You might also like
- Instructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYFrom EverandInstructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYNo ratings yet
- LSDDocument7 pagesLSDkasuwedaNo ratings yet
- Regression An OvaDocument24 pagesRegression An Ovaatul_sanchetiNo ratings yet
- Validation Case: Flow Past A Cylinder: November 19, 2018Document3 pagesValidation Case: Flow Past A Cylinder: November 19, 2018hieuleeNo ratings yet
- ANOVADocument6 pagesANOVAkasuwedaNo ratings yet
- Median PDocument5 pagesMedian PYeni RahkmawatiNo ratings yet
- Median Polish: PurposeDocument5 pagesMedian Polish: PurposeYeni RahkmawatiNo ratings yet
- HW6 Solutions: Box-Cox Transformation Improves Residual PlotDocument4 pagesHW6 Solutions: Box-Cox Transformation Improves Residual PlotSouleymane CoulibalyNo ratings yet
- Beam 3Document20 pagesBeam 3MARIO MARCELONo ratings yet
- Beam 3Document20 pagesBeam 3MARIO MARCELONo ratings yet
- Ohm's Law Report - GRADED - Tamim Mahmud - 201800463Document10 pagesOhm's Law Report - GRADED - Tamim Mahmud - 201800463AbdulNo ratings yet
- Linear Algebra IiiDocument9 pagesLinear Algebra Iiirain wilsonNo ratings yet
- Guidelines For Lab Report 2017Document4 pagesGuidelines For Lab Report 2017Thinesh BoltNo ratings yet
- Practical Use of Core Data For Shale PetrophysicsDocument27 pagesPractical Use of Core Data For Shale Petrophysicsالجيولوجي محمد عثمانNo ratings yet
- Computer AssignmentDocument679 pagesComputer Assignmentjahanvi vermaNo ratings yet
- PhysRevLett 103 099902 PDFDocument1 pagePhysRevLett 103 099902 PDFMelinda NagyNo ratings yet
- Calculating RMRDocument15 pagesCalculating RMRГ. СүхбатNo ratings yet
- Continuous Beam AnalysisDocument20 pagesContinuous Beam AnalysisvnkatNo ratings yet
- SNM UNIT 2 Work Sheet NEW PDFDocument20 pagesSNM UNIT 2 Work Sheet NEW PDFRAJANo ratings yet
- Kinetics Lab ReportDocument9 pagesKinetics Lab ReportRonan ReyesNo ratings yet
- FEA Project ReportDocument24 pagesFEA Project Reportmumo86No ratings yet
- 4th Edition Ch4, AppliedDocument42 pages4th Edition Ch4, AppliedAthar Hussain TanwriNo ratings yet
- Combination of Resistors in Series and ParallelDocument8 pagesCombination of Resistors in Series and Parallelmubarik aliNo ratings yet
- Measure of central tendencyDocument19 pagesMeasure of central tendencyparthgupta782003No ratings yet
- 05 Modellingtutorial - 1storderresponses - NADocument2 pages05 Modellingtutorial - 1storderresponses - NAElie KabangaNo ratings yet
- Lecture 07Document19 pagesLecture 07Abdur RafayNo ratings yet
- The University of Auckland: Second Semester, 2004 Campus: CityDocument23 pagesThe University of Auckland: Second Semester, 2004 Campus: CityPiNo ratings yet
- Exploratory Data Analysis: 2.1 ObjectivesDocument23 pagesExploratory Data Analysis: 2.1 ObjectivesBalu MahindraNo ratings yet
- Influence of Temperature on Asphalt Fatigue PropertiesDocument3 pagesInfluence of Temperature on Asphalt Fatigue PropertiesLeo Zuni CcamaNo ratings yet
- ANSWER KEYS StatisticsDocument16 pagesANSWER KEYS StatisticsJohn Cedrick MaglinaoNo ratings yet
- Lista2 - Regressão: Parte 1 - RoteiroDocument22 pagesLista2 - Regressão: Parte 1 - RoteiroPaulo Marcus HarataniNo ratings yet
- CPE 221 Test 1 Solution Spring 2016Document4 pagesCPE 221 Test 1 Solution Spring 2016Kyra LathonNo ratings yet
