You might also like
- Signal Processing in Auditory Neuroscience: Temporal and Spatial Features of Sound and SpeechFrom EverandSignal Processing in Auditory Neuroscience: Temporal and Spatial Features of Sound and SpeechNo ratings yet
- Tracto VocalDocument18 pagesTracto VocalLuis Carlos EspeletaNo ratings yet
- Acoustic Signals and Hearing: A Time-Envelope and Phase Spectral ApproachFrom EverandAcoustic Signals and Hearing: A Time-Envelope and Phase Spectral ApproachNo ratings yet
- 1.2 Bases Acústicas VozDocument21 pages1.2 Bases Acústicas VozFernanda MerichesNo ratings yet
- Carpentier 2016 OLOFONIA EN Holophonic Sound in Ircam's Concert HallDocument21 pagesCarpentier 2016 OLOFONIA EN Holophonic Sound in Ircam's Concert HallsammarcoNo ratings yet
- Acoustic characteristics of the piriform fossa in models and humansDocument11 pagesAcoustic characteristics of the piriform fossa in models and humansarts.lamiaaaldawyNo ratings yet
- Free-Field Equivalent Localization of Virtual AudioDocument9 pagesFree-Field Equivalent Localization of Virtual AudiojulianpalacinoNo ratings yet
- Validez Ecológica de La Reproducción de Paisajes Sonoros UHJ EstéreoDocument8 pagesValidez Ecológica de La Reproducción de Paisajes Sonoros UHJ EstéreoDennis Queca CadizNo ratings yet
- Acoustics 05 00033 v2Document10 pagesAcoustics 05 00033 v2User KadoshNo ratings yet
- Investigation of The Effect of Obstacle Placed Near The Human Glottis On The Resultant Sound PressureDocument8 pagesInvestigation of The Effect of Obstacle Placed Near The Human Glottis On The Resultant Sound PressureDarrenNo ratings yet
- Sound Generation by Steady Flow Through Glottis-Shaped OrificesDocument9 pagesSound Generation by Steady Flow Through Glottis-Shaped OrificesRoman KrautschneiderNo ratings yet
- Modeling The Voice Source in Terms of Spectral Slopesa) : Marc Garellekrobin Samlanbruce R. Gerratt Jody KreimanmahDocument8 pagesModeling The Voice Source in Terms of Spectral Slopesa) : Marc Garellekrobin Samlanbruce R. Gerratt Jody KreimanmahChristian Castro ToroNo ratings yet
- New Approaches For Analysis of Jet Noise Data: of of of of of of ofDocument21 pagesNew Approaches For Analysis of Jet Noise Data: of of of of of of ofL VenkatakrishnanNo ratings yet
- Extracting Audio Descriptors from Musical SignalsDocument15 pagesExtracting Audio Descriptors from Musical SignalsAlisa KobzarNo ratings yet
- Sound Playback Studies: AND MortonDocument2 pagesSound Playback Studies: AND MortonpaperocamilloNo ratings yet
- Speech Localisation in A Multitalker Mixture by Humans and MachinesDocument5 pagesSpeech Localisation in A Multitalker Mixture by Humans and MachinesAiping ZhangNo ratings yet
- Luc Koe JASA2005 BDocument11 pagesLuc Koe JASA2005 BPauloGonçalvesNo ratings yet
- Analýza Barev Orchestrálních NástrojůDocument30 pagesAnalýza Barev Orchestrálních NástrojůOndřej VaníčekNo ratings yet
- Acoustic Properties of The Voice Source and The Vocal Tract - 2016 - Journal ofDocument14 pagesAcoustic Properties of The Voice Source and The Vocal Tract - 2016 - Journal ofelinlau0No ratings yet
- Speech Sound Production: Recognition Using Recurrent Neural NetworksDocument20 pagesSpeech Sound Production: Recognition Using Recurrent Neural NetworkstatiturihariNo ratings yet
- Lower Mandible Maneuver and Elite SingersDocument20 pagesLower Mandible Maneuver and Elite SingersBryan ChenNo ratings yet
- HillHawksford AES135Document8 pagesHillHawksford AES135ALBNo ratings yet
- Modeling the Voice Source in Terms of Spectral SlopesDocument7 pagesModeling the Voice Source in Terms of Spectral Slopesarts.lamiaaaldawyNo ratings yet
- Exploring Phase Information in Sound Source SeparaDocument9 pagesExploring Phase Information in Sound Source SeparaPaulo FeijãoNo ratings yet
