You might also like
- Cot4501sp17 Hw2solDocument4 pagesCot4501sp17 Hw2solNathanael HooperNo ratings yet
- 18.100C. Problem Set 8. SolutionsDocument3 pages18.100C. Problem Set 8. SolutionsJohnnyNo ratings yet
- Ugmath2020 SolutionsDocument7 pagesUgmath2020 SolutionsVaibhav BajpaiNo ratings yet
- A Calculus Misprint Ten Years LaterDocument4 pagesA Calculus Misprint Ten Years Latersobaseki1No ratings yet
- Homework 8Document4 pagesHomework 8bindumadhavibb2022No ratings yet
- Lecture 05 - UnconstrainedDocument21 pagesLecture 05 - Unconstrainedbillie quantNo ratings yet
- Mathematics-Calculus SampleDocument12 pagesMathematics-Calculus SampleconnieNo ratings yet
- Real Numbers and Sequences AssignmentDocument7 pagesReal Numbers and Sequences AssignmentSURYANSH KUMAR 18110168No ratings yet
- Problem Set 2 Solution Numerical MethodsDocument15 pagesProblem Set 2 Solution Numerical MethodsAriyan JahanyarNo ratings yet
- APPM 1345/1350 Final Exam Spring 2013Document2 pagesAPPM 1345/1350 Final Exam Spring 2013lllloNo ratings yet
- Bol1 CodigoDocument13 pagesBol1 CodigospamtonkrisNo ratings yet
- 考古答案Document9 pages考古答案余依芹No ratings yet
- Practice 4Document8 pagesPractice 4charlyrozzeNo ratings yet
- Ariesta SolusiDocument6 pagesAriesta SolusiJ Esa AditiyaNo ratings yet
- Mathematics and Statistics 1 Assignment 2: Exercise 1Document8 pagesMathematics and Statistics 1 Assignment 2: Exercise 1Carlo PattiNo ratings yet
- Errors and PropagationDocument8 pagesErrors and PropagationJhon MuñozNo ratings yet
- Introduction. Error AnalysesDocument14 pagesIntroduction. Error AnalysesdrogoNo ratings yet
- Houston K. - Complex Analysis (2003)Document98 pagesHouston K. - Complex Analysis (2003)mikeNo ratings yet
- PrelimExam SolutionDocument3 pagesPrelimExam SolutionNeil MonteroNo ratings yet
- Chapter 1 IntroductionDocument25 pagesChapter 1 IntroductionotternamedsteveNo ratings yet
- Sixth Term Examination Papers 9470 Mathematics 2 Monday 17 June 2019Document12 pagesSixth Term Examination Papers 9470 Mathematics 2 Monday 17 June 2019Joydip SahaNo ratings yet
- On the difference π (x) − li (x) : Christine LeeDocument41 pagesOn the difference π (x) − li (x) : Christine LeeKhokon GayenNo ratings yet
- Calculus1 Final Exam (2020)Document1 pageCalculus1 Final Exam (2020)xwsc4dzzyrNo ratings yet
- Sixth Term Examination Papers 9470 Mathematics 2 Monday 17 June 2019Document7 pagesSixth Term Examination Papers 9470 Mathematics 2 Monday 17 June 2019Ni PeterNo ratings yet
- Taylor Series: N 0 N N NDocument6 pagesTaylor Series: N 0 N N NtylonNo ratings yet
- Mscds2022 SolutionsDocument23 pagesMscds2022 SolutionsMohammad Faiz HashmiNo ratings yet
- 100微積分Document2 pages100微積分Tsungyen TsaiNo ratings yet
- Taylor Series: N 0 N N NDocument7 pagesTaylor Series: N 0 N N NمحمدحسنفهميNo ratings yet
- 11.10 Taylor Series PDFDocument7 pages11.10 Taylor Series PDFsaurav kumarNo ratings yet
- 11.10 Taylor SeriesDocument6 pages11.10 Taylor SeriesMadiha KhanNo ratings yet
- Calculus Test12 Sol 20191015Document7 pagesCalculus Test12 Sol 20191015Mạc Hải LongNo ratings yet
- Note 1 - Approximations and ErrorsDocument3 pagesNote 1 - Approximations and ErrorsPrimali PereraNo ratings yet
