You might also like
- CProg PyDocument64 pagesCProg PyClaudio PereiraNo ratings yet
- Como Aplicar A LGPD em Sua Organização - Sandro OliveiraDocument250 pagesComo Aplicar A LGPD em Sua Organização - Sandro OliveiraThiago Mele Marketing DigitalNo ratings yet
- Inteligência ArtificialDocument14 pagesInteligência Artificialamoalliti100% (1)
- Guia Carreiras Com PythonDocument12 pagesGuia Carreiras Com PythonrenatoNo ratings yet
- Algebra Linear Com Python Aprenda Na Pratica Os Principais ContistaDocument106 pagesAlgebra Linear Com Python Aprenda Na Pratica Os Principais ContistaIgor Siqueira100% (1)
- Intro Django com PythonDocument39 pagesIntro Django com PythonMayron CachinaNo ratings yet
- Orientação A Objeto em PythonDocument48 pagesOrientação A Objeto em PythonthoomaswillNo ratings yet
- Código Eficiente Com PythonDocument15 pagesCódigo Eficiente Com PythonAyke Batista100% (1)
- Relatórios automatizados por e-mailDocument54 pagesRelatórios automatizados por e-mailDioni ToledoNo ratings yet
- Ebook Django para IniciantesDocument51 pagesEbook Django para IniciantesHarley Sanders100% (1)
- Abordagem de Estudo de Caso para A Criação de Projetos de Ciência de Dados Bem-Sucedidos Usando Python, Pandas e Scikit-Learn Stephen KlostermanDocument58 pagesAbordagem de Estudo de Caso para A Criação de Projetos de Ciência de Dados Bem-Sucedidos Usando Python, Pandas e Scikit-Learn Stephen KlostermanMatheus LimaNo ratings yet
- Cientista de Dados: a profissão mais desejada do século 21Document20 pagesCientista de Dados: a profissão mais desejada do século 21Sirleudo EvaristoNo ratings yet
- Practical Big Data AnalyticsDocument145 pagesPractical Big Data AnalyticsJackson LopesNo ratings yet
- Introdução ao Python e DjangoDocument84 pagesIntrodução ao Python e DjangoGuilherme TavaresNo ratings yet
- Agilidade e qualidade na tomada de decisão com BIDocument31 pagesAgilidade e qualidade na tomada de decisão com BIAlbino MatosNo ratings yet
- Web scraping com Scrapy - Extraindo dados da WikipédiaDocument12 pagesWeb scraping com Scrapy - Extraindo dados da Wikipédiacoripheu50% (2)
- Web Scraping Com Python-Faça Da Web Sua Database2.0Document8 pagesWeb Scraping Com Python-Faça Da Web Sua Database2.0cortijoNo ratings yet
- Ferramentas Utilizadas em Ciência de Dados e Big DataDocument18 pagesFerramentas Utilizadas em Ciência de Dados e Big DataslinboyNo ratings yet
- KPL API Docs - WS PlataformaDocument186 pagesKPL API Docs - WS PlataformaMarllon Felipe Muniz De Farias AlvesNo ratings yet
- Guia para carreiras em ciência de dadosDocument60 pagesGuia para carreiras em ciência de dadosJefferson Dias100% (1)
- Trilha Recomendada - Python ImpressionadorDocument5 pagesTrilha Recomendada - Python ImpressionadorDev FragmentNo ratings yet
- Curso de Pydjango - Python e DjangoDocument205 pagesCurso de Pydjango - Python e Djangowereworf100% (2)
- Apostila Aula 3Document45 pagesApostila Aula 3David AragãoNo ratings yet
- Aula Python 04 06 2018Document376 pagesAula Python 04 06 2018João Gabriel Sousa PintoNo ratings yet
- Probabilidade e Estatística para EngenheirosDocument33 pagesProbabilidade e Estatística para EngenheirosWanly PereiraNo ratings yet
- Estatística Prática para Cientistas de DadosDocument1 pageEstatística Prática para Cientistas de DadosRenan AraujoNo ratings yet
- NBR Iso 12207 PDFDocument35 pagesNBR Iso 12207 PDFMauro Mendes100% (2)
