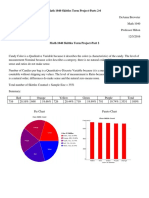
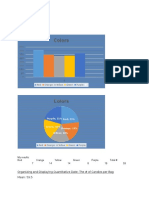
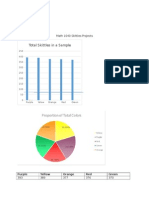
You might also like
- Stats Semester ProjectDocument11 pagesStats Semester Projectapi-276989071No ratings yet
- Skittles Term Project 1-6Document10 pagesSkittles Term Project 1-6api-284733808No ratings yet
- Skittles Project 2-6Document8 pagesSkittles Project 2-6api-302525501No ratings yet
- Skittles Term ProjectDocument10 pagesSkittles Term Projectapi-273060240No ratings yet
- Reflection and EportfolioDocument8 pagesReflection and Eportfolioapi-252747849No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-252747849No ratings yet
- Statistics Project 17Document13 pagesStatistics Project 17api-271978152No ratings yet
- Term Project Part 8Document9 pagesTerm Project Part 8api-242224172No ratings yet
- Kassem Hajj: Math 1040 Skittles Term ProjectDocument10 pagesKassem Hajj: Math 1040 Skittles Term Projectapi-240347922No ratings yet
- Math 1040 Final ProjectDocument11 pagesMath 1040 Final Projectapi-300784866No ratings yet
- Skittles Project Final Cut Leon LindDocument13 pagesSkittles Project Final Cut Leon Lindapi-283465839No ratings yet
- SkittleDocument6 pagesSkittleapi-378470372No ratings yet
- Skittles Eportfolio TestDocument14 pagesSkittles Eportfolio Testapi-385819431100% (1)
- Skittles Project Math 1040Document8 pagesSkittles Project Math 1040api-495044194No ratings yet
- Skittles ProjectDocument4 pagesSkittles Projectapi-287735026No ratings yet
- Skittles FinalDocument7 pagesSkittles Finalapi-582864642No ratings yet
- Emily Gregorio Skittles Project FinalDocument3 pagesEmily Gregorio Skittles Project Finalapi-288933258No ratings yet
- Skittles Proyect Part 5Document7 pagesSkittles Proyect Part 5api-509398997No ratings yet
- Pie Chart For The ProjectDocument7 pagesPie Chart For The Projectapi-325968264No ratings yet
- Math 1040 - Part IV Skittles ProjectDocument7 pagesMath 1040 - Part IV Skittles Projectapi-441885867No ratings yet
- Skittles Part 4Document3 pagesSkittles Part 4api-405527325No ratings yet
- Skittles Term Project - Kai Galbiso Stat1040Document6 pagesSkittles Term Project - Kai Galbiso Stat1040api-316758771No ratings yet
- Math 1040Document5 pagesMath 1040api-534403229No ratings yet
- Math 1030 Skittles Term ProjectDocument8 pagesMath 1030 Skittles Term Projectapi-340538273No ratings yet
- SkittlesDocument7 pagesSkittlesapi-244615173No ratings yet
- The Skittles ProjectDocument5 pagesThe Skittles Projectapi-495363385No ratings yet
- Skittles Project 2Document10 pagesSkittles Project 2api-316655135No ratings yet
- Skittles ProjectDocument5 pagesSkittles Projectapi-441660843No ratings yet
- Skittles ReportDocument15 pagesSkittles Reportapi-271901299No ratings yet
- Statistics Final Project Summer Semester 2016Document17 pagesStatistics Final Project Summer Semester 2016api-295161880No ratings yet
- Math 1040 Skittles Term Project EportfolioDocument7 pagesMath 1040 Skittles Term Project Eportfolioapi-260817278No ratings yet
- Kiera Tech Experience 2Document5 pagesKiera Tech Experience 2api-275431904No ratings yet
- Skittles Part 4Document2 pagesSkittles Part 4api-282338314No ratings yet
- Final ProjectDocument9 pagesFinal Projectapi-262329757No ratings yet
