You might also like
- Problem Solving in C and Python: Programming Exercises and Solutions, Part 1From EverandProblem Solving in C and Python: Programming Exercises and Solutions, Part 1Rating: 4.5 out of 5 stars4.5/5 (2)
- CS 12-Pages-1-27Document27 pagesCS 12-Pages-1-27Marc Jairro GajudoNo ratings yet
- 11th Class CS Chapter 7 C Programming MCQsDocument3 pages11th Class CS Chapter 7 C Programming MCQsinderpreetkaurNo ratings yet
- Computer Science IADocument6 pagesComputer Science IAjessicaNo ratings yet
- 15CS31TDocument114 pages15CS31TSurya RNo ratings yet
- CompilerDocument6 pagesCompilerAayush RanaNo ratings yet
- Cdee Computer Science Upload 2015SM 3Document27 pagesCdee Computer Science Upload 2015SM 3Nikodimos EndeshawNo ratings yet
- CC QuestionsDocument9 pagesCC QuestionsjagdishNo ratings yet
- C Language Is A General Purpose and Structured Pragramming Langauge Developed byDocument12 pagesC Language Is A General Purpose and Structured Pragramming Langauge Developed byJayagowri CheluriNo ratings yet
- Task 1Document7 pagesTask 1TJ MilneNo ratings yet
- A Tale of Two Tests STANAG and CEFRDocument48 pagesA Tale of Two Tests STANAG and CEFRMisael GonçalvesNo ratings yet
- BCA 2nd Sem Assignment 2016-17Document18 pagesBCA 2nd Sem Assignment 2016-17duffuchimpsNo ratings yet
- 4CP0 02 Pef 20190822Document8 pages4CP0 02 Pef 20190822Neily WimalasiriNo ratings yet
- PRP411 Fa1Document8 pagesPRP411 Fa1Yes SurNo ratings yet
- 19CS403 PYTHON LAB EXAM QuestionsDocument7 pages19CS403 PYTHON LAB EXAM QuestionsSharan ShettyNo ratings yet
- 4 IT415 Requirement Based Test GenerationDocument14 pages4 IT415 Requirement Based Test GenerationKishan Pujara0% (1)
- Chapter FourDocument13 pagesChapter Fourn64157257No ratings yet
- CT 1 - B Answer KeyDocument6 pagesCT 1 - B Answer Keylalith jettyNo ratings yet
- Language ProcessorsDocument41 pagesLanguage ProcessorsjaydipNo ratings yet
- Data Types Used in C-Programming: Data Type Size in Bytes Storage Range RemarksDocument4 pagesData Types Used in C-Programming: Data Type Size in Bytes Storage Range Remarkssadam hussain90No ratings yet
- Krishna Kanta University BCA Examination, 2014: IiandiquiDocument5 pagesKrishna Kanta University BCA Examination, 2014: IiandiquiMridupaban DuttaNo ratings yet
- 14 Mca or C ProgrammingDocument1 page14 Mca or C ProgrammingSRINIVASA RAO GANTA100% (1)
- Compiler Construction AsigDocument1 pageCompiler Construction AsigAdeel DurraniNo ratings yet
- Chapter 3Document42 pagesChapter 3angawNo ratings yet
- Python Programming CH-9 ExercisesDocument1 pagePython Programming CH-9 ExercisesLOVEKARANNo ratings yet
- Compiler Construction Principles and Practice in 40 CharactersDocument3 pagesCompiler Construction Principles and Practice in 40 CharactersАлександр ДанюкNo ratings yet
- Alevel CDocument402 pagesAlevel CSyed A H AndrabiNo ratings yet
- Co DataDocument76 pagesCo DataTarun BeheraNo ratings yet
- C Theory and QuestionsDocument11 pagesC Theory and QuestionssurajkaulNo ratings yet
- SDT September 2015 Exam MS FinalDocument15 pagesSDT September 2015 Exam MS FinalKennedy Bernardo PhiriNo ratings yet
- Data Types in Java: Multiple Choice Questions (Tick The Correct Answers)Document12 pagesData Types in Java: Multiple Choice Questions (Tick The Correct Answers)cr4satyajit100% (1)