- Formação de agrupamentos: clustering hierárquicoDocument67 pagesFormação de agrupamentos: clustering hierárquicojuanfagnerNo ratings yet
- (PDF) (Aula 6) Redes Neurais e Deep LearningDocument136 pages(PDF) (Aula 6) Redes Neurais e Deep LearningReal NotebookNo ratings yet
- Introdução Ao Terraform - Blog 4linuxDocument11 pagesIntrodução Ao Terraform - Blog 4linuxSergio Barbosa de OliveiraNo ratings yet
- Aula01 - Introdução Ao Python v1.1Document128 pagesAula01 - Introdução Ao Python v1.1noiltonNo ratings yet
- Criando Um Cadastro de Usuário em JavaDocument18 pagesCriando Um Cadastro de Usuário em JavacaiochimNo ratings yet
- Apostila Aula 1Document60 pagesApostila Aula 1Christian CarvalhoNo ratings yet
- Grafana - Criando Dashboard No Grafana - Fabiano BentoDocument10 pagesGrafana - Criando Dashboard No Grafana - Fabiano BentoRédnei Alvaro DornelasNo ratings yet
- Introdução à POO com PythonDocument63 pagesIntrodução à POO com PythonRebeca BrandãoNo ratings yet
- K-Means Clustering no SQLDocument9 pagesK-Means Clustering no SQLaluysiogcNo ratings yet
- Data Scientist: Uma jornada multidisciplinarDocument22 pagesData Scientist: Uma jornada multidisciplinarMarcello Victor100% (1)
- Afiliados Hotmart Como Eu Devo Fazer - (Guia Completo) .Document10 pagesAfiliados Hotmart Como Eu Devo Fazer - (Guia Completo) .Claudio Gomes Silva LeiteNo ratings yet
- Integrando Advpl Com Java Usando IReport - 001Document23 pagesIntegrando Advpl Com Java Usando IReport - 001Juliana Leme PavarinaNo ratings yet
- ITILDocument225 pagesITILAnderson ZuluNo ratings yet
- Prática Profissional I - Atividade 04Document2 pagesPrática Profissional I - Atividade 04João Álvaro100% (1)
- Introdução À Programação Com PythonDocument170 pagesIntrodução À Programação Com PythonRicardo Dias100% (1)
- Ciencia de Dados - Modulo 1 - Aula 2 - Engenharia de DadosDocument125 pagesCiencia de Dados - Modulo 1 - Aula 2 - Engenharia de DadosLucas Cavalcante de Almeida100% (1)
- Peças Sulcador Beija-FlorDocument7 pagesPeças Sulcador Beija-FlorVadinho BenezNo ratings yet
- PGRSCCDocument31 pagesPGRSCCThomas SilvaNo ratings yet
- Análise de Dados em Linguagem RDocument22 pagesAnálise de Dados em Linguagem RWládia Xavier100% (1)
- A Obra de Aziz Ab'Saber PDFDocument731 pagesA Obra de Aziz Ab'Saber PDFNabor JuniorNo ratings yet
- 10 Algoritmos de Machine LearningDocument11 pages10 Algoritmos de Machine Learningjoaopaulo164No ratings yet
- Estruturas de Dados em Python LDD Quais São As Finalidades Dos Algoritmos de OrdenaçãoDocument21 pagesEstruturas de Dados em Python LDD Quais São As Finalidades Dos Algoritmos de OrdenaçãoLuciano BarbosaNo ratings yet
- Exercícios Python Seção 6Document13 pagesExercícios Python Seção 6Nei WinchesterNo ratings yet
- Redes Neurais Profundas - Introdução e HistóricoDocument118 pagesRedes Neurais Profundas - Introdução e HistóricoCarlos Henrique LemosNo ratings yet
- Apostila - Módulo 2 - Bootcamp Desenvolvedor (A) PythonDocument29 pagesApostila - Módulo 2 - Bootcamp Desenvolvedor (A) PythonRodrigo KamenachNo ratings yet
- Aprendizado de Maquina Com Python - Aula 2Document109 pagesAprendizado de Maquina Com Python - Aula 2Vera SimilarNo ratings yet
- Programação Python 1Document33 pagesProgramação Python 1Guilherme BoticchioNo ratings yet
- Como aprender Python e entrar no mercado de trabalhoDocument55 pagesComo aprender Python e entrar no mercado de trabalhoagarrett3968No ratings yet