- Time Series Analysis: Solutions to Practice ProblemsDocument82 pagesTime Series Analysis: Solutions to Practice Problemsjuve A.No ratings yet
- Mechanics of Materials Ii: Lab ManualDocument34 pagesMechanics of Materials Ii: Lab Manualsafi ur rahman khanNo ratings yet
- Additional Exercises for Vectors, Matrices, and Least SquaresDocument41 pagesAdditional Exercises for Vectors, Matrices, and Least SquaresAlejandro Patiño RiveraNo ratings yet
- Department of Chemical Engineering CH 544: Multivariate Data AnalysisDocument3 pagesDepartment of Chemical Engineering CH 544: Multivariate Data Analysisnp484No ratings yet
- 36-401 Modern Regression HW #5 Solutions: Air - FlowDocument7 pages36-401 Modern Regression HW #5 Solutions: Air - FlowSNo ratings yet
- Ejercicio 1 Practica 2 1-2020Document14 pagesEjercicio 1 Practica 2 1-2020BRAYAN MAGNE CACERESNo ratings yet
- Shear and Moment Diagrams of An Overhung Beam Using Singularity FunctionsDocument5 pagesShear and Moment Diagrams of An Overhung Beam Using Singularity FunctionsDiana Wagner WinterNo ratings yet
- Synchronous Generator Transient Analysis: Experiment NoDocument12 pagesSynchronous Generator Transient Analysis: Experiment NoRiya RaNo ratings yet
- Probability and Statistics: Code: CAT-208 Bca-Iii SemDocument11 pagesProbability and Statistics: Code: CAT-208 Bca-Iii SemSandeep MoghaNo ratings yet
- To Determine The Reactions of Simply Supported Beams Subjected To Two LoadsDocument2 pagesTo Determine The Reactions of Simply Supported Beams Subjected To Two LoadsArindam MondalNo ratings yet
- Arch Model and Time-Varying VolatilityDocument16 pagesArch Model and Time-Varying VolatilityLiem NguyenNo ratings yet
- Performance Task # 2.Document6 pagesPerformance Task # 2.Stephanie BorjaNo ratings yet
- HW4 Solutions: Problem 6.2Document8 pagesHW4 Solutions: Problem 6.2Souleymane CoulibalyNo ratings yet
- T E E B B: Electromagnetic Wave EquationsDocument38 pagesT E E B B: Electromagnetic Wave EquationsMohammad NadeemNo ratings yet
- Statastics Blue Print I Puc 2023-24 PDFDocument1 pageStatastics Blue Print I Puc 2023-24 PDFntg386206No ratings yet
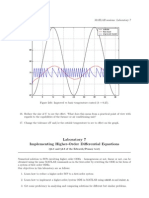
- MATLAB sessions: Laboratory 7 implementing higher-order differential equationsDocument7 pagesMATLAB sessions: Laboratory 7 implementing higher-order differential equationsjlbalbNo ratings yet
- CRDDocument6 pagesCRDkasuwedaNo ratings yet
- Experimental Validation of The Dynamic InteractionDocument13 pagesExperimental Validation of The Dynamic InteractionNavid SalamiPargooNo ratings yet
- Mid Sem Exam 2021-22Document2 pagesMid Sem Exam 2021-22N Rabindra PatraNo ratings yet
- Exam1 1Document222 pagesExam1 1Tochukwupa PreizeNo ratings yet
- Signals and System: Lab Sheet - 4Document5 pagesSignals and System: Lab Sheet - 4Shravan Kumar LuitelNo ratings yet
- MAT3700 Combined Paper OctDocument11 pagesMAT3700 Combined Paper OctNhlanhla NdebeleNo ratings yet
- Sturm Liou Ville 3Document6 pagesSturm Liou Ville 3imran5705074No ratings yet
- Final Exam: Summer 2020: Please Write Your Answer in This GoogleDocument12 pagesFinal Exam: Summer 2020: Please Write Your Answer in This GoogleAjouwad Khandoker ÆdibNo ratings yet
- Univariate Volatility Models Lecture NotesDocument22 pagesUnivariate Volatility Models Lecture NotesRajulNo ratings yet