- Language Fundamentals C# PDFDocument46 pagesLanguage Fundamentals C# PDFshanu_agarwal89100% (2)
- 7BCE1C1 - Programming in CDocument97 pages7BCE1C1 - Programming in Ckgf0237No ratings yet
- C P Notes Submitted By: Dewanand Giri BSC - CSIT First Sem Sec A Roll:8 Submitted To: Prof - Mohan BhandariDocument27 pagesC P Notes Submitted By: Dewanand Giri BSC - CSIT First Sem Sec A Roll:8 Submitted To: Prof - Mohan BhandariDewanand GiriNo ratings yet
- C Programming QuestionsDocument15 pagesC Programming Questionsshreyarajput92542No ratings yet
- Lesson1 C Introduction1Document13 pagesLesson1 C Introduction1gcerameshNo ratings yet
- C Programming 3Document28 pagesC Programming 3Kavya MamillaNo ratings yet
- Programming in C Syllabus and Sample QuestionsDocument9 pagesProgramming in C Syllabus and Sample QuestionsShaiju PaulNo ratings yet
- THEORY of CDocument56 pagesTHEORY of CPravin Prakash AdivarekarNo ratings yet
- 3) F.Y.B.B.A. (C.A.) - Sem - I - LabBook - 2019 - Pattern - 08.07.2021Document87 pages3) F.Y.B.B.A. (C.A.) - Sem - I - LabBook - 2019 - Pattern - 08.07.2021AKSHAY GHADGENo ratings yet
- C in WordDocument107 pagesC in WordPriya ShettyNo ratings yet
- C ProgrammingDocument14 pagesC ProgrammingSakib MuhaiminNo ratings yet
- Language Fundamentals-I (Character set, keywords, identifiers, constants, variablesDocument13 pagesLanguage Fundamentals-I (Character set, keywords, identifiers, constants, variablesPavan VutukuruNo ratings yet
- Programming Languages SYLLABUSDocument2 pagesProgramming Languages SYLLABUSHema AroraNo ratings yet
- C Introduction NewDocument21 pagesC Introduction NewJyoti Kundnani ChandnaniNo ratings yet
- C Programming Keywords and Identifiers Character SetDocument26 pagesC Programming Keywords and Identifiers Character Setamandeep651No ratings yet
- CD Previous QA 2010Document64 pagesCD Previous QA 2010SagarNo ratings yet
- C-LANGUAGE Guide: Constants, Data Types, Operators & MoreDocument37 pagesC-LANGUAGE Guide: Constants, Data Types, Operators & MorePrashanthNo ratings yet
- The BCS Professional Examination Certificate April 2005 Examiners' ReportDocument17 pagesThe BCS Professional Examination Certificate April 2005 Examiners' ReportOzioma IhekwoabaNo ratings yet
- C Programming Keywords and IdentifiersDocument47 pagesC Programming Keywords and IdentifiersJaydeep SinghNo ratings yet
- Quantitative Reasoning Practice TestDocument41 pagesQuantitative Reasoning Practice TestInac ArqNo ratings yet
- MCSL-017 C and Assembly Language Programming LabDocument16 pagesMCSL-017 C and Assembly Language Programming LabSumit RanjanNo ratings yet
- prob-F-Talent 2021 Rehearsal - A.LEO Number SystemDocument4 pagesprob-F-Talent 2021 Rehearsal - A.LEO Number SystemHuy Nguyen BaNo ratings yet
- 5 - NPL - String in C#Document46 pages5 - NPL - String in C#binhkatekun2002No ratings yet
- Fundamentals of Microcontroller & Its Application: Unit-IiiDocument30 pagesFundamentals of Microcontroller & Its Application: Unit-IiiRajan PatelNo ratings yet
- ES03 Lab ManualDocument58 pagesES03 Lab ManualJeric RajalNo ratings yet
- Worksheet 1Document2 pagesWorksheet 1Biniyam DameneNo ratings yet
- C by PavanDocument34 pagesC by PavanMaddu PavanNo ratings yet
- Turbo CDocument74 pagesTurbo CAnurag GoelNo ratings yet