- Manual Estrutura JsonDocument5 pagesManual Estrutura JsonDiogo FelipeNo ratings yet
- Livro Introdução A Visão Computacional Com Python e OpenCV 3Document68 pagesLivro Introdução A Visão Computacional Com Python e OpenCV 3AndersonPintoNo ratings yet
- TCC Mineração de DadosDocument132 pagesTCC Mineração de DadosHelio Moreira da Silva100% (1)
- IoT MQTT Protocol GuideDocument25 pagesIoT MQTT Protocol GuideObamaDoutrinadorNo ratings yet
- Curso Machine Learning com PythonDocument241 pagesCurso Machine Learning com PythonArnoldo FurtadoNo ratings yet
- Acuracia Altimetrica MDS Representação 3D Pantanal NhecolândiaDocument7 pagesAcuracia Altimetrica MDS Representação 3D Pantanal NhecolândiaWanly PereiraNo ratings yet
- Genese Padroes Distribuiçao Minerais Secundarios Serra GeralDocument327 pagesGenese Padroes Distribuiçao Minerais Secundarios Serra GeralWanly PereiraNo ratings yet
- Estudo Sismico em Açude George SandDocument111 pagesEstudo Sismico em Açude George SandWanly PereiraNo ratings yet
- Estabilidade de taludes de solo sob carregamento sísmicoDocument16 pagesEstabilidade de taludes de solo sob carregamento sísmicoWanly PereiraNo ratings yet
- Geologia Da Formação Aquidauana Neopaleozóico PDFDocument162 pagesGeologia Da Formação Aquidauana Neopaleozóico PDFWanly PereiraNo ratings yet
- SIGEP - Vol - I Sítios Geologicos Paleontologicos BrasilDocument523 pagesSIGEP - Vol - I Sítios Geologicos Paleontologicos BrasilWanly Pereira100% (2)
- Ação Sismica - ComparaçãoDocument76 pagesAção Sismica - ComparaçãoRobsonBiavaNo ratings yet
- Evolucao Geomorfologica Mudancas Ambientais Megaleque NabilequeDocument114 pagesEvolucao Geomorfologica Mudancas Ambientais Megaleque NabilequeWanly PereiraNo ratings yet
- Taquari Construção Abandono Lobos DeposicionaisDocument67 pagesTaquari Construção Abandono Lobos DeposicionaisWanly PereiraNo ratings yet
- Catálogo CPRM 2003-2010Document366 pagesCatálogo CPRM 2003-2010Wanly PereiraNo ratings yet
- Ação Sismica - ComparaçãoDocument76 pagesAção Sismica - ComparaçãoRobsonBiavaNo ratings yet
- A Grande Colisão Pré-Cambriana Do Sudeste Brasileiro PDFDocument29 pagesA Grande Colisão Pré-Cambriana Do Sudeste Brasileiro PDFWanly PereiraNo ratings yet
- Liv14553 - Folha SF21 Campo GRande PDFDocument414 pagesLiv14553 - Folha SF21 Campo GRande PDFWanly PereiraNo ratings yet
- Introducao A Geologia Do Brasil PDFDocument63 pagesIntroducao A Geologia Do Brasil PDFWanly PereiraNo ratings yet
- Analise Combinatoria Raciocinio LogicoDocument13 pagesAnalise Combinatoria Raciocinio LogicoCelio BrasilNo ratings yet
- Matrizes Determinates Sistemas Linearesal - Cap - 01 PDFDocument55 pagesMatrizes Determinates Sistemas Linearesal - Cap - 01 PDFWanly PereiraNo ratings yet
- Todas As Fórmulas e Resumo Completo de Matemática PDFDocument22 pagesTodas As Fórmulas e Resumo Completo de Matemática PDFCamilaCarvalhodaSilvaNo ratings yet
- Bacia Do ParanáDocument24 pagesBacia Do ParanáPaula GuimaraesNo ratings yet
- Texto10ProfFred Toria Do Caos PDFDocument37 pagesTexto10ProfFred Toria Do Caos PDFWanly PereiraNo ratings yet
- Monitoramento Estruturas Estação Total PDFDocument31 pagesMonitoramento Estruturas Estação Total PDFWanly PereiraNo ratings yet
- Manual serviços topográficosDocument51 pagesManual serviços topográficosPaulo CezarNo ratings yet