- Sample FinalDocument10 pagesSample FinalsharadpjadhavNo ratings yet
- Department of Statistics Course STATS 330: Term Test 2003. 9:00 - 10:00 Friday, Sept 19, 2003Document8 pagesDepartment of Statistics Course STATS 330: Term Test 2003. 9:00 - 10:00 Friday, Sept 19, 2003PiNo ratings yet
- WS - Half Life Challenge-WSDocument10 pagesWS - Half Life Challenge-WSNavNo ratings yet
- 5 Tricks When Ab Testing Is Off The Table - Teconomics - MediumDocument13 pages5 Tricks When Ab Testing Is Off The Table - Teconomics - MediumPETERNo ratings yet
- Cold StartDocument3 pagesCold StartPETERNo ratings yet
- Methylated Spirits Msds 56454 Jun08Document8 pagesMethylated Spirits Msds 56454 Jun08PETERNo ratings yet
- Special Methylated Spirit 70% Untinted: Material Safety Data SheetDocument3 pagesSpecial Methylated Spirit 70% Untinted: Material Safety Data SheetPETERNo ratings yet
- Digital StrategyDocument4 pagesDigital StrategyPETERNo ratings yet
- Safety Data Sheet: Die Hardener PremiumDocument7 pagesSafety Data Sheet: Die Hardener PremiumPiNo ratings yet
- Robots Mean Business A Conversation With Rodney BrooksDocument4 pagesRobots Mean Business A Conversation With Rodney BrooksPiNo ratings yet
- Analytics in Action With Teradata CloudDocument19 pagesAnalytics in Action With Teradata CloudPETERNo ratings yet
- Sky TeamDocument22 pagesSky TeamPETERNo ratings yet
- Vertex Self Curing LiquidDocument18 pagesVertex Self Curing LiquidPETERNo ratings yet
- Modelling Wax MSDSDocument4 pagesModelling Wax MSDSPETERNo ratings yet
- Methylated Spirits Msds 56454 Jun08Document8 pagesMethylated Spirits Msds 56454 Jun08PETERNo ratings yet
- Wacker Catalyst T 35Document6 pagesWacker Catalyst T 35PETERNo ratings yet
- MethylatedDocument3 pagesMethylatedPETERNo ratings yet
- Msds SDHDocument2 pagesMsds SDHPETERNo ratings yet
- 989 800 12Document5 pages989 800 12PETERNo ratings yet
- Msds B50Document3 pagesMsds B50PETERNo ratings yet
- Dentaurum Rema Exakt, Rema Exakt F Mixing LiquidDocument6 pagesDentaurum Rema Exakt, Rema Exakt F Mixing LiquidPETERNo ratings yet
- File Vertex Ortoplast Polvere Scheda Di SicurezzaDocument6 pagesFile Vertex Ortoplast Polvere Scheda Di SicurezzaPiNo ratings yet
- Ips Inline System Glaze and Stains LiquidDocument5 pagesIps Inline System Glaze and Stains LiquidPETERNo ratings yet
- Eligible Occupations For The Hecs Help BenefitDocument3 pagesEligible Occupations For The Hecs Help BenefitPiNo ratings yet
- Hazardous Substance Fact Sheet: Right To KnowDocument6 pagesHazardous Substance Fact Sheet: Right To KnowPETERNo ratings yet
- 2015 Prices Fees SubsidiesDocument16 pages2015 Prices Fees SubsidiesPETERNo ratings yet
- 128 301 20Document4 pages128 301 20PETERNo ratings yet
- 2015 Student FeesDocument24 pages2015 Student FeesPETERNo ratings yet
- 20Document9 pages20PiNo ratings yet
- Government Response: Pricing VET Under Smart and Skilled - Final ReportDocument7 pagesGovernment Response: Pricing VET Under Smart and Skilled - Final ReportPETERNo ratings yet
- 2015 Prices Fees SubsidiesDocument18 pages2015 Prices Fees SubsidiesPETERNo ratings yet
- 2014 Skills List at Qualification V2Document20 pages2014 Skills List at Qualification V2PETERNo ratings yet
- Sp16 6us PDFDocument97 pagesSp16 6us PDFPETERNo ratings yet