- C Programming Tutorial: Learn the Basics of CDocument163 pagesC Programming Tutorial: Learn the Basics of CMohit SainiNo ratings yet
- Bulletin-No.-79Document117 pagesBulletin-No.-79joNo ratings yet
- EmbeddedWorkshop 24 PiBluetoothDocument4 pagesEmbeddedWorkshop 24 PiBluetoothjoNo ratings yet
- SG7800A/SG7800 SERIES SG7800A/SG7800: Description FeaturesDocument8 pagesSG7800A/SG7800 SERIES SG7800A/SG7800: Description FeaturesjoNo ratings yet
- Commview For Wifi Technical Specifications: Wireless Network Monitor and AnalyzerDocument1 pageCommview For Wifi Technical Specifications: Wireless Network Monitor and AnalyzerjoNo ratings yet
- lm318 NDocument25 pageslm318 NjoNo ratings yet
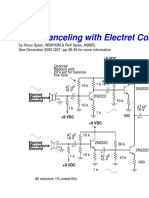
- Noise Canceling With Electret Condenser Microphones: OptionalDocument1 pageNoise Canceling With Electret Condenser Microphones: OptionaljoNo ratings yet
- Advantages of Magnetic GradiometersDocument5 pagesAdvantages of Magnetic GradiometersjoNo ratings yet
- Embedded Programming and Robotics: Lesson 15 Bluetooth and The Raspberry PiDocument22 pagesEmbedded Programming and Robotics: Lesson 15 Bluetooth and The Raspberry PiJorge PradoNo ratings yet
- Manual FLC3 70Document1 pageManual FLC3 70joNo ratings yet
- Components V 2 ADocument1 pageComponents V 2 AjoNo ratings yet
- x220t Tech SpecsDocument2 pagesx220t Tech SpecsdoombuggyNo ratings yet
- 7209 MKT Spec Technical DataDocument5 pages7209 MKT Spec Technical DatajoNo ratings yet
- Noise Canceling With Electret Condenser Microphones: OptionalDocument1 pageNoise Canceling With Electret Condenser Microphones: OptionaljoNo ratings yet
- I Do NOT Release These Programs So That YouDocument3 pagesI Do NOT Release These Programs So That YouPhearun PayNo ratings yet
- RCL-meter: (Version 1.10)Document3 pagesRCL-meter: (Version 1.10)joNo ratings yet
- RS232 - DTE and DCE Connectors: Click HereDocument4 pagesRS232 - DTE and DCE Connectors: Click HerejoNo ratings yet
- Deep Soil Ground Scanner Metal Detector CircuitDocument17 pagesDeep Soil Ground Scanner Metal Detector Circuitjo100% (1)
- Simple RF - LF Interface For A Shortwave Receiver: Klik Hier Voor de Nederlandse VersieDocument31 pagesSimple RF - LF Interface For A Shortwave Receiver: Klik Hier Voor de Nederlandse VersiejoNo ratings yet
- Hard Method, Flashing With FastbootDocument6 pagesHard Method, Flashing With FastbootjoNo ratings yet
- OP413 Analog Devices Cross Reference ResultsDocument2 pagesOP413 Analog Devices Cross Reference ResultsjoNo ratings yet
- WavebandsDocument11 pagesWavebandsjoNo ratings yet
- Some HintsDocument6 pagesSome HintsjoNo ratings yet
- Capability ListDocument16 pagesCapability ListjoNo ratings yet
- PropertiesDocument1 pagePropertiesjoNo ratings yet
- Radio Sources Dr. MorganDocument39 pagesRadio Sources Dr. MorganjoNo ratings yet
- Tools of Radio Astronomy ArticleDocument2 pagesTools of Radio Astronomy ArticlejoNo ratings yet
- RS232 - DTE and DCE Connectors: Click HereDocument4 pagesRS232 - DTE and DCE Connectors: Click HerejoNo ratings yet
- Feedhorn Vs HelixDocument2 pagesFeedhorn Vs HelixjoNo ratings yet
- Ant Data SamplesDocument4 pagesAnt Data SamplesjoNo ratings yet
- Passive VoiceDocument2 pagesPassive VoiceArni Dwi astutiNo ratings yet
- LS3 MathDocument2 pagesLS3 MathAnnie EdralinNo ratings yet
- Grammar (1-2)Document145 pagesGrammar (1-2)Mike LeeNo ratings yet