- Math 1040 Skittles Report Part 2Document8 pagesMath 1040 Skittles Report Part 2api-298082521No ratings yet
- Final Math ProjectDocument7 pagesFinal Math Projectapi-316775963No ratings yet
- Skittles ReportDocument5 pagesSkittles Reportapi-242736484No ratings yet
- Full Skittles ProjectDocument13 pagesFull Skittles Projectapi-537189505No ratings yet
- Corn Genetics - Kelompok 4Document7 pagesCorn Genetics - Kelompok 4Delia NurusyifaNo ratings yet
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081No ratings yet
- Skittles Statistics ProjectDocument9 pagesSkittles Statistics Projectapi-325825295No ratings yet
- Skittles ProjectDocument13 pagesSkittles Projectapi-306339227No ratings yet
- Assignment 4: Total Marks: / 92Document12 pagesAssignment 4: Total Marks: / 92H GlamNo ratings yet
- Eportfolio Skittle ProjectDocument9 pagesEportfolio Skittle Projectapi-581790180No ratings yet
- Math 1040 Skittles Term ProjectDocument10 pagesMath 1040 Skittles Term Projectapi-310671451No ratings yet
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085No ratings yet
- Skittles Project FinalDocument8 pagesSkittles Project Finalapi-548638974No ratings yet
- Skittles Project Math 1030Document9 pagesSkittles Project Math 1030api-305867098No ratings yet
- Math 1040 Statistics Term Project: Blake FreemanDocument10 pagesMath 1040 Statistics Term Project: Blake Freemanapi-252919218No ratings yet
- CH 9 NotesDocument67 pagesCH 9 NotesSofie JacksonNo ratings yet
- Skittles Project Part 1Document6 pagesSkittles Project Part 1api-457501806No ratings yet
- CH4304EXPTSDocument30 pagesCH4304EXPTSAhren PageNo ratings yet
- StatisticsDocument27 pagesStatisticsJudy Mae Arenilla SudayNo ratings yet
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765No ratings yet
- Statistics ExamDocument9 pagesStatistics ExamHasen BebbaNo ratings yet
- AssignmentDocument12 pagesAssignmentVishal SinghNo ratings yet
- Stat homework problem analysisDocument5 pagesStat homework problem analysismojarramanNo ratings yet
- Lecture 2Document26 pagesLecture 2Moamen MohamedNo ratings yet
- GCSE Maths Revision: Cheeky Revision ShortcutsFrom EverandGCSE Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (2)
- Venture Mathematics Worksheets: Bk. A: Algebra and Arithmetic: Blackline masters for higher ability classes aged 11-16From EverandVenture Mathematics Worksheets: Bk. A: Algebra and Arithmetic: Blackline masters for higher ability classes aged 11-16No ratings yet
- Prospectus Project Final PaperDocument3 pagesProspectus Project Final Paperapi-339884559No ratings yet
- Final Draft Signature Assign HistoryDocument3 pagesFinal Draft Signature Assign Historyapi-339884559No ratings yet
- Civic Engagement Project HumaDocument1 pageCivic Engagement Project Humaapi-339884559No ratings yet
- Eating Journal YogaDocument4 pagesEating Journal Yogaapi-339884559No ratings yet
- Persuasion Effect Project Opinion EditorialDocument5 pagesPersuasion Effect Project Opinion Editorialapi-339884559No ratings yet
- Jurnal RIKIDocument14 pagesJurnal RIKIerikaNo ratings yet
- 18bme0829 Statslab1Document5 pages18bme0829 Statslab1Tanmay DagaNo ratings yet
- Application of Normal DistributionDocument13 pagesApplication of Normal DistributionCeejay FrillarteNo ratings yet
- Module 1 – Statistical Process ControlDocument37 pagesModule 1 – Statistical Process ControlMiel Ross JaderNo ratings yet