- Curso de Introdução À Astronomia e AstrofísicaDocument322 pagesCurso de Introdução À Astronomia e Astrofísicaapi-3821387100% (1)
- Manual Levantamento Tsc3Document571 pagesManual Levantamento Tsc3gbetoni100% (5)
- Principais marcos históricos da educação ambientalDocument10 pagesPrincipais marcos históricos da educação ambientalWanly PereiraNo ratings yet
- Curso de Introdução À Astronomia e AstrofísicaDocument322 pagesCurso de Introdução À Astronomia e Astrofísicaapi-3821387100% (1)
- Relatório de Gestão Ministério Do Meio Ambiente 2003-2006 PDFDocument132 pagesRelatório de Gestão Ministério Do Meio Ambiente 2003-2006 PDFWanly PereiraNo ratings yet
- Avaliação Linguagem de Programação IDocument11 pagesAvaliação Linguagem de Programação IPedro Heitor Venturini LinharesNo ratings yet
- Segurança Cibernética - Propriedades e PrincípiosDocument63 pagesSegurança Cibernética - Propriedades e PrincípiosTriploc MarquesNo ratings yet
- Amd690gm M2Document16 pagesAmd690gm M2kakitosNo ratings yet
- Exercicios MicrocontroladoresDocument13 pagesExercicios MicrocontroladoresRobson CastroNo ratings yet
- DDL DML banco dados definir manipularDocument21 pagesDDL DML banco dados definir manipularValtinhoNo ratings yet
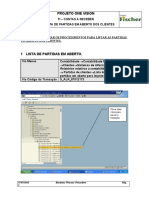
- AR F.21 - Lista de Partidas em Aberto Do ClienteDocument4 pagesAR F.21 - Lista de Partidas em Aberto Do ClienteValdevy PiresNo ratings yet
- Winsup 2Document76 pagesWinsup 2Stile MarcenariaNo ratings yet
- AtalhosDocument13 pagesAtalhosJuliana CardosoNo ratings yet
- SISTEMAS GERENCIAIS E PROCESSOSDocument5 pagesSISTEMAS GERENCIAIS E PROCESSOSSilvanoNo ratings yet
- List A 2Document4 pagesList A 2José Luiz Rybarczyk FilhoNo ratings yet
- Algebra BooleanaDocument3 pagesAlgebra BooleanaSamuel RibeiroNo ratings yet
- Acesso AVA UNIPACDocument26 pagesAcesso AVA UNIPACTALITA ELOAH GUERRA COUVEANo ratings yet
- Informática Aplicada à ModaDocument47 pagesInformática Aplicada à ModaRejane WronowskiNo ratings yet
- Seccionalizador trifásico SF6 isola falhasDocument8 pagesSeccionalizador trifásico SF6 isola falhasWilson Albert Ramos GuerrerosNo ratings yet
- Switch 3comDocument13 pagesSwitch 3comThais RamosNo ratings yet
- CA Magazine Mai03 CasasinteligentesDocument1 pageCA Magazine Mai03 Casasinteligentessandro868No ratings yet
- Uma visão do DMBOKDocument46 pagesUma visão do DMBOKEveraldo ChavesNo ratings yet
- Manual de Configuração REMUX IS720LADocument15 pagesManual de Configuração REMUX IS720LAEngenhariaNo ratings yet
- Cor Das VelasDocument5 pagesCor Das VelasJoaquimCSBarbosaNo ratings yet
- Banco de Dados I - Transações e Controle de ConcorrênciaDocument39 pagesBanco de Dados I - Transações e Controle de Concorrênciamfomoura1No ratings yet
- Cronograma Da OBMEP - Documentos GoogleDocument56 pagesCronograma Da OBMEP - Documentos GoogleMarilia MottaNo ratings yet
- Leonardo Medeiros Trujillo - 30996896Document3 pagesLeonardo Medeiros Trujillo - 30996896Wagner LimaNo ratings yet
- PA-431 - Aspectos Ambientais-V2Document4 pagesPA-431 - Aspectos Ambientais-V2fabioNo ratings yet
- Recomendações de carteiras criptoDocument3 pagesRecomendações de carteiras criptoLeonardo Maia de ÁvilaNo ratings yet
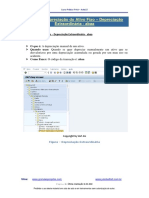
- ABAA - Depreciação Do Ativo Fixo - Depreciação ExtraordiáriaDocument4 pagesABAA - Depreciação Do Ativo Fixo - Depreciação ExtraordiáriaLaura NunesNo ratings yet