You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Exploring Music ContentsDocument370 pagesExploring Music ContentsRoby SamboraNo ratings yet
- Meteorology Konu Konu Ayrılmış SorularDocument278 pagesMeteorology Konu Konu Ayrılmış Sorularjames100% (1)
- Ergonomic DesignDocument132 pagesErgonomic DesignErin WalkerNo ratings yet
- Obj English5Document4 pagesObj English5Bharat Chandra SahuNo ratings yet
- 3D Reconstruction Based On Stereovision and Texture MappingDocument6 pages3D Reconstruction Based On Stereovision and Texture MappingBharat Chandra SahuNo ratings yet
- Electrical CircuitDocument81 pagesElectrical CircuitBharat Chandra SahuNo ratings yet
- Tutorial 8 - Raster Data Analysis: ObjectivesDocument21 pagesTutorial 8 - Raster Data Analysis: Objectiveskarmvir27No ratings yet
- Understanding Enzymes - Trevor Palmer PDFDocument400 pagesUnderstanding Enzymes - Trevor Palmer PDFKhyal Dave86% (22)
- Cut and Fill - 1 PDFDocument5 pagesCut and Fill - 1 PDFHabeeb MaruuNo ratings yet
- Impedancematchinginawr 160207151307Document12 pagesImpedancematchinginawr 160207151307Bharat Chandra SahuNo ratings yet
- 10 1 1 61 2075Document136 pages10 1 1 61 2075Bharat Chandra SahuNo ratings yet
- General Awareness: Staff Selection Commission Combined Preliminary (Graduate Level) Exam Held On The 27th February, 2000Document3 pagesGeneral Awareness: Staff Selection Commission Combined Preliminary (Graduate Level) Exam Held On The 27th February, 2000Bharat Chandra SahuNo ratings yet
- 06478487Document4 pages06478487Bharat Chandra SahuNo ratings yet
- Ch2 Antenna BasicsDocument46 pagesCh2 Antenna BasicsChihyun Cho100% (1)
- A Prediction Study of Path Loss Models From 2-73.5 GHZ in An Urban-Macro EnvironmentDocument5 pagesA Prediction Study of Path Loss Models From 2-73.5 GHZ in An Urban-Macro EnvironmentBharat Chandra SahuNo ratings yet
- General Awareness: Solved Paper of Staff Selection Commission Section Officers' ExamDocument3 pagesGeneral Awareness: Solved Paper of Staff Selection Commission Section Officers' ExamBharat Chandra SahuNo ratings yet
- Impedancematchinginawr 160207151307Document12 pagesImpedancematchinginawr 160207151307Bharat Chandra SahuNo ratings yet
- Assignment No 1Document7 pagesAssignment No 1Bharat Chandra SahuNo ratings yet
- Journal Pone 0173627Document15 pagesJournal Pone 0173627Bharat Chandra SahuNo ratings yet
- 1703 06376 PDFDocument5 pages1703 06376 PDFBharat Chandra SahuNo ratings yet
- Moons 09Document113 pagesMoons 09Bharat Chandra SahuNo ratings yet
- Sensors 13 11007Document25 pagesSensors 13 11007Vishal NairNo ratings yet
- CalibrationDocument46 pagesCalibrationBharat Chandra SahuNo ratings yet
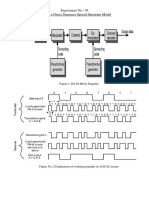
- Experiment No.: 05 Building A Direct Sequence Spread Spectrum ModelDocument6 pagesExperiment No.: 05 Building A Direct Sequence Spread Spectrum ModelBharat Chandra SahuNo ratings yet
- 1608 05384v2Document6 pages1608 05384v2Bharat Chandra SahuNo ratings yet
- Assignemnt NoDocument2 pagesAssignemnt NoBharat Chandra SahuNo ratings yet
- Image Features Detection, Description and Matching: M. Hassaballah, Aly Amin Abdelmgeid and Hammam A. AlshazlyDocument36 pagesImage Features Detection, Description and Matching: M. Hassaballah, Aly Amin Abdelmgeid and Hammam A. AlshazlyBharat Chandra SahuNo ratings yet
- Task VHDLDocument10 pagesTask VHDLBharat Chandra SahuNo ratings yet