- Statistical Foundation of Econometric AnalysisDocument413 pagesStatistical Foundation of Econometric Analysiszafir_123No ratings yet
- QM-Course Handout - MM ZG515Document10 pagesQM-Course Handout - MM ZG515ArunNo ratings yet
- Multivariate AnaDocument20 pagesMultivariate AnaNIKNISHNo ratings yet
- Two Way AnnovaDocument18 pagesTwo Way Annovaomee purohitNo ratings yet
- Essential Statistics For The Behavioral Sciences 2nd Edition Privitera Test BankDocument18 pagesEssential Statistics For The Behavioral Sciences 2nd Edition Privitera Test Bankthenarkaraismfq9cn100% (29)
- Tabla D3 Duncan Statistics ControlDocument3 pagesTabla D3 Duncan Statistics ControlOscar SotomayorNo ratings yet
- Statistics Chapter 8 Project - Andrew Olivia 1Document2 pagesStatistics Chapter 8 Project - Andrew Olivia 1api-590585243No ratings yet
- A Caution Regarding Rules of Thumb For Variance Inflation FactorsDocument18 pagesA Caution Regarding Rules of Thumb For Variance Inflation FactorsParag Jyoti DuttaNo ratings yet
- CIA-RDP96-00789R003100030001-4 (CIA Stargate Document)Document439 pagesCIA-RDP96-00789R003100030001-4 (CIA Stargate Document)Red OzNo ratings yet
- Ma5160 Applied Probability and Statistics 1 PDFDocument4 pagesMa5160 Applied Probability and Statistics 1 PDFPrabhakar Prabhaa50% (2)
- Beyond Binary ClassificationDocument34 pagesBeyond Binary Classificationlalitha lalliNo ratings yet
- Diebold (2017) - Forecasting in Economics, Business, Finance and BeyondDocument619 pagesDiebold (2017) - Forecasting in Economics, Business, Finance and BeyondSuzume YosanoNo ratings yet
- Statistics For Business (Syllabus)Document10 pagesStatistics For Business (Syllabus)Trung LêNo ratings yet
- Asymptotic Regression Analysis in StatisticsDocument22 pagesAsymptotic Regression Analysis in StatisticsAspirin A. BayerNo ratings yet
- Journal of Economics and Management: Saghir Ahmed Abdullahi M. AbdullahiDocument15 pagesJournal of Economics and Management: Saghir Ahmed Abdullahi M. AbdullahiHafiz M Z KhAnNo ratings yet
- Tests of Significance LessonsDocument24 pagesTests of Significance LessonsSumit SharmaNo ratings yet
- How To Test Hypothesis by T Model PDFDocument5 pagesHow To Test Hypothesis by T Model PDFRiz FahanNo ratings yet
- Lesson 4.4 Probability and Normal DistributionDocument13 pagesLesson 4.4 Probability and Normal DistributionJayson Delos SantosNo ratings yet
- Comm 215.MidtermReviewDocument71 pagesComm 215.MidtermReviewJose Carlos BulaNo ratings yet
- Machine Learning Interview QuestionsDocument4 pagesMachine Learning Interview QuestionsAmandeep100% (1)
- Linear Regression Program So FarDocument33 pagesLinear Regression Program So FarhomeshNo ratings yet
- Data Driven Modelling Using MATLABDocument21 pagesData Driven Modelling Using MATLABhquynhNo ratings yet
- Classical And. Modern Regression With Applications: DuxburyDocument7 pagesClassical And. Modern Regression With Applications: DuxburyrahsarahNo ratings yet
- From Predictive To PrescriptiveDocument57 pagesFrom Predictive To Prescriptiveluis wilbertNo ratings yet
- Generalized Linear ModelsDocument12 pagesGeneralized Linear ModelsAndika AfriansyahNo ratings yet
- Cauchy Distribution (FromDocument2 pagesCauchy Distribution (FromRavi KumarNo ratings yet