- RoundRobin AuralisationDocument16 pagesRoundRobin AuralisationDaniel CastroNo ratings yet
- Everyday Sounds: Synthesis Parameters and Perceptual CorrelatesDocument12 pagesEveryday Sounds: Synthesis Parameters and Perceptual CorrelatesLaclassedifabio FabioNo ratings yet
- 1995 M Ller Et Al AES Journal CDocument23 pages1995 M Ller Et Al AES Journal Cvegapis383No ratings yet
- Voice Production Death Metal SingersDocument4 pagesVoice Production Death Metal SingersJonathan Neyra NievesNo ratings yet
- Recording Microwave Hearing EffectsDocument8 pagesRecording Microwave Hearing EffectsJenniferNo ratings yet
- 21 Howard1997Document13 pages21 Howard1997jesús buendia puyo100% (1)
- Joint Sampling Theory and Subjective Investigation of Plane-Wave and Spherical Harmonics Formulations For Binaural ReproductionDocument7 pagesJoint Sampling Theory and Subjective Investigation of Plane-Wave and Spherical Harmonics Formulations For Binaural ReproductionZamir Ben-HurNo ratings yet
- Hani ThesisDocument160 pagesHani ThesisHani C YehiaNo ratings yet
- D Sound Spatialization Using Ambisonic T PDFDocument14 pagesD Sound Spatialization Using Ambisonic T PDFMariana Sepúlveda MoralesNo ratings yet
- Quantification of Flow Noise Produced by An Oscillating HydrofoilDocument14 pagesQuantification of Flow Noise Produced by An Oscillating Hydrofoilboone keefeNo ratings yet
- Three-Dimensional Vocal Tract Imaging and Formant Structure: Varying Vocal Register, Pitch, and LoudnessDocument6 pagesThree-Dimensional Vocal Tract Imaging and Formant Structure: Varying Vocal Register, Pitch, and LoudnessVusala HasanovaNo ratings yet
- Binaural Renderers Accuracy ComparisonDocument6 pagesBinaural Renderers Accuracy ComparisonCaio Cesar LouresNo ratings yet
- Acoustic and Auditory Phonetics The Adaptive DesigDocument15 pagesAcoustic and Auditory Phonetics The Adaptive DesigSparrow WingsNo ratings yet
- Nihms 425163Document22 pagesNihms 425163ning.anNo ratings yet
- Ieeespl09 KKP WarpingDocument4 pagesIeeespl09 KKP WarpingKamil WojcickiNo ratings yet
- Overlapped Music Segmentation Using A New Effective Feature and Random ForestsDocument9 pagesOverlapped Music Segmentation Using A New Effective Feature and Random ForestsIAES IJAINo ratings yet
- 1984 Ruggero Et Al. Hear ResDocument5 pages1984 Ruggero Et Al. Hear ResDanielaNo ratings yet
- Energy Distribution in Formant Bands For Arabic VowelsDocument5 pagesEnergy Distribution in Formant Bands For Arabic VowelsKhalid EdianiNo ratings yet
- Tools - For - Studying - Spectral - Temporal - Effects - of - Noise - 2010 INTERNOISE - 511Document10 pagesTools - For - Studying - Spectral - Temporal - Effects - of - Noise - 2010 INTERNOISE - 511Rami MalekNo ratings yet
- Speech 1Document6 pagesSpeech 1Sobir AliNo ratings yet
- Comparing Stereo Arrays GuideDocument11 pagesComparing Stereo Arrays Guidetitov33No ratings yet
- Simulating Autophony With Auralized Oral-Binaural Room Impulse ResponsesDocument9 pagesSimulating Autophony With Auralized Oral-Binaural Room Impulse ResponsesDaniel CastroNo ratings yet
- Synthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezDocument5 pagesSynthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezZellagui EnergyNo ratings yet
- 2010 Ryabov - Role of The Mental Foramens in Dolphin HearingDocument8 pages2010 Ryabov - Role of The Mental Foramens in Dolphin HearingbvromanovNo ratings yet
- A Low-Cost High-Quality MEMS Ambisonic-MicrophoneDocument9 pagesA Low-Cost High-Quality MEMS Ambisonic-MicrophoneScribber BibberNo ratings yet
- Original PDF Signal Processing in Auditory Neuroscience Temporal and Spatial PDFDocument48 pagesOriginal PDF Signal Processing in Auditory Neuroscience Temporal and Spatial PDFvelma.tarrant212100% (36)
