesCOMP 171 Data Structures and Algorithms Spring 2005Gobara DhanNo ratings yet
- Kruskal PascalDocument13 pagesKruskal PascalIonut MarinNo ratings yet
- Amazon Programming and Technical Interview QuestionsDocument5 pagesAmazon Programming and Technical Interview Questionsnaveen kumarNo ratings yet
- On The Sphere Decoding Algorithm. I. Expected ComplexityDocument32 pagesOn The Sphere Decoding Algorithm. I. Expected ComplexityMohamed FaragNo ratings yet
- Crit-Bit Trees: Critbit OutputDocument16 pagesCrit-Bit Trees: Critbit OutputDavid FukNo ratings yet
- Question Bank APDocument4 pagesQuestion Bank APUtkarsh TiwariNo ratings yet
- ('Christos Papadimitriou', 'Midterm 1', ' (Solution) ') Fall 2009Document5 pages('Christos Papadimitriou', 'Midterm 1', ' (Solution) ') Fall 2009John SmithNo ratings yet
- CSC263 Assignment 1 2014Document5 pagesCSC263 Assignment 1 2014iasi2050No ratings yet
- Mca-4 MC0080 IDocument15 pagesMca-4 MC0080 ISriram ChakrapaniNo ratings yet
- IMAC XXIV ConfDocument22 pagesIMAC XXIV ConfDamian BoltezarNo ratings yet
- Intra SUST Programming Contest 2020 Preliminary 1Document10 pagesIntra SUST Programming Contest 2020 Preliminary 1Farhan TanvirNo ratings yet
- Balancing Chemical Equations: Sign N Atom Count - . - Atom CountDocument8 pagesBalancing Chemical Equations: Sign N Atom Count - . - Atom CountAnonymous GuQd67No ratings yet
- Javabe 7 Net SeqDocument4 pagesJavabe 7 Net Seqbehzad_molavi2006No ratings yet
- Theory ProblemsDocument2 pagesTheory ProblemsIulia HarasimNo ratings yet
- CMPT 710 - Complexity Outline Solutions To Exercises On Turing MachinesDocument3 pagesCMPT 710 - Complexity Outline Solutions To Exercises On Turing MachinesFarshad IzadiNo ratings yet
- Illuminating the Structure and Decoder of Parallel Concatenated Turbo CodesDocument6 pagesIlluminating the Structure and Decoder of Parallel Concatenated Turbo Codessinne4No ratings yet
- GreedyDocument22 pagesGreedylarymarklaryNo ratings yet
- DAA Module 4 - NOTESDocument21 pagesDAA Module 4 - NOTESZeha 1No ratings yet
- Lec11 PDFDocument7 pagesLec11 PDFjuanagallardo01No ratings yet
- 1960 Max: Qu, Antixing For Minimum Distortion 7Document6 pages1960 Max: Qu, Antixing For Minimum Distortion 7Chathura LakmalNo ratings yet
- CS369N: Beyond Worst-Case Analysis Lecture #5: Self-Improving AlgorithmsDocument11 pagesCS369N: Beyond Worst-Case Analysis Lecture #5: Self-Improving AlgorithmsJenny JackNo ratings yet
- Digital Communications Solutions ManualDocument48 pagesDigital Communications Solutions ManualcasdeaNo ratings yet
- Applied Econometrics Using MatlabDocument348 pagesApplied Econometrics Using MatlabMichelle WilliamsNo ratings yet
- Configure NAT on Cisco ACEDocument64 pagesConfigure NAT on Cisco ACEVmen Liar PiaggioNo ratings yet
- File Exchange Matlab CentralDocument1 pageFile Exchange Matlab CentralLidia LópezNo ratings yet
- Data Compression ExplainedDocument92 pagesData Compression ExplainedLidia López100% (1)
- Improving Tunstall Codes Using Suffix TreesDocument16 pagesImproving Tunstall Codes Using Suffix TreesLidia LópezNo ratings yet
- Matlab, Simulink - Simulink Modeling Tutorial - Train SystemDocument14 pagesMatlab, Simulink - Simulink Modeling Tutorial - Train Systembubo28No ratings yet
- Chemical Process Control A First Course With Matlab - P.C. Chau PDFDocument255 pagesChemical Process Control A First Course With Matlab - P.C. Chau PDFAli NassarNo ratings yet
