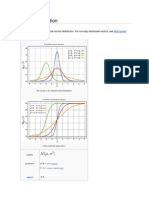
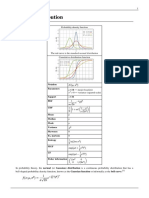
You might also like
- Probability Distribution II - Normal Distribution & Small Sampling Distribution (Students Notes) MAR 23Document27 pagesProbability Distribution II - Normal Distribution & Small Sampling Distribution (Students Notes) MAR 23halilmohamed830No ratings yet
- Debre Tabor University Econometrics AssignmentDocument8 pagesDebre Tabor University Econometrics AssignmentbantalemeNo ratings yet
- Continuous Probability DistributionDocument47 pagesContinuous Probability DistributionBrigitta AngelinaNo ratings yet
- Normal DistributionDocument40 pagesNormal DistributionaishaheavenNo ratings yet
- ECONOMETRICS BASICSDocument61 pagesECONOMETRICS BASICSmaxNo ratings yet
- PHY224H1F/324H1S Notes On Error Analysis: ReferencesDocument14 pagesPHY224H1F/324H1S Notes On Error Analysis: ReferencesHoàng Thanh TùngNo ratings yet
- Normal distribution in 40 charactersDocument941 pagesNormal distribution in 40 charactersPriya VenugopalNo ratings yet
- Probability and Statistics Mat 271EDocument50 pagesProbability and Statistics Mat 271Egio100% (1)
- Lecture No.9Document12 pagesLecture No.9Awais RaoNo ratings yet
- How to normalize an image to zero mean and unit varianceDocument16 pagesHow to normalize an image to zero mean and unit varianceGuru Ballur0% (1)
- CH9 Part IIDocument10 pagesCH9 Part IIFitsumNo ratings yet
- Lec Cont - DistDocument33 pagesLec Cont - DistTaseen Junnat SeenNo ratings yet
- Theoretical Distributions 2Document3 pagesTheoretical Distributions 2bnanduriNo ratings yet
- Econometrics: Domodar N. GujaratiDocument36 pagesEconometrics: Domodar N. GujaratiHamid UllahNo ratings yet
- AssignmentDocument11 pagesAssignmentshan khanNo ratings yet
- Normal Distribution - Wikipedia, The Free EncyclopediaDocument22 pagesNormal Distribution - Wikipedia, The Free EncyclopediaLieu Dinh PhungNo ratings yet
- Understanding the Normal Distribution in 40 CharactersDocument23 pagesUnderstanding the Normal Distribution in 40 CharactersJennifer EugenioNo ratings yet
- Regression Model AssumptionsDocument50 pagesRegression Model AssumptionsEthiop LyricsNo ratings yet
- ADocument18 pagesAfarihafairuz0% (1)
- Most Important Theoratical Questions of QTDocument26 pagesMost Important Theoratical Questions of QTIsmith PokhrelNo ratings yet
- MAS3301 Bayesian Statistics: M. Farrow School of Mathematics and Statistics Newcastle University Semester 2, 2008-9Document18 pagesMAS3301 Bayesian Statistics: M. Farrow School of Mathematics and Statistics Newcastle University Semester 2, 2008-9SimeonNo ratings yet
- Chapter 2: Continuous Probability DistributionsDocument4 pagesChapter 2: Continuous Probability DistributionsRUHDRANo ratings yet
- Chapter 3. Continuous ModelsDocument40 pagesChapter 3. Continuous ModelsPiNo ratings yet
- Normal DistributionDocument59 pagesNormal DistributionAkash Katariya100% (1)
- Normal DistributionDocument30 pagesNormal Distributionbraulio.dantas-1No ratings yet
- Chap4 ElsyDocument60 pagesChap4 ElsyKamil IbraNo ratings yet
- Continuous Probability DistributionDocument60 pagesContinuous Probability DistributionJethro MiñanoNo ratings yet
- Geometry in SpaceDocument9 pagesGeometry in SpacejennajennjenjejNo ratings yet
- Week 4 UNIT IDocument25 pagesWeek 4 UNIT IJatin MehraNo ratings yet
- Engineering Uncertainty NotesDocument15 pagesEngineering Uncertainty NotesKaren Chong YapNo ratings yet