- Vocal-Tract Length Estimation - Victor - Sorokin - 2013Document10 pagesVocal-Tract Length Estimation - Victor - Sorokin - 2013luisNo ratings yet
- Speech Signal ProcessingDocument173 pagesSpeech Signal ProcessingLizy Abraham100% (2)
- Isra PDFDocument1 pageIsra PDFhorcajada-1No ratings yet
- Directional Landscapes Using Parametric Loudspeakers For Sound Reproduction in ArtDocument12 pagesDirectional Landscapes Using Parametric Loudspeakers For Sound Reproduction in ArtMarco AlunnoNo ratings yet
- Lecture 1-7: Source-Filter ModelDocument6 pagesLecture 1-7: Source-Filter ModelhadaspeeryNo ratings yet
- Exploring The Acoustic Physics of Speech Sounds in PhoneticsDocument6 pagesExploring The Acoustic Physics of Speech Sounds in PhoneticsResearch ParkNo ratings yet
- Infinite-Impulse-Response Models of The Head-Related Transfer FunctionDocument16 pagesInfinite-Impulse-Response Models of The Head-Related Transfer FunctionAbanti MoralesNo ratings yet
- History of Acoustic BeamformingDocument17 pagesHistory of Acoustic BeamformingPabloPelaezNo ratings yet
- Numerical_Methodology_to_Obtain_theDocument8 pagesNumerical_Methodology_to_Obtain_thescarpredator5No ratings yet
- A Practical Guide to Patterns: Fundamental concepts and common patternsDocument72 pagesA Practical Guide to Patterns: Fundamental concepts and common patternsOliver MaklottNo ratings yet
- Grammareval1 PDFDocument1 pageGrammareval1 PDFdacorcNo ratings yet
- The Preservation, Emulation, Migration, and Virtualization of Live Electronics For Performing Arts - An Overview of Musical and Technical IssuesDocument16 pagesThe Preservation, Emulation, Migration, and Virtualization of Live Electronics For Performing Arts - An Overview of Musical and Technical IssuesGerardo Meza GómezNo ratings yet
- Sunrom 753444Document1 pageSunrom 753444Gerardo Meza GómezNo ratings yet
- The Alien VoiceDocument10 pagesThe Alien VoiceGerardo Meza GómezNo ratings yet
- Ex 2005-023 PDFDocument80 pagesEx 2005-023 PDFGerardo Meza GómezNo ratings yet
- Boulez EssayDocument10 pagesBoulez Essaylocrian54No ratings yet
- EMS06 LThoresenDocument21 pagesEMS06 LThoresenmarcos_casasNo ratings yet
- Live Coding and Machine Listening: Nick Collins Durham University, Department of MusicDocument8 pagesLive Coding and Machine Listening: Nick Collins Durham University, Department of MusicGerardo Meza GómezNo ratings yet
- Noise Source Models For Fricative Consonants: Shrikanth Narayanan, Member, IEEE, and Abeer Alwan, Member, IEEEDocument17 pagesNoise Source Models For Fricative Consonants: Shrikanth Narayanan, Member, IEEE, and Abeer Alwan, Member, IEEEGerardo Meza GómezNo ratings yet
- The Alien Voice PDFDocument10 pagesThe Alien Voice PDFGerardo Meza GómezNo ratings yet
- Atmosphere As The Fundamental Concept of A New AestheticsDocument15 pagesAtmosphere As The Fundamental Concept of A New Aestheticsjasonbrogan100% (1)
- S E A T - S: Ample Fficient Daptive EXT TO PeechDocument15 pagesS E A T - S: Ample Fficient Daptive EXT TO PeechGerardo Meza GómezNo ratings yet
- The Alien Voice PDFDocument10 pagesThe Alien Voice PDFGerardo Meza GómezNo ratings yet
- Noise Source Models For Fricative ConsonantsDocument18 pagesNoise Source Models For Fricative ConsonantsGerardo Meza GómezNo ratings yet
- Live Coding and Machine Listening: Nick Collins Durham University, Department of MusicDocument8 pagesLive Coding and Machine Listening: Nick Collins Durham University, Department of MusicGerardo Meza GómezNo ratings yet
- Noise Source Models For Fricative Consonants: Shrikanth Narayanan, Member, IEEE, and Abeer Alwan, Member, IEEEDocument17 pagesNoise Source Models For Fricative Consonants: Shrikanth Narayanan, Member, IEEE, and Abeer Alwan, Member, IEEEGerardo Meza GómezNo ratings yet
