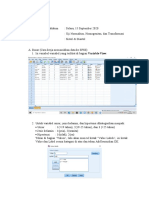
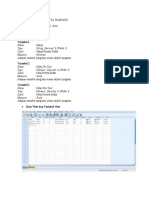
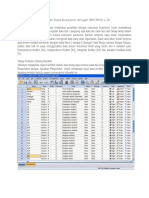
You might also like
- Buku Latihan SPSS - Statistik MultivariatDocument356 pagesBuku Latihan SPSS - Statistik Multivariatv劉玉龍100% (14)
- Uji Normalitas Dan Homogenitas Data Dengan SpssDocument35 pagesUji Normalitas Dan Homogenitas Data Dengan SpssAnggun ari aditia utamiNo ratings yet
- Makalah Uji Mann WhitneyDocument18 pagesMakalah Uji Mann WhitneySultani100% (2)
- Uji Normalitas Data StatistikDocument29 pagesUji Normalitas Data StatistikTri Cahyono100% (3)
- Analisis Deskriptif Data PrimerDocument26 pagesAnalisis Deskriptif Data Primersok laNo ratings yet
- Tips Seminar Proposal SkripsiDocument20 pagesTips Seminar Proposal SkripsiAgus SubhanNo ratings yet
- Uji Chi Square Dengan SPSS LengkapDocument6 pagesUji Chi Square Dengan SPSS LengkapnyawdnyNo ratings yet
- Metodologi Penelitian EkonometrikaDocument20 pagesMetodologi Penelitian EkonometrikaAziez Ya AzizNo ratings yet
- Perbedaan Analisis Univariat Dan MultivariatDocument13 pagesPerbedaan Analisis Univariat Dan MultivariatWandhansari Sekar JatiningrumNo ratings yet
- Buku Statistik Uji NormalitasDocument67 pagesBuku Statistik Uji NormalitasTri Cahyono85% (13)
- Analisis Regresi Logistik PDFDocument33 pagesAnalisis Regresi Logistik PDFYessy Dwi Oktavia100% (2)
- Makalah Kolmogorov SmirnovDocument13 pagesMakalah Kolmogorov SmirnovThathaNttuewYunietha100% (1)
- Pengantar Kuesioner PenelitianDocument4 pagesPengantar Kuesioner PenelitianSharanjit DhillonNo ratings yet
- REGRESI DENGAN DUA VARIABEL Bab 3Document11 pagesREGRESI DENGAN DUA VARIABEL Bab 3andy bahrudinNo ratings yet
- Makalah One-Way ANOVADocument15 pagesMakalah One-Way ANOVAMuhammad Nurudin IslamiNo ratings yet
- UjiNormalitasDocument2 pagesUjiNormalitasAriza VaneshaNo ratings yet
- Mudul SPSSDocument52 pagesMudul SPSSamien100% (2)
- Uji Normalitas Dan Homogenitas Menggunakan Ms Excel Dan Spss 20Document17 pagesUji Normalitas Dan Homogenitas Menggunakan Ms Excel Dan Spss 20Siti FaizamiNo ratings yet
- Analisis Model Kinerja Pemasaran Menggunakan AMOSDocument7 pagesAnalisis Model Kinerja Pemasaran Menggunakan AMOSKomik Chapter100% (1)
- ANALISIS KORELASIDocument26 pagesANALISIS KORELASINabila NurfadillaNo ratings yet
- Cara Menggunakan SPSS by Digi.Document19 pagesCara Menggunakan SPSS by Digi.ilham fuadiNo ratings yet
- KORELASIDocument78 pagesKORELASIWin TariganNo ratings yet
- REGRESI LINIERDocument22 pagesREGRESI LINIERmiu mauNo ratings yet
- Uji Normalitas Dan Homogenitas MenggunakDocument18 pagesUji Normalitas Dan Homogenitas Menggunakayu kartikaNo ratings yet
- Uji Homogenitas-Menggunakan-Ms-Excel-Dan-Spss-20Document15 pagesUji Homogenitas-Menggunakan-Ms-Excel-Dan-Spss-20Claravia Putri AuliaNo ratings yet
- Ppt Prak Apl Statis_kelompok 2_pspm 20 bDocument21 pagesPpt Prak Apl Statis_kelompok 2_pspm 20 bPutri Hasanah HarahapNo ratings yet
- Tutorial SPSSDocument38 pagesTutorial SPSSMuhammad RidhaNo ratings yet
- UJI NORMALITAS DAN ASUMSI KLASIKDocument8 pagesUJI NORMALITAS DAN ASUMSI KLASIKMira ArifahNo ratings yet