- Healthcare Chatbot Training ReportDocument29 pagesHealthcare Chatbot Training ReportRaman deepNo ratings yet
- Adjectives of Opinion CrosswordDocument3 pagesAdjectives of Opinion CrosswordVivien VíghNo ratings yet
- Vsphere Esxi Vcenter Server 60 Host Profiles GuideDocument20 pagesVsphere Esxi Vcenter Server 60 Host Profiles Guideพูลพิพัฒน์ สุขเกษมNo ratings yet
- s7 1500 Compare Table en MnemoDocument79 pagess7 1500 Compare Table en MnemoBold BéoNo ratings yet
- The Jim Morrison JournalDocument11 pagesThe Jim Morrison JournalJackob MimixNo ratings yet
- Session No. 5: Growing in The SpiritDocument6 pagesSession No. 5: Growing in The SpiritRaymond De OcampoNo ratings yet
- Pas 62405Document156 pagesPas 62405Nalex GeeNo ratings yet
- My SQLQuerysDocument24 pagesMy SQLQuerysTurboNo ratings yet
- Level: 2 Year (M.Eco) TIMING: 1 Hour.: Read The Text Carefully Then Do The ActivitiesDocument3 pagesLevel: 2 Year (M.Eco) TIMING: 1 Hour.: Read The Text Carefully Then Do The ActivitiesLarbi Nadia100% (2)
- Gr12 Language Litrature Unit 3Document157 pagesGr12 Language Litrature Unit 3Gwyn LapinidNo ratings yet
- Intro To x86Document25 pagesIntro To x86Karim NiniNo ratings yet
- Astronomy With Your PersonalDocument270 pagesAstronomy With Your PersonalKoWunnaKoNo ratings yet
- Path Loss: Sevan Siyyah AbdullahDocument20 pagesPath Loss: Sevan Siyyah Abdullahnina mimaNo ratings yet
- Quality Assurance PlanDocument7 pagesQuality Assurance Planjoe sandoval quirozNo ratings yet
- Verilog Implementation, Synthesis & Physical Design of MOD 16 CounterDocument5 pagesVerilog Implementation, Synthesis & Physical Design of MOD 16 CounterpavithrNo ratings yet
- Seatmatrix Medi Priv Can PDFDocument1 pageSeatmatrix Medi Priv Can PDFVarsha VasthaviNo ratings yet
- Manuel S. Enverga University Foundation Lucena City Granted Autonomous Status CHED CEB Res. 076-2009 College of Arts and SciencesDocument3 pagesManuel S. Enverga University Foundation Lucena City Granted Autonomous Status CHED CEB Res. 076-2009 College of Arts and SciencesLaika MerleNo ratings yet
- Zec. 9.12 God Is A RewarderDocument2 pagesZec. 9.12 God Is A RewardergmeadesNo ratings yet
- List of 616 English Irregular Verbs: Show Forms Show GroupsDocument21 pagesList of 616 English Irregular Verbs: Show Forms Show GroupsJosé SalasNo ratings yet
- Evaluation Test 6-Unit IDocument2 pagesEvaluation Test 6-Unit IРотари ДианаNo ratings yet
- Youth Camp Training OverviewDocument22 pagesYouth Camp Training OverviewAdnan AmetinNo ratings yet
- Musical DevicesDocument26 pagesMusical DevicesDave Supat TolentinoNo ratings yet
- Exercises: Basic Crud: Part I - Queries For Softuni DatabaseDocument7 pagesExercises: Basic Crud: Part I - Queries For Softuni DatabaseIon PopescuNo ratings yet
- Octal and Hexadecimal Number Systems: © 2014 Project Lead The Way, Inc. Digital ElectronicsDocument25 pagesOctal and Hexadecimal Number Systems: © 2014 Project Lead The Way, Inc. Digital ElectronicsAJNo ratings yet
- There Is - There Are - ActivitiesDocument16 pagesThere Is - There Are - ActivitiesIrene RamosNo ratings yet
- Elevation No 4 - FR Dom Paul Benoit 1948Document7 pagesElevation No 4 - FR Dom Paul Benoit 1948zimby12No ratings yet
- Markaziy Osiyo Xalqlari EtnologiyasiDocument9 pagesMarkaziy Osiyo Xalqlari EtnologiyasiSapa KurbanklichevNo ratings yet