- Artigo CAC Magazine PDFDocument10 pagesArtigo CAC Magazine PDFJamesNo ratings yet
- Divisions of The Tetra ChordDocument206 pagesDivisions of The Tetra Chordrobertthomasmartin100% (5)
- S E A T - S: Ample Fficient Daptive EXT TO PeechDocument15 pagesS E A T - S: Ample Fficient Daptive EXT TO PeechGerardo Meza GómezNo ratings yet
- A Gentle Introduction To SuperColliderDocument122 pagesA Gentle Introduction To SuperColliderLibre RoarNo ratings yet
- Modernism UnboundDocument18 pagesModernism UnboundGerardo Meza GómezNo ratings yet
- Divisions of The Tetrachord by John H. ChalmersDocument373 pagesDivisions of The Tetrachord by John H. ChalmersGerardo Meza GómezNo ratings yet
- Brian K. Shepard Refining Sound A Practical Guide To Synthesis and SynthesizersDocument264 pagesBrian K. Shepard Refining Sound A Practical Guide To Synthesis and SynthesizersClear Sky100% (5)
- Divisions of The Tetra ChordDocument206 pagesDivisions of The Tetra Chordrobertthomasmartin100% (5)
- Swim PDFDocument52 pagesSwim PDFGerardo Meza GómezNo ratings yet
- Evaluation of Sensors as Input Devices for Computer Music InterfacesDocument10 pagesEvaluation of Sensors as Input Devices for Computer Music InterfacesGerardo Meza GómezNo ratings yet
- Compositional Strategies in Music For Solo Instruments and Electroacoustic Sounds - Vol1Document165 pagesCompositional Strategies in Music For Solo Instruments and Electroacoustic Sounds - Vol1Gerardo Meza GómezNo ratings yet
- Bruckner’s Symphonies and Sonata Deformation TheoryDocument13 pagesBruckner’s Symphonies and Sonata Deformation TheoryGerardo Meza Gómez100% (1)
- ch5 PDFDocument25 pagesch5 PDFNâséébûllāh BugtiNo ratings yet
- Gender Recognition System Using Speech SignalDocument9 pagesGender Recognition System Using Speech SignalijcseitNo ratings yet
- Total Line Shape Analysis of High-Resolution NMR Spectra: Dmitry A. Cheshkov, Dmitry O. SinitsynDocument36 pagesTotal Line Shape Analysis of High-Resolution NMR Spectra: Dmitry A. Cheshkov, Dmitry O. SinitsynWargner Moreno L.No ratings yet
- BCAAs Improve Brain Dysfunction in Cirrhotic PatientsDocument7 pagesBCAAs Improve Brain Dysfunction in Cirrhotic PatientsThinh VinhNo ratings yet
- ProbsisDocument171 pagesProbsismanojmsk100% (2)
- Sentek - How To Select A Vibration Testing System - Kvalitest IndustrialDocument16 pagesSentek - How To Select A Vibration Testing System - Kvalitest IndustrialPekkaNo ratings yet
- Understanding RF Circuits With Multisim 10Document136 pagesUnderstanding RF Circuits With Multisim 10DiegoNo ratings yet
- Chakrabarti - 1987 PDFDocument225 pagesChakrabarti - 1987 PDFclaudiomourapazNo ratings yet
- Tracking Maneuvering Targets Using Dynamic ModelsDocument24 pagesTracking Maneuvering Targets Using Dynamic ModelsciaobubuNo ratings yet
- Principles of Communication Systems: EEE351, Fall 2021Document23 pagesPrinciples of Communication Systems: EEE351, Fall 2021M UMARNo ratings yet
- Bhramari PranayamaDocument6 pagesBhramari PranayamaDASI Susanto100% (1)
- Rew v5.01 Beta22 HelpDocument201 pagesRew v5.01 Beta22 HelpAlecsandruNeacsuNo ratings yet
- Accurate Speech Decomposition Into Periodic and Aperiodic Components Based On Discrete Harmonic TransformDocument5 pagesAccurate Speech Decomposition Into Periodic and Aperiodic Components Based On Discrete Harmonic TransformRuiqi GuoNo ratings yet
- Chapters - 1 & 2: Chapter - 1Document126 pagesChapters - 1 & 2: Chapter - 1F Azam Khan AyonNo ratings yet
- TUTORIAL Computer and Geosciences PotensoftDocument9 pagesTUTORIAL Computer and Geosciences PotensoftdiegaonovaisNo ratings yet
