You might also like
- The most useful R commands for data analysisDocument8 pagesThe most useful R commands for data analysisVikas SinghNo ratings yet
- A Short List of The Most Useful R CommandsDocument11 pagesA Short List of The Most Useful R Commandscristiansolomon1754No ratings yet
- R BasicDocument16 pagesR BasicTaslima ChowdhuryNo ratings yet
- Spam Email Classification 3Document8 pagesSpam Email Classification 3Austin KinionNo ratings yet
- Exploratory Data AnalysisDocument5 pagesExploratory Data AnalysisCyd DuqueNo ratings yet
- Tatistical Nalysis With: Course OutlineDocument11 pagesTatistical Nalysis With: Course OutlineJack d'RebornedNo ratings yet
- Scalable Data Processing in RDocument8 pagesScalable Data Processing in ROctavio FloresNo ratings yet
- R FunctionsDocument6 pagesR FunctionsShreya GhoshNo ratings yet
- Question 1Document3 pagesQuestion 1Mohanapriya KuppanNo ratings yet
- CSE100 Wk11 FilesDocument21 pagesCSE100 Wk11 FilesRazia Sultana Ankhy StudentNo ratings yet
- Basics PDFDocument21 pagesBasics PDFSunil KumarNo ratings yet
- Https Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Natural Language ProcessingDocument5 pagesHttps Raw - Githubusercontent.com Joelgrus Data-Science-From-Scratch Master Code Natural Language ProcessinggprasadatvuNo ratings yet
- Boxplot With Outlier Label RDocument5 pagesBoxplot With Outlier Label RknapikoNo ratings yet
- Intro To R SoftwareDocument7 pagesIntro To R SoftwareNabeela IjazNo ratings yet
- Before You Start LabsDocument19 pagesBefore You Start Labspelleplutt1337No ratings yet
- CS301 Data Structures Final Term of 2012 Solved Subjective With References by MoaazDocument34 pagesCS301 Data Structures Final Term of 2012 Solved Subjective With References by MoaazTayyabah Shah67% (3)
- 10-Visualization of Streaming Data and Class R Code-10!03!2023Document19 pages10-Visualization of Streaming Data and Class R Code-10!03!2023G Krishna VamsiNo ratings yet
- Week 8Document24 pagesWeek 8divya.kapoor04No ratings yet
- R Syntax GuideDocument6 pagesR Syntax GuidePedro CruzNo ratings yet
- NumPy & PandasDocument27 pagesNumPy & PandasPavan DevaNo ratings yet
- R CourseDocument7 pagesR CourseAndreea DobritaNo ratings yet
- CS301 Solved Subjective QuestionsDocument35 pagesCS301 Solved Subjective QuestionsLuqman HussainNo ratings yet
- Introduction and Pythonb BasicsDocument34 pagesIntroduction and Pythonb Basicskarthikeyan RNo ratings yet
- "Cps - TXT" "Education" "South" "SEX" "Experience" "Union" "WAGE" "AGE" "RACE" "Occupat Ion" "Sector" "MARR"Document9 pages"Cps - TXT" "Education" "South" "SEX" "Experience" "Union" "WAGE" "AGE" "RACE" "Occupat Ion" "Sector" "MARR"Alper Tamay ArslanNo ratings yet
- 2010 12 11 Python WorkshopDocument30 pages2010 12 11 Python WorkshopHélène MartinNo ratings yet
- R Lab Programs-1Document26 pagesR Lab Programs-1rns itNo ratings yet
- Twittermining: 1 Twitter Text Mining - Required LibrariesDocument4 pagesTwittermining: 1 Twitter Text Mining - Required LibrariesSamuel PeoplesNo ratings yet
- Advanced R Data Analysis Training PDFDocument72 pagesAdvanced R Data Analysis Training PDFAnonymous NoermyAEpdNo ratings yet
- Important R Codes and NotesDocument13 pagesImportant R Codes and Notes2070834No ratings yet