- Q3-Module-3_by-pairDocument12 pagesQ3-Module-3_by-pairdwyanesisneros19No ratings yet
- Normal Distribution GuideDocument4 pagesNormal Distribution GuideRonald AlmagroNo ratings yet
- Chapter OneDocument39 pagesChapter OneOmotayo AbayomiNo ratings yet
- Plotting Johnson's S Distribution Using A New ParameterizationDocument7 pagesPlotting Johnson's S Distribution Using A New ParameterizationJoanne WongNo ratings yet
- Yamamura 1999 TransformacionesDocument6 pagesYamamura 1999 TransformacionesCarlos AndradeNo ratings yet
- CIV Cont RVDocument9 pagesCIV Cont RVHamza NiazNo ratings yet
- Chapter 2 Data-DrivenModelingUsingMATLAB-2Document20 pagesChapter 2 Data-DrivenModelingUsingMATLAB-2kedagaalNo ratings yet
- 03 ES Regression CorrelationDocument14 pages03 ES Regression CorrelationMuhammad AbdullahNo ratings yet
- Regression and CorrelationDocument13 pagesRegression and CorrelationzNo ratings yet
- Experiment 7: ReadingDocument10 pagesExperiment 7: ReadingSinha SrishNo ratings yet
- Uniform distribution continuous density functionDocument5 pagesUniform distribution continuous density functionafjkjchhghgfbfNo ratings yet
- MIT14 382S17 Lec7Document25 pagesMIT14 382S17 Lec7jarod_kyleNo ratings yet
- 04 NormalDistributionDocument43 pages04 NormalDistributionShane Olen GonzalesNo ratings yet
- Estimating the Variance of Errors in Regression ModelsDocument15 pagesEstimating the Variance of Errors in Regression ModelsMD Al-AminNo ratings yet
- Bivariate Extreme Statistics, Ii: Authors: Miguel de CarvalhoDocument25 pagesBivariate Extreme Statistics, Ii: Authors: Miguel de CarvalhoDamon SNo ratings yet
- Chapter 3 NorDIsDocument73 pagesChapter 3 NorDIsreg.anything29No ratings yet
- Notes ch7Document20 pagesNotes ch7Jeremy RodriquezNo ratings yet
- Probability & Probability Distribution 2Document28 pagesProbability & Probability Distribution 2Amanuel MaruNo ratings yet
- CHAPTER 7 Probability DistributionsDocument97 pagesCHAPTER 7 Probability DistributionsAyushi Jangpangi100% (1)
- Atkinson (JET70)Document20 pagesAtkinson (JET70)Karla T. MachadoNo ratings yet
- Econometrics Cheat Sheet Stock and WatsonDocument2 pagesEconometrics Cheat Sheet Stock and Watsonpeathepeanut100% (5)
- FBA1202 Statistics W10Document104 pagesFBA1202 Statistics W10ilayda demirNo ratings yet
- Eco StatDocument11 pagesEco StatRani GilNo ratings yet
- Two-Variable Regression Model EstimationDocument66 pagesTwo-Variable Regression Model EstimationKashif KhurshidNo ratings yet
- Normal Distribution: (For M.B.A. I Semester)Document29 pagesNormal Distribution: (For M.B.A. I Semester)Arun MishraNo ratings yet
- Regression Analysis Explained: Disturbance Terms, Residuals, Hypothesis TestingDocument59 pagesRegression Analysis Explained: Disturbance Terms, Residuals, Hypothesis TestingEvgenIy BokhonNo ratings yet
- Blow-up Theory for Elliptic PDEs in Riemannian Geometry (MN-45)From EverandBlow-up Theory for Elliptic PDEs in Riemannian Geometry (MN-45)No ratings yet
- Pharmacology in Mind: Xem: T : SangDocument1 pagePharmacology in Mind: Xem: T : SangDavid LeNo ratings yet
- 2020 NSBHS 7-10 Assessment PolicyDocument14 pages2020 NSBHS 7-10 Assessment PolicyDavid LeNo ratings yet
- NSBHS Activities Timetable 2020: Time Monday Tuesday Wednesday Thursday FridayDocument1 pageNSBHS Activities Timetable 2020: Time Monday Tuesday Wednesday Thursday FridayDavid LeNo ratings yet