- Uji Normalitas Dan Homogenitas Menggunakan Ms Excel Dan Spss 20Document17 pagesUji Normalitas Dan Homogenitas Menggunakan Ms Excel Dan Spss 20Gavih Aryadi100% (1)
- Statistika Tutorial Smart Pls & Lisrel FixDocument42 pagesStatistika Tutorial Smart Pls & Lisrel FixfidyaNo ratings yet
- Statistik Deskriptif SpssDocument16 pagesStatistik Deskriptif Spssricky OkNo ratings yet
- Bab 7 Uji Asumsi KlsikDocument33 pagesBab 7 Uji Asumsi KlsikWahyudi YudhiNo ratings yet
- 2 Stat Deskriptif & HistogramDocument15 pages2 Stat Deskriptif & HistogramhedicupiadiNo ratings yet
- Statistik Deskriptif Bab 1 FIXDocument22 pagesStatistik Deskriptif Bab 1 FIXDwi HarniNo ratings yet
- Teknik Analisis Data Dengan MenggunakanDocument50 pagesTeknik Analisis Data Dengan MenggunakanhandaniNo ratings yet
- Mengolah Data Kuesioner Dengan IBM SPSS V 20 Blog Belajar StatistikDocument41 pagesMengolah Data Kuesioner Dengan IBM SPSS V 20 Blog Belajar StatistikHanisullah0% (1)
- Analisis Regresi Linier SederhanaDocument12 pagesAnalisis Regresi Linier SederhanaNur AzizahNo ratings yet
- Belajar Sendiri SPSS 16Document32 pagesBelajar Sendiri SPSS 16Amri Nur IkhsanNo ratings yet
- SPSS 16Document32 pagesSPSS 16Arya Cakra BuanaNo ratings yet
- Vector AutoregressiveDocument27 pagesVector AutoregressiveAzwar JunaidiNo ratings yet
- REGRESI MULTIPLEDocument9 pagesREGRESI MULTIPLEnurfauziyyahepNo ratings yet
- Tutorial Regresi Excel Dan KalkulatorDocument8 pagesTutorial Regresi Excel Dan KalkulatorSyfa NSNo ratings yet
- Analisis Regresi Dalam Excel - Uji StatistikDocument5 pagesAnalisis Regresi Dalam Excel - Uji StatistikArdian Eko WahonoNo ratings yet
- Modul SPSS Intervening Variabel - Data PrimerDocument28 pagesModul SPSS Intervening Variabel - Data PrimerRinaldyValentinoJohannesNo ratings yet
- PenjelasanDocument3 pagesPenjelasanfadlifrhn FRFNo ratings yet
- 4-regresiDocument7 pages4-regresiJiannNo ratings yet
- Analisis Regresi Dalam ExcelDocument5 pagesAnalisis Regresi Dalam ExcelCANDERA100% (1)
- Uji Validitas RumusDocument4 pagesUji Validitas RumusFebri PermanaNo ratings yet
- Latihan Mengolah Data SPSS Mahasiswa FKDocument19 pagesLatihan Mengolah Data SPSS Mahasiswa FKNurul SimatupangNo ratings yet
- STATISTIKDocument16 pagesSTATISTIKPangeran ZakirNo ratings yet
- Deskripsi Data Dengan SPSSDocument5 pagesDeskripsi Data Dengan SPSSCANDERANo ratings yet
- Regresi DG ExcellDocument13 pagesRegresi DG Excelltarisa suwandiNo ratings yet
- Cara SpssDocument11 pagesCara SpssAnonymous XIwe3KKNo ratings yet
- Uji Regresi NewDocument9 pagesUji Regresi NewhenridaNo ratings yet
- Tutorial SpssDocument9 pagesTutorial SpssamienNo ratings yet
- Variabel dan Analisis Regresi pada Studi Efikasi Diri dan Regulasi Diri SiswaDocument29 pagesVariabel dan Analisis Regresi pada Studi Efikasi Diri dan Regulasi Diri SiswaVivi NusitaNo ratings yet
- Olah Data Kuesioner Dengan SPSSDocument19 pagesOlah Data Kuesioner Dengan SPSSFuadNo ratings yet
- Statistik DeskriptifDocument4 pagesStatistik DeskriptifAryo ManciniNo ratings yet
- Membuat Aplikasi Bisnis Menggunakan Visual Studio Lightswitch 2013From EverandMembuat Aplikasi Bisnis Menggunakan Visual Studio Lightswitch 2013Rating: 3.5 out of 5 stars3.5/5 (7)