- Sample Solutions To Assignment 5.: Amath 584, Autumn 2017Document5 pagesSample Solutions To Assignment 5.: Amath 584, Autumn 2017JORDY GAMERNo ratings yet
- Fourier Series and Fourier IntegralsDocument20 pagesFourier Series and Fourier IntegralsManoj KumarNo ratings yet
- UntitledDocument23 pagesUntitledSatyam TiwariNo ratings yet
- Practice 3Document9 pagesPractice 3charlyrozzeNo ratings yet
- Solutions Sheet 2, Continuity.: Questions 7-12Document4 pagesSolutions Sheet 2, Continuity.: Questions 7-12Ranu GamesNo ratings yet
- Problem Set 2 SolutionsDocument4 pagesProblem Set 2 SolutionsandrewlimjfNo ratings yet
- The Gamma FunctionDocument20 pagesThe Gamma FunctionHenry Pomares CanchanoNo ratings yet
- Subsequences of Real NumbersDocument18 pagesSubsequences of Real Numbersohieku4struggleNo ratings yet
- ST107 Solutions 4Document5 pagesST107 Solutions 4llNo ratings yet
- Test 3 BDocument4 pagesTest 3 BHải VũNo ratings yet
- Practice Questions - Chapter4 (Continuous Distributions)Document6 pagesPractice Questions - Chapter4 (Continuous Distributions)Abdulaziz AlzahraniNo ratings yet
- Calculus ProblemsDocument1 pageCalculus ProblemsRajarshiNo ratings yet
- Sergey K. SekatskiiDocument9 pagesSergey K. SekatskiipuyoshitNo ratings yet
- Block2 Assignment PDFDocument8 pagesBlock2 Assignment PDFDenielNo ratings yet
- M597K: Solution To Homework Assignment 7: 1. Show That The Sequence (XDocument6 pagesM597K: Solution To Homework Assignment 7: 1. Show That The Sequence (XCarlosRiverosVillagraNo ratings yet
- Dawson College: Department of MathematicsDocument14 pagesDawson College: Department of Mathematicsadcyechicon123No ratings yet
- 421HWDocument60 pages421HWXiomara EscalanteNo ratings yet
- On A Particular Extension of The EV-Theorem: Print Edition: ISSN 1584 - 286X Online Edition: ISSN 1843 - 441XDocument12 pagesOn A Particular Extension of The EV-Theorem: Print Edition: ISSN 1584 - 286X Online Edition: ISSN 1843 - 441XSerban DanNo ratings yet
- Advanced Level DPP Indefinite Integration QuestionDocument12 pagesAdvanced Level DPP Indefinite Integration QuestionPriyadarshi KumarNo ratings yet
- Solution For Semester 1 (2015 - 2016)Document4 pagesSolution For Semester 1 (2015 - 2016)Sun StarNo ratings yet
- Anal II Sol02Document4 pagesAnal II Sol02hind.ouazNo ratings yet
- ConvexDocument7 pagesConvexmoeed111No ratings yet
- The International University (Iu) - Vietnam National University - HCMCDocument3 pagesThe International University (Iu) - Vietnam National University - HCMCKim Uyên Nguyen NgocNo ratings yet
- Maths Practicesheet-02 (Code-A) SolDocument9 pagesMaths Practicesheet-02 (Code-A) Solksanthosh29112006No ratings yet
- The Dirac Delta Function Overview and Motivation: The Dirac Delta Function Is A Concept That Is UsefulDocument9 pagesThe Dirac Delta Function Overview and Motivation: The Dirac Delta Function Is A Concept That Is Usefulmatrixx105No ratings yet
- Mellin Inversion Theorm 2Document3 pagesMellin Inversion Theorm 2strategicsuryaNo ratings yet
- Solutions Examination Calculus I For AE (wi1421LR), Part BDocument3 pagesSolutions Examination Calculus I For AE (wi1421LR), Part BAnon ymousNo ratings yet