- Test AnswersDocument1 pageTest AnswersKaren ThereseNo ratings yet
- 2021 CAT and AMC NOTE TO STUDENTSDocument2 pages2021 CAT and AMC NOTE TO STUDENTSDavid LeNo ratings yet
- Reading Practice Year 9Document7 pagesReading Practice Year 9David LeNo ratings yet
- Polya Problem-Solving Seminar Week 1: Induction and PigeonholeDocument2 pagesPolya Problem-Solving Seminar Week 1: Induction and PigeonholeDavid LeNo ratings yet
- Amc Junior 2015Document7 pagesAmc Junior 2015David Le50% (2)
- Step 4 - Select The Most Appropriate Format - ICanMedDocument1 pageStep 4 - Select The Most Appropriate Format - ICanMedDavid LeNo ratings yet
- How to write a top medical school applicationDocument1 pageHow to write a top medical school applicationDavid LeNo ratings yet
- Constructing Critical Literacy Practices Through Technology Tools and InquiryDocument12 pagesConstructing Critical Literacy Practices Through Technology Tools and InquiryDavid LeNo ratings yet
- DNA PaperDocument18 pagesDNA PaperDavid LeNo ratings yet
- ANSWER KEY SECTIONDocument14 pagesANSWER KEY SECTIONDavid LeNo ratings yet
- Pobble 2Document5 pagesPobble 2David LeNo ratings yet
- SpecDocument19 pagesSpecSayed Moin AhmedNo ratings yet
- t3 Y9 Science Theorybook 2017 SampleDocument7 pagest3 Y9 Science Theorybook 2017 SampleDavid LeNo ratings yet
- Zeter Jeff.-Extensive Reading For Academic Success. Advanced C (Answer and Key)Document12 pagesZeter Jeff.-Extensive Reading For Academic Success. Advanced C (Answer and Key)David LeNo ratings yet
- Trading Book 2Document11 pagesTrading Book 2David LeNo ratings yet
- Allsop Jake. - Penguin English Tests - Book 3 - IntermediateDocument90 pagesAllsop Jake. - Penguin English Tests - Book 3 - IntermediateDavid LeNo ratings yet
- VNDefSecinRussia DiplomatDocument1 pageVNDefSecinRussia DiplomatDavid LeNo ratings yet
- Allsop Jake.-Very Short Stories (With Exercises)Document57 pagesAllsop Jake.-Very Short Stories (With Exercises)David LeNo ratings yet
- A Voice For NatureDocument15 pagesA Voice For NatureDavid LeNo ratings yet
- Trading BookDocument5 pagesTrading BookDavid LeNo ratings yet
- Machine Learning Exam Sample QuestionsDocument9 pagesMachine Learning Exam Sample QuestionsDavid LeNo ratings yet
- Analysis of Covariance (ANCOVA) ExplainedDocument16 pagesAnalysis of Covariance (ANCOVA) ExplainedDavid LeNo ratings yet
- Trading 3Document15 pagesTrading 3David LeNo ratings yet
- Reference RosiglitazonevamyocardialinfarctionDocument8 pagesReference RosiglitazonevamyocardialinfarctionDavid LeNo ratings yet
- SSRN Id2150876 PDFDocument40 pagesSSRN Id2150876 PDFDavid LeNo ratings yet
- Topic08. Simple Linear RegDocument29 pagesTopic08. Simple Linear RegDavid LeNo ratings yet
- NetsimDocument18 pagesNetsimArpitha HsNo ratings yet
- TLE8 Q4 Week 8 As Food ProcessingDocument4 pagesTLE8 Q4 Week 8 As Food ProcessingROSELLE CASELANo ratings yet
- Machine Spindle Noses: 6 Bison - Bial S. ADocument2 pagesMachine Spindle Noses: 6 Bison - Bial S. AshanehatfieldNo ratings yet
- Module - No. 3 CGP G12. - Subong - BalucaDocument21 pagesModule - No. 3 CGP G12. - Subong - BalucaVoome Lurche100% (2)
- Afu 08504 - International Capital Bdgeting - Tutorial QuestionsDocument4 pagesAfu 08504 - International Capital Bdgeting - Tutorial QuestionsHashim SaidNo ratings yet
- ĐỀ SỐ 3Document5 pagesĐỀ SỐ 3Thanhh TrúcNo ratings yet