- Psu ContactDocument6 pagesPsu ContactBharat Chandra SahuNo ratings yet
- Model Reference Adaptive 25-3-2015Document86 pagesModel Reference Adaptive 25-3-2015Bharat Chandra SahuNo ratings yet
- EE-636-MLE-IV - Parameter Estimation PDFDocument50 pagesEE-636-MLE-IV - Parameter Estimation PDFBharat Chandra SahuNo ratings yet
- Session: 2014 - 2015 (Spring)Document2 pagesSession: 2014 - 2015 (Spring)Bharat Chandra SahuNo ratings yet
- Heat Fusion of Ice ReportDocument8 pagesHeat Fusion of Ice Reporthasifah abdazizNo ratings yet
- STD XTH Geometry Maharashtra BoardDocument35 pagesSTD XTH Geometry Maharashtra Boardphanikumar50% (2)
- Hitachi HDDs Repair Scheme Based On MRT ProDocument21 pagesHitachi HDDs Repair Scheme Based On MRT ProvicvpNo ratings yet
- 3PAR DISK MatrixDocument6 pages3PAR DISK MatrixShaun PhelpsNo ratings yet
- Combined Geo-Scientist (P) Examination 2020 Paper-II (Geophysics)Document25 pagesCombined Geo-Scientist (P) Examination 2020 Paper-II (Geophysics)OIL INDIANo ratings yet
- 2018 AniketDocument60 pages2018 Aniketaniket chakiNo ratings yet
- RRB JE CBT-2 Electronics Tech Paper With Key 31-8-2019 1st ShiftDocument55 pagesRRB JE CBT-2 Electronics Tech Paper With Key 31-8-2019 1st ShiftKuldeep SinghNo ratings yet
- Genbio 1 NotesDocument1 pageGenbio 1 NoteselishaNo ratings yet
- 1 Tail & 2 Tail TestDocument3 pages1 Tail & 2 Tail TestNisha AggarwalNo ratings yet
- Aluminum: DR 900 Analytical ProcedureDocument4 pagesAluminum: DR 900 Analytical Procedurewulalan wulanNo ratings yet
- Fiberlogic CarrierEthernet 842 5300 PresentationDocument41 pagesFiberlogic CarrierEthernet 842 5300 PresentationDuong Thanh Lam0% (1)
- Workshop 2 Electrical Installations Single PhaseDocument3 pagesWorkshop 2 Electrical Installations Single PhaseDIAN NUR AIN BINTI ABD RAHIM A20MJ0019No ratings yet
- Translating Trig Graphs PDFDocument4 pagesTranslating Trig Graphs PDFMark Abion ValladolidNo ratings yet
- How Convert A Document PDF To JpegDocument1 pageHow Convert A Document PDF To Jpegblasssm7No ratings yet
- KVS - Regional Office, JAIPUR - Session 2021-22Document24 pagesKVS - Regional Office, JAIPUR - Session 2021-22ABDUL RAHMAN 11BNo ratings yet
- SM700 E WebDocument4 pagesSM700 E WebrobertwebberNo ratings yet
- 307-01 Automatic Transmission 10 Speed - Description and Operation - DescriptionDocument12 pages307-01 Automatic Transmission 10 Speed - Description and Operation - DescriptionCARLOS LIMADANo ratings yet
- Watchgas AirWatch MK1.0 Vs MK1.2Document9 pagesWatchgas AirWatch MK1.0 Vs MK1.2elliotmoralesNo ratings yet
- Limitations of Learning by Discovery - Ausubel PDFDocument14 pagesLimitations of Learning by Discovery - Ausubel PDFOpazo SebastianNo ratings yet
- Bubble Sort ExampleDocument7 pagesBubble Sort Examplenur_anis_8No ratings yet
- Type 85 Di Box DatasheetDocument2 pagesType 85 Di Box DatasheetmegadeNo ratings yet
- ADA Practical File: Kartik KatariaDocument34 pagesADA Practical File: Kartik KatariaKilari TejaNo ratings yet
- Che 410 ................... Transition Metal ChemistryDocument13 pagesChe 410 ................... Transition Metal ChemistryElizabeth AnyangoNo ratings yet
- Index Terms LinksDocument31 pagesIndex Terms Linksdeeptiwagle5649No ratings yet
- Review Skills 1-8Document1 pageReview Skills 1-8TegarNo ratings yet
- VFS1000 6000Document126 pagesVFS1000 6000krisornNo ratings yet
- Budget of Work Sci5Document1 pageBudget of Work Sci5Jhoy Angeles PinlacNo ratings yet