- Blacs Install - PsDocument20 pagesBlacs Install - PsAkshay DeshpandeNo ratings yet
- Boiling: Change of Phase of A Fluid From Liquid To Gaseous State When Heated Is Called BoilingDocument27 pagesBoiling: Change of Phase of A Fluid From Liquid To Gaseous State When Heated Is Called BoilingAkshay DeshpandeNo ratings yet
- Structure of A Plane Shock Layer: Articles You May Be Interested inDocument13 pagesStructure of A Plane Shock Layer: Articles You May Be Interested inAkshay DeshpandeNo ratings yet
- A Brief Review of Recent Results in Vortex Induced VibrationsDocument23 pagesA Brief Review of Recent Results in Vortex Induced VibrationsAkshay DeshpandeNo ratings yet
- Circle Method For Isolated AirfoilsDocument8 pagesCircle Method For Isolated AirfoilsAkshay DeshpandeNo ratings yet
- Solar Flat Plate CollectorsDocument7 pagesSolar Flat Plate CollectorsAkshay DeshpandeNo ratings yet
- Solar TimeDocument3 pagesSolar TimeAkshay Deshpande0% (1)
- Turbines and CompressorsDocument70 pagesTurbines and CompressorsAkshay Deshpande100% (1)
- Intro About Solar RadiationDocument6 pagesIntro About Solar RadiationAkshay DeshpandeNo ratings yet
- Sun AnglesDocument7 pagesSun AnglesAkshay DeshpandeNo ratings yet
- ) tan * tan (cos 15 2 S: Incidence angle (θ)Document3 pages) tan * tan (cos 15 2 S: Incidence angle (θ)Akshay DeshpandeNo ratings yet
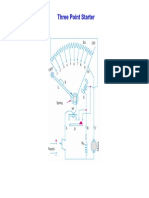
- Starter MotorDocument2 pagesStarter MotorAkshay DeshpandeNo ratings yet
- The Fuel of The FutureDocument21 pagesThe Fuel of The FutureAkshay DeshpandeNo ratings yet
- Nozzles and DiffusersDocument45 pagesNozzles and DiffusersAkshay DeshpandeNo ratings yet
- Axial, Radial TurbinesDocument91 pagesAxial, Radial TurbinesAkshay Deshpande100% (2)
- Axial Fans and CompressorsDocument32 pagesAxial Fans and CompressorsAkshay DeshpandeNo ratings yet
- Conduction and Radiation Heat Transfer : Dr. Santanu Prasad DattaDocument5 pagesConduction and Radiation Heat Transfer : Dr. Santanu Prasad DattaramsastryNo ratings yet
- CO - ACCT2522 - 1 - 2024 - Term 1 - T1 - in Person - Standard - KensingtonDocument20 pagesCO - ACCT2522 - 1 - 2024 - Term 1 - T1 - in Person - Standard - Kensingtongungnirm915No ratings yet
- Applications of Microsoft Excel in Analytical Chemistry by Stanley R Crouch F James HollerDocument7 pagesApplications of Microsoft Excel in Analytical Chemistry by Stanley R Crouch F James Holler4m1r100% (2)
- OCR C1 June 05 - Jun 10 PDFDocument25 pagesOCR C1 June 05 - Jun 10 PDFmensah142No ratings yet
- Module 4 - Theory and MethodsDocument161 pagesModule 4 - Theory and MethodsMahmoud ElnahasNo ratings yet
- Partial Differential EquationDocument18 pagesPartial Differential Equationsjo050% (1)
- Quadratic Functions Assignment: Number 2Document3 pagesQuadratic Functions Assignment: Number 2EveNo ratings yet
- NARMA-L2 (Feedback Linearization) Control - MATLAB & Simulink - MathWorks IndiaDocument5 pagesNARMA-L2 (Feedback Linearization) Control - MATLAB & Simulink - MathWorks IndiaRaveendra ReddyNo ratings yet
- Lec-4 1Document15 pagesLec-4 1RimshaNo ratings yet
- Comandos Usados en MLDocument17 pagesComandos Usados en MLJohn DannyNo ratings yet