- Matlab - Unknown - Artificial Neural Networks The TutorialDocument19 pagesMatlab - Unknown - Artificial Neural Networks The TutorialriotimusNo ratings yet
- Matlab - Development of Neural Network Theory For Artificial Life-Thesis - MATLAB and Java CodeDocument126 pagesMatlab - Development of Neural Network Theory For Artificial Life-Thesis - MATLAB and Java CodeHotland SitorusNo ratings yet
- Performance Record: Samsung SEI Tower 467-14 Dogok 2 Dong, Gangnam Gu, Seoul, Rep. of Korea 135-856 Tel. 82.2.3458.3000Document22 pagesPerformance Record: Samsung SEI Tower 467-14 Dogok 2 Dong, Gangnam Gu, Seoul, Rep. of Korea 135-856 Tel. 82.2.3458.3000Lidia LópezNo ratings yet
- Matlab FemDocument45 pagesMatlab Femsohailrao100% (3)
- Fanchant - Acha + Opera + Oppa Oppa + Superman 2Document3 pagesFanchant - Acha + Opera + Oppa Oppa + Superman 2Lidia LópezNo ratings yet
- Super Junior - Twins (Knock OutDocument140 pagesSuper Junior - Twins (Knock OutLidia LópezNo ratings yet
- Arduino Led Display (8 X 8 Led Matrix) - GuideDocument1 pageArduino Led Display (8 X 8 Led Matrix) - GuideMC. Rene Solis R.100% (2)
- Performance Record: Samsung SEI Tower 467-14 Dogok 2 Dong, Gangnam Gu, Seoul, Rep. of Korea 135-856 Tel. 82.2.3458.3000Document22 pagesPerformance Record: Samsung SEI Tower 467-14 Dogok 2 Dong, Gangnam Gu, Seoul, Rep. of Korea 135-856 Tel. 82.2.3458.3000Lidia LópezNo ratings yet
- Semiconductor Technical Data: Mechanical CharacteristicsDocument3 pagesSemiconductor Technical Data: Mechanical CharacteristicsAjay TomarNo ratings yet
- Semiconductor Technical Data: Mechanical CharacteristicsDocument3 pagesSemiconductor Technical Data: Mechanical CharacteristicsAjay TomarNo ratings yet
- Filtro FirDocument2 pagesFiltro FirLidia LópezNo ratings yet
- UFED Solutions Brochure WebDocument4 pagesUFED Solutions Brochure Webwilly irawanNo ratings yet
- Engineering Data, Summary of Productivity 2022Document2 pagesEngineering Data, Summary of Productivity 2022Listya AnggrainiNo ratings yet
- Rc16-17 Etc Sem-IV, May 19Document5 pagesRc16-17 Etc Sem-IV, May 19Prasad KavthakarNo ratings yet
- Varco Manual ElevatorDocument54 pagesVarco Manual ElevatorJohn Jairo Simanca Castillo100% (1)
- Active Directory Command Line OneDocument9 pagesActive Directory Command Line OneSreenivasan NagappanNo ratings yet
- MTBE Presintation For IMCODocument26 pagesMTBE Presintation For IMCOMaryam AlqasimyNo ratings yet
- Cisco As5300 Voice GatewayDocument12 pagesCisco As5300 Voice GatewayAbderrahmane AbdmezianeNo ratings yet
- CH Sravan KumarDocument5 pagesCH Sravan KumarJohnNo ratings yet
- YEZ-Conical Brake MotorDocument3 pagesYEZ-Conical Brake MotorMech MallNo ratings yet
- Difference Between AND: Shahirah Nadhirah Madihah Suhana AtiqahDocument11 pagesDifference Between AND: Shahirah Nadhirah Madihah Suhana AtiqahShahirah ZafirahNo ratings yet
- 6303A HP Flare Drain DrumDocument16 pages6303A HP Flare Drain DrumMohammad MohseniNo ratings yet
- RCE Unpacking Ebook (Translated by LithiumLi) - UnprotectedDocument2,342 pagesRCE Unpacking Ebook (Translated by LithiumLi) - Unprotecteddryten7507No ratings yet
- Learning Resource Management Made SimpleDocument12 pagesLearning Resource Management Made SimpleJosenia ConstantinoNo ratings yet
- Google Analytics Certification Test QuestionsDocument36 pagesGoogle Analytics Certification Test QuestionsRoberto Delgato100% (1)
- MGS3750 28FDocument4 pagesMGS3750 28FAndi Z Pasuloi PatongaiNo ratings yet
- SE01 SE04 SE03 SE02 E14 E13: As BuiltDocument1 pageSE01 SE04 SE03 SE02 E14 E13: As BuiltgenricNo ratings yet