- Artificial Intelligence LabDocument35 pagesArtificial Intelligence LabMaria NeyveliNo ratings yet
- Summarizing DataDocument13 pagesSummarizing DataNitish RavuvariNo ratings yet
- Package Wordcloud': R Topics DocumentedDocument9 pagesPackage Wordcloud': R Topics Documented0x1aaNo ratings yet
- Aiml Lab Manual 2023Document17 pagesAiml Lab Manual 2023shamilie17No ratings yet
- Short Perl Tutorial: Instructor: Rada Mihalcea University of AntwerpDocument34 pagesShort Perl Tutorial: Instructor: Rada Mihalcea University of AntwerpBhaskar BabuNo ratings yet
- List of CodesDocument30 pagesList of CodesDipak SinghNo ratings yet
- A Short List of Some Useful R Commands: Input and DisplayDocument2 pagesA Short List of Some Useful R Commands: Input and DisplaySakshi RelanNo ratings yet
- PRACTICAL FILE CODE AND OUTPUTDocument22 pagesPRACTICAL FILE CODE AND OUTPUTKumail Ali KhanNo ratings yet
- Lösungen Zu Den Exercises AI PythonDocument26 pagesLösungen Zu Den Exercises AI PythonOzanNo ratings yet
- R FourierDocument18 pagesR FourierNUR ARZILAH ISMAILNo ratings yet
- Short Perl Tutorial: Instructor: Rada Mihalcea University of AntwerpDocument34 pagesShort Perl Tutorial: Instructor: Rada Mihalcea University of AntwerpAshoka VanjareNo ratings yet
- Python Code ExamplesDocument30 pagesPython Code ExamplesAsaf KatzNo ratings yet
- Lesson 6: File ProcessingDocument12 pagesLesson 6: File ProcessingLhay DizonNo ratings yet
- Julia Basic CommandsDocument10 pagesJulia Basic CommandsLazarus PittNo ratings yet
- CodeDocument4 pagesCodesohailaNo ratings yet
- Python Basic and Advanced-Day 8Document20 pagesPython Basic and Advanced-Day 8Ashok Kumar100% (1)
- List Code Project Assessment Using RDocument12 pagesList Code Project Assessment Using RHazel RahmaddioNo ratings yet
- CS229 Python & Numpy: Jingbo Yang, Zhihan XiongDocument40 pagesCS229 Python & Numpy: Jingbo Yang, Zhihan Xiongsid s100% (1)
- Ggplot2 Library BoxplotDocument20 pagesGgplot2 Library BoxplotLuis EmilioNo ratings yet
- Daftar Lampiran: Music Signal AnalysisDocument7 pagesDaftar Lampiran: Music Signal Analysisjeremi kucingNo ratings yet
- Machine Learning Lab Manual: Implement Backpropagation AlgorithmDocument13 pagesMachine Learning Lab Manual: Implement Backpropagation AlgorithmKumaraswamy AnnamNo ratings yet
- Exploratory data analysis and graphics: lab 2Document19 pagesExploratory data analysis and graphics: lab 2juntujuntuNo ratings yet
- Ap PythonDocument12 pagesAp PythonmailadwaitharunNo ratings yet
- R Studio Lab Summary SheetDocument3 pagesR Studio Lab Summary Sheetbanggoodmathan6No ratings yet
- PlottingDocument21 pagesPlottingTonyNo ratings yet
- R CommandsDocument18 pagesR CommandsKhizra AmirNo ratings yet
- Rstudio Study Notes For PA 20181126Document6 pagesRstudio Study Notes For PA 20181126Trong Nghia VuNo ratings yet
- R Introduction IIDocument45 pagesR Introduction IIcristinaNo ratings yet
- BRM FileDocument20 pagesBRM FilegarvbarrejaNo ratings yet
- Learning JavaScript Data Structures and Algorithms - Second EditionFrom EverandLearning JavaScript Data Structures and Algorithms - Second EditionNo ratings yet
- Targeted Page File 1669509935Document19 pagesTargeted Page File 1669509935Abdul SahrilNo ratings yet
- Invoice Victoria BeckDocument1 pageInvoice Victoria BeckRose WidantiNo ratings yet