- Concavity, Convexity, Q-Concavity & Q-ConvexityDocument4 pagesConcavity, Convexity, Q-Concavity & Q-Convexityaysun.ragipiNo ratings yet
- Risk Analysis of Gas Distribution Network PDFDocument206 pagesRisk Analysis of Gas Distribution Network PDFHedi Ben MohamedNo ratings yet
- Paper 6 Vol. 9 No - 1, 2016Document12 pagesPaper 6 Vol. 9 No - 1, 2016SANGAMESWARAN U 19MBR089No ratings yet
- Impact Evaluation in Practice (Second Edition) Offers A Comprehensive and Accessible Introduction ToDocument39 pagesImpact Evaluation in Practice (Second Edition) Offers A Comprehensive and Accessible Introduction ToJohannes StammerNo ratings yet
- Gauss Legendre IanDocument5 pagesGauss Legendre IanM Sefrian VertiesNo ratings yet
- How To Get Statistically Significant Effects in Any ERP Experiment (And Why You Shouldn't)Document12 pagesHow To Get Statistically Significant Effects in Any ERP Experiment (And Why You Shouldn't)MarttaLovesNo ratings yet
- HKDSE Mathematics (Module 1) Topic 5: Indefinite IntegrationDocument6 pagesHKDSE Mathematics (Module 1) Topic 5: Indefinite IntegrationDexter Fung100% (1)
- 06 - Pert CPMDocument22 pages06 - Pert CPMSreenath TalankiNo ratings yet
- Fourier Series and Transform BitsDocument11 pagesFourier Series and Transform BitsS AdilakshmiNo ratings yet
- APtest 3BDocument4 pagesAPtest 3BSrikar DurgamNo ratings yet
- Statistics - Elec PDFDocument3 pagesStatistics - Elec PDFAnonymous 4CQj0C5No ratings yet
- L6 Trigonometric IdentitiesDocument20 pagesL6 Trigonometric IdentitiesLorenzo Abolar100% (1)
- Mathematics-Ii (M2) For RGPV Bhopal by Dr. Akhilesh Jain, Unit 3 Partial Differential EquationDocument55 pagesMathematics-Ii (M2) For RGPV Bhopal by Dr. Akhilesh Jain, Unit 3 Partial Differential EquationakhileshNo ratings yet
- Algorithms Computer Science Practice ExamDocument6 pagesAlgorithms Computer Science Practice ExamMatthew R. PonNo ratings yet
- ISO Nominal Diameter of Tool (MM) Tolerance Designation 3-6 6-10 10-18 18-30 30-50 50-80 80-120 120-180 Tolerance (Unit 0.001 MM)Document1 pageISO Nominal Diameter of Tool (MM) Tolerance Designation 3-6 6-10 10-18 18-30 30-50 50-80 80-120 120-180 Tolerance (Unit 0.001 MM)Ahmad Shuja100% (1)
- List of Limits A4 - Wikipedia PDFDocument23 pagesList of Limits A4 - Wikipedia PDFCrystal MaxNo ratings yet
- Bertsekas) Dynamic Programming and Optimal Control - Solutions Vol 2Document31 pagesBertsekas) Dynamic Programming and Optimal Control - Solutions Vol 2larasmoyo20% (5)
- 30 Questions To Test A Data Scientist On Linear Regression PDFDocument13 pages30 Questions To Test A Data Scientist On Linear Regression PDFpyp_pypNo ratings yet
- A General Finite Element Approach To The Form Finding of Tensile Structures by The Updated Reference StrategyDocument15 pagesA General Finite Element Approach To The Form Finding of Tensile Structures by The Updated Reference StrategyMauro SogniNo ratings yet
- Displacement-Based Nonlinear Finite Element Analysis of Composite Beam-Columns With Partial InteractionDocument8 pagesDisplacement-Based Nonlinear Finite Element Analysis of Composite Beam-Columns With Partial InteractionÉsio LimaNo ratings yet