- Political Reporting:: Political Reporting in Journalism Is A Branch of Journalism, Which SpecificallyDocument6 pagesPolitical Reporting:: Political Reporting in Journalism Is A Branch of Journalism, Which SpecificallyParth MehtaNo ratings yet
- Lesson 2 Mathematics Curriculum in The Intermediate GradesDocument15 pagesLesson 2 Mathematics Curriculum in The Intermediate GradesRose Angel Manaog100% (1)
- Kahveci: OzkanDocument2 pagesKahveci: OzkanVictor SmithNo ratings yet
- Furnace ITV Color Camera: Series FK-CF-3712Document2 pagesFurnace ITV Color Camera: Series FK-CF-3712Italo Rodrigues100% (1)
- Amana PLE8317W2 Service ManualDocument113 pagesAmana PLE8317W2 Service ManualSchneksNo ratings yet
- Tygon S3 E-3603: The Only Choice For Phthalate-Free Flexible TubingDocument4 pagesTygon S3 E-3603: The Only Choice For Phthalate-Free Flexible TubingAluizioNo ratings yet
- Job Description Support Worker Level 1Document4 pagesJob Description Support Worker Level 1Damilola IsahNo ratings yet
- Application of ISO/IEC 17020:2012 For The Accreditation of Inspection BodiesDocument14 pagesApplication of ISO/IEC 17020:2012 For The Accreditation of Inspection BodiesWilson VargasNo ratings yet
- ULN2001, ULN2002 ULN2003, ULN2004: DescriptionDocument21 pagesULN2001, ULN2002 ULN2003, ULN2004: Descriptionjulio montenegroNo ratings yet
- Robocon 2010 ReportDocument46 pagesRobocon 2010 ReportDebal Saha100% (1)
- Steps To Configure Linux For Oracle 9i Installation: 1. Change Kernel ParametersDocument5 pagesSteps To Configure Linux For Oracle 9i Installation: 1. Change Kernel ParametersruhelanikNo ratings yet
- Device Interface Device Type (Router, Switch, Host) IP Address Subnet Mask Default GatewayDocument2 pagesDevice Interface Device Type (Router, Switch, Host) IP Address Subnet Mask Default GatewayRohit Chouhan0% (1)
- Reflection Paper #1 - Introduction To Action ResearchDocument1 pageReflection Paper #1 - Introduction To Action Researchronan.villagonzaloNo ratings yet
- AE-Electrical LMRC PDFDocument26 pagesAE-Electrical LMRC PDFDeepak GautamNo ratings yet
- Radio Theory: Frequency or AmplitudeDocument11 pagesRadio Theory: Frequency or AmplitudeMoslem GrimaldiNo ratings yet
- 5 Dec2021-AWS Command Line Interface - User GuideDocument215 pages5 Dec2021-AWS Command Line Interface - User GuideshikhaxohebkhanNo ratings yet
- NameDocument5 pagesNameMaine DagoyNo ratings yet
- ASTM D256-10 - Standard Test Methods For Determining The Izod Pendulum Impact Resistance of PlasticsDocument20 pagesASTM D256-10 - Standard Test Methods For Determining The Izod Pendulum Impact Resistance of PlasticsEng. Emílio DechenNo ratings yet
- Miami Police File The O'Nell Case - Clemen Gina D. BDocument30 pagesMiami Police File The O'Nell Case - Clemen Gina D. Barda15biceNo ratings yet
- Username: Password:: 4193 Votes 9 Days OldDocument6 pagesUsername: Password:: 4193 Votes 9 Days OldΘώμηΜπουμπαρηNo ratings yet
- Individual Sports Prelim ExamDocument13 pagesIndividual Sports Prelim ExamTommy MarcelinoNo ratings yet
- Ground Water Resources of Chennai DistrictDocument29 pagesGround Water Resources of Chennai Districtgireesh NivethanNo ratings yet
- Rheology of Polymer BlendsDocument10 pagesRheology of Polymer Blendsalireza198No ratings yet
- The Singular Mind of Terry Tao - The New York TimesDocument13 pagesThe Singular Mind of Terry Tao - The New York TimesX FlaneurNo ratings yet