- Universal PrecauDocument9 pagesUniversal Precauris_hidayatNo ratings yet
- Yes We Fuck English Social Work Journal 208Document13 pagesYes We Fuck English Social Work Journal 208Rose WidantiNo ratings yet
- Quick intro to split-apply-combine with plyrDocument6 pagesQuick intro to split-apply-combine with plyrRose WidantiNo ratings yet
- Asdfg PDFDocument2 pagesAsdfg PDFRose WidantiNo ratings yet
- How Generating Game Economy Content With a Small Team Helped Our BusinessDocument90 pagesHow Generating Game Economy Content With a Small Team Helped Our BusinessMarcos BrzowskiNo ratings yet
- Kaminaka 2014Document9 pagesKaminaka 2014Rose WidantiNo ratings yet
- Universal PrecauDocument9 pagesUniversal Precauris_hidayatNo ratings yet
- Asdfg PDFDocument2 pagesAsdfg PDFRose WidantiNo ratings yet
- Package Plyr': R Topics DocumentedDocument62 pagesPackage Plyr': R Topics DocumentedsaNo ratings yet
- Below the Belt CareDocument7 pagesBelow the Belt CareRose WidantiNo ratings yet
- PXZKF MTYkj8mocg3XExmHzzl PDFDocument1 pagePXZKF MTYkj8mocg3XExmHzzl PDFRose WidantiNo ratings yet
- A Quick Introduction To PlyrDocument9 pagesA Quick Introduction To PlyrKieran DangNo ratings yet
- ASDF: Another System Definition Facility: Manual For Version 3.3.1.2Document96 pagesASDF: Another System Definition Facility: Manual For Version 3.3.1.2Alejandro DominguezNo ratings yet
- Short Long Geriatric Depression Scale GDSDocument2 pagesShort Long Geriatric Depression Scale GDSRose WidantiNo ratings yet
- Geriatric Depression Scale AssessmentDocument2 pagesGeriatric Depression Scale AssessmentaryanggieNo ratings yet
- GDS PDFDocument2 pagesGDS PDFRose WidantiNo ratings yet
- Depression Scale PDFDocument1 pageDepression Scale PDFNadi SyahNo ratings yet
- C.2 Asd 2014 PDFDocument35 pagesC.2 Asd 2014 PDFMuhajir BusraNo ratings yet
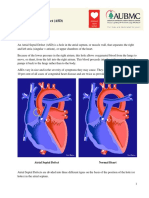
- Atrial Septal DefectDocument7 pagesAtrial Septal DefectRose WidantiNo ratings yet
- DSM 5 (ASD - Guidelines) Feb2013Document7 pagesDSM 5 (ASD - Guidelines) Feb2013Marubare CárdenasNo ratings yet
- Ucm 307647 PDFDocument3 pagesUcm 307647 PDFmsyan1965No ratings yet
- ASD, National Mental HealthDocument8 pagesASD, National Mental HealthIrenaNo ratings yet
- Idiophatic Scoliosis in AdolescentsDocument29 pagesIdiophatic Scoliosis in AdolescentsRose WidantiNo ratings yet
- CS:GO Tournament RegulationsDocument9 pagesCS:GO Tournament RegulationsRose WidantiNo ratings yet
- Dota 2's Character Art Guide Has Been Updated and Converted To A Web Page. Please SeeDocument1 pageDota 2's Character Art Guide Has Been Updated and Converted To A Web Page. Please SeeRose WidantiNo ratings yet
- Atish Agarwala, Michael Pearce, Learning Dota 2 Team CompositionsDocument5 pagesAtish Agarwala, Michael Pearce, Learning Dota 2 Team CompositionsmatamareeeNo ratings yet
- 522 1 926 1 10 20171031Document4 pages522 1 926 1 10 20171031Rose WidantiNo ratings yet
- SVERKER-750-780 DS en V03Document8 pagesSVERKER-750-780 DS en V03Jesse WilliamsNo ratings yet
- Cloud Load Balancing Overview - Google CloudDocument1 pageCloud Load Balancing Overview - Google CloudnnaemekenNo ratings yet
- SuppositoriesDocument66 pagesSuppositoriesSolomonNo ratings yet