- Zhao PeiDocument153 pagesZhao PeiMuhammad Haris HamayunNo ratings yet
- Ref Paper 2Document4 pagesRef Paper 2Subhanjali MyneniNo ratings yet
- Direct Burial Optic Fiber Cable Specification - KSD2019 PDFDocument5 pagesDirect Burial Optic Fiber Cable Specification - KSD2019 PDFjerjyNo ratings yet
- Industry 4.0 FinaleDocument25 pagesIndustry 4.0 FinaleFrame UkirkacaNo ratings yet
- Smart Payment MeterDocument2 pagesSmart Payment MeterJesus Castro OrozcoNo ratings yet
- Learning One-to-One - Book ReviewDocument3 pagesLearning One-to-One - Book Reviewwhistleblower100% (1)
- Argus OXM CDocument2 pagesArgus OXM Candik100% (1)
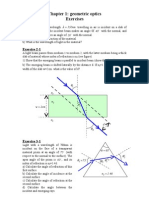
- Chap1-Geometrical Optics - ExercisesDocument3 pagesChap1-Geometrical Optics - ExercisesReema HlohNo ratings yet
- Strategic Information Systems Planning: Course OverviewDocument18 pagesStrategic Information Systems Planning: Course OverviewEmmy W. RosyidiNo ratings yet
- How To Unbrick AT&T Galaxy S5 SM-G900A Soft-Brick Fix & Restore To Stock Firmware Guide - GalaxyS5UpdateDocument21 pagesHow To Unbrick AT&T Galaxy S5 SM-G900A Soft-Brick Fix & Restore To Stock Firmware Guide - GalaxyS5UpdateMarce CJ100% (1)
- Microstructures and Mechanical Properties of Ultrafine Grained Pure Ti Produced by Severe Plastic DeformationDocument10 pagesMicrostructures and Mechanical Properties of Ultrafine Grained Pure Ti Produced by Severe Plastic Deformationsoni180No ratings yet
- Questionnaire For Future BLICZerDocument1 pageQuestionnaire For Future BLICZerAlejandra GheorghiuNo ratings yet
- # 6030 PEN OIL: Grade: Industrial Grade Heavy Duty Penetrating OilDocument3 pages# 6030 PEN OIL: Grade: Industrial Grade Heavy Duty Penetrating OilPrakash KumarNo ratings yet
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (54)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (12)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- AI Money Machine: Unlock the Secrets to Making Money Online with AIFrom EverandAI Money Machine: Unlock the Secrets to Making Money Online with AINo ratings yet
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryFrom EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryNo ratings yet
- System Design Interview: 300 Questions And Answers: Prepare And PassFrom EverandSystem Design Interview: 300 Questions And Answers: Prepare And PassNo ratings yet
- How to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.From EverandHow to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.No ratings yet
- 100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesFrom Everand100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesNo ratings yet
- 2084: Artificial Intelligence and the Future of HumanityFrom Everand2084: Artificial Intelligence and the Future of HumanityRating: 4 out of 5 stars4/5 (81)
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)
- Midjourney Mastery - The Ultimate Handbook of PromptsFrom EverandMidjourney Mastery - The Ultimate Handbook of PromptsRating: 4.5 out of 5 stars4.5/5 (2)
- ChatGPT 4 $10,000 per Month #1 Beginners Guide to Make Money Online Generated by Artificial IntelligenceFrom EverandChatGPT 4 $10,000 per Month #1 Beginners Guide to Make Money Online Generated by Artificial IntelligenceNo ratings yet
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceFrom EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceRating: 4.5 out of 5 stars4.5/5 (38)