- Forecasting Techniques and Models for Operations PlanningDocument37 pagesForecasting Techniques and Models for Operations PlanningTony TangNo ratings yet
- Effect of Load Modeling On Voltage StabilityDocument6 pagesEffect of Load Modeling On Voltage Stabilityiniran2No ratings yet
- ML approaches to variance component estimationDocument20 pagesML approaches to variance component estimationEdmo CavalcanteNo ratings yet
- ETAM 2010 Multi-Objective EDM ModelDocument9 pagesETAM 2010 Multi-Objective EDM ModelVicky VigneshNo ratings yet
- Brand Mindset Metrics and Market PerformanceDocument13 pagesBrand Mindset Metrics and Market PerformanceAldi HartonoNo ratings yet
- Research MethodologyDocument20 pagesResearch MethodologySahil BansalNo ratings yet
- CH 5 Test BankDocument75 pagesCH 5 Test BankJB50% (2)
- Manual Basic LAboratoryDocument245 pagesManual Basic LAboratoryAngelo Palaming100% (2)
- Minitab Multiple Regression AnalysisDocument6 pagesMinitab Multiple Regression Analysisbuat akunNo ratings yet
- Methodology and Application of One-Way ANOVA: KeywordsDocument6 pagesMethodology and Application of One-Way ANOVA: KeywordsDan Lhery Susano GregoriousNo ratings yet
- Interpret Standard Deviation Outlier Rule: Using Normalcdf and Invnorm (Calculator Tips)Document12 pagesInterpret Standard Deviation Outlier Rule: Using Normalcdf and Invnorm (Calculator Tips)maryrachel713No ratings yet
- Parametric Time Domain ModellingDocument54 pagesParametric Time Domain ModellingHussein RazaqNo ratings yet
- Itae002 Test 2Document150 pagesItae002 Test 2Nageshwar SinghNo ratings yet
- 7 Least Square PDFDocument34 pages7 Least Square PDFsubhamoy biswasNo ratings yet
- Is1-1 0Document27 pagesIs1-1 0Alyanna Maye Constantino100% (1)
- ECM Class 1 2 3Document65 pagesECM Class 1 2 3Mayra NiharNo ratings yet
- ML MCQs 4unitsDocument30 pagesML MCQs 4unitsGaurav RajputNo ratings yet
- Very Fast BDSDocument95 pagesVery Fast BDSWEMERSON31No ratings yet
- 18 SolutionsDocument6 pages18 SolutionsChuluunzagd BatbayarNo ratings yet
- Web PEER608 BAKER CornellDocument368 pagesWeb PEER608 BAKER CornellFadei Elena-gabrielaNo ratings yet
- Interpretation of Eviews RegressionDocument6 pagesInterpretation of Eviews RegressionRabia Nawaz100% (1)
- Unit IIIDocument27 pagesUnit IIIapi-352822682No ratings yet
- Machine Learning ABC Cuts Costly StudiesDocument45 pagesMachine Learning ABC Cuts Costly Studieshasan najiNo ratings yet
- SPSS HanaDocument2 pagesSPSS HanaNurfadila YusufNo ratings yet
- Gujarati BookDocument3 pagesGujarati BookManuel Antonio Díaz FloresNo ratings yet
- Not Just For Cointegration: Error Correction Models With Stationary Data by L Keele & S de BoefDocument19 pagesNot Just For Cointegration: Error Correction Models With Stationary Data by L Keele & S de BoefJustin ColynNo ratings yet
- Relationship Between Customer Loyalty, Repurchase & SatisfactionDocument27 pagesRelationship Between Customer Loyalty, Repurchase & SatisfactionThuraMinSweNo ratings yet
- Problem Sets (Days 1-6)Document18 pagesProblem Sets (Days 1-6)Harry KwongNo ratings yet
- PP&E Depreciation Schedule AuditDocument3 pagesPP&E Depreciation Schedule AuditThermen DarenNo ratings yet
- Solution EconometricsDocument132 pagesSolution EconometricsAbdullah Mamun Al Saud100% (2)