- Fyfe Co LLC Design Manual - Rev 7Document70 pagesFyfe Co LLC Design Manual - Rev 7Debendra Dev KhanalNo ratings yet
- Grade8 UseDocument31 pagesGrade8 UseSabino Alfonso RalaNo ratings yet
- Id3 DimensionsDocument2 pagesId3 DimensionsKornelija PadleckyteNo ratings yet
- BRC Hand Book PDFDocument36 pagesBRC Hand Book PDFYang W OngNo ratings yet
- Quick-Connect Moment Connection For Portal Frame Buildings - An Introduction and Case StudiesDocument10 pagesQuick-Connect Moment Connection For Portal Frame Buildings - An Introduction and Case StudiesTuroyNo ratings yet
- Data-Mining-Lab-Manual Cs 703bDocument41 pagesData-Mining-Lab-Manual Cs 703bAmit Kumar SahuNo ratings yet
- Macro Processors: Basic Function Machine-Independent Features Design Options Implementation ExamplesDocument18 pagesMacro Processors: Basic Function Machine-Independent Features Design Options Implementation ExamplesCharan SainiNo ratings yet
- Owner's Manual For Porsgrunn Rotary Vane Steering Gear S-1995Document124 pagesOwner's Manual For Porsgrunn Rotary Vane Steering Gear S-1995O olezhaod100% (4)
- KSH - Korn Shell TutorialDocument5 pagesKSH - Korn Shell Tutorialramaniqbal123No ratings yet
- 25 L SUPER Reflux Still Ins With Z FilterDocument16 pages25 L SUPER Reflux Still Ins With Z FiltertoffeloffeNo ratings yet
- GIS Approach To Fire Station Location PDFDocument6 pagesGIS Approach To Fire Station Location PDFafiNo ratings yet
- SHK Error CodesDocument7 pagesSHK Error CodesmmlipuNo ratings yet
- Tutorial 3 AnswersDocument2 pagesTutorial 3 AnswersM Arif SiddiquiNo ratings yet
- Electron Configurations and PropertiesDocument28 pagesElectron Configurations and PropertiesAinthu IbrahymNo ratings yet
- Assessment of Water Resources Pollution Associated With Mining ActivityDocument13 pagesAssessment of Water Resources Pollution Associated With Mining ActivityVictor Gallo RamosNo ratings yet
- Building Technology 4 Week 4Document42 pagesBuilding Technology 4 Week 4Xette FajardoNo ratings yet
- How To Operate BlenderDocument1 pageHow To Operate BlenderMang Aip RezpectorSejatiNo ratings yet
- IOER Descriptive and Inferential Gonzales NepthalieDocument39 pagesIOER Descriptive and Inferential Gonzales NepthalieMITZHE GAE MAMINONo ratings yet
- Kinetics P.1 and P.2 SL IB Questions PracticeDocument22 pagesKinetics P.1 and P.2 SL IB Questions Practice2018dgscmtNo ratings yet
- 180.5Mbps-8Gbps DLL-based Clock and Data Recovery Circuit With Low Jitter PerformanceDocument4 pages180.5Mbps-8Gbps DLL-based Clock and Data Recovery Circuit With Low Jitter PerformanceMinh KhangNo ratings yet
- Newtonian Mechanics (Physics Chap 2)Document46 pagesNewtonian Mechanics (Physics Chap 2)anon_815277876No ratings yet
- Introduction To InsulationDocument43 pagesIntroduction To InsulationHaridev Moorthy100% (2)
- Presentation NishantDocument42 pagesPresentation NishantNishant PandaNo ratings yet
- HFRPADocument227 pagesHFRPAMitzu Mariuss100% (2)
- 03-Power Apps Model-Driven App Lab ManualDocument32 pages03-Power Apps Model-Driven App Lab Manualsequeesp medalviruNo ratings yet
- Sweater Consumption CostingDocument2 pagesSweater Consumption Costingapi-214283679No ratings yet
- Theoretical Basis For Propulsive Force GenerationDocument10 pagesTheoretical Basis For Propulsive Force GenerationSolGriffinNo ratings yet