- Guidelines For Global Strength Analysis of Multipurpose VesselsDocument60 pagesGuidelines For Global Strength Analysis of Multipurpose VesselsAnwarul Shafiq AwalludinNo ratings yet
- 3.two Marks QuestionsDocument20 pages3.two Marks QuestionsPullareddy AvulaNo ratings yet
- Analysis of DuobinaryDocument5 pagesAnalysis of DuobinarySarvesh DesaiNo ratings yet
- Amie SylllDocument28 pagesAmie SylllORKUTSHOEBNo ratings yet
- Problem Sheets 1-9Document23 pagesProblem Sheets 1-9malishaheenNo ratings yet
- 13.M.E. Applied ElectronicsDocument63 pages13.M.E. Applied Electronicssushmitha vNo ratings yet
- ISO 4180 INTERNATIONAL STANDARD. Packaging Complete, Filled Transport Packages General Rules For The Compilation of Performance Test SchedulesDocument24 pagesISO 4180 INTERNATIONAL STANDARD. Packaging Complete, Filled Transport Packages General Rules For The Compilation of Performance Test Schedulesירון אהרון שיטריתNo ratings yet
- Sesame HVDocument5 pagesSesame HVMelki Adi KurniawanNo ratings yet
- Shock Response Spectrum Testing For Commercial Products (Tom Irvine) SRS NcodeDocument9 pagesShock Response Spectrum Testing For Commercial Products (Tom Irvine) SRS NcodeGiovanni Morais TeixeiraNo ratings yet
- 8 - Rotordynamics GEDocument55 pages8 - Rotordynamics GETran HienNo ratings yet
- Brain Music System IcmcDocument6 pagesBrain Music System Icmcadrian_attard_trevisanNo ratings yet
- TRIX - Triple Exponential Smoothing Oscillator by Jack K. HutsonDocument4 pagesTRIX - Triple Exponential Smoothing Oscillator by Jack K. HutsonPedro MelloNo ratings yet
- Statistics Professor Email Frequency AnalysisDocument3 pagesStatistics Professor Email Frequency Analysisamin badrulNo ratings yet
- Modern Methods For Random Fatigue of AutomotiveDocument13 pagesModern Methods For Random Fatigue of AutomotiveindaduqueNo ratings yet
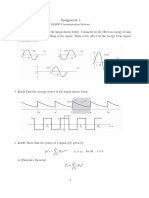
- Assignment 1Document6 pagesAssignment 1yamen.nasser7No ratings yet
- Quantum Spirituality: Science, Gnostic Mysticism, and Connecting with Source ConsciousnessFrom EverandQuantum Spirituality: Science, Gnostic Mysticism, and Connecting with Source ConsciousnessRating: 4 out of 5 stars4/5 (6)
- Dark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseFrom EverandDark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseRating: 3.5 out of 5 stars3.5/5 (69)
- The Physics of God: How the Deepest Theories of Science Explain Religion and How the Deepest Truths of Religion Explain ScienceFrom EverandThe Physics of God: How the Deepest Theories of Science Explain Religion and How the Deepest Truths of Religion Explain ScienceRating: 4.5 out of 5 stars4.5/5 (23)
- Packing for Mars: The Curious Science of Life in the VoidFrom EverandPacking for Mars: The Curious Science of Life in the VoidRating: 4 out of 5 stars4/5 (1395)
- Summary and Interpretation of Reality TransurfingFrom EverandSummary and Interpretation of Reality TransurfingRating: 5 out of 5 stars5/5 (5)
- Quantum Physics for Beginners Who Flunked Math And Science: Quantum Mechanics And Physics Made Easy Guide In Plain Simple EnglishFrom EverandQuantum Physics for Beginners Who Flunked Math And Science: Quantum Mechanics And Physics Made Easy Guide In Plain Simple EnglishRating: 4.5 out of 5 stars4.5/5 (18)
- The Tao of Physics: An Exploration of the Parallels between Modern Physics and Eastern MysticismFrom EverandThe Tao of Physics: An Exploration of the Parallels between Modern Physics and Eastern MysticismRating: 4 out of 5 stars4/5 (500)
- A Brief History of Time: From the Big Bang to Black HolesFrom EverandA Brief History of Time: From the Big Bang to Black HolesRating: 4 out of 5 stars4/5 (2193)
- Lost in Math: How Beauty Leads Physics AstrayFrom EverandLost in Math: How Beauty Leads Physics AstrayRating: 4.5 out of 5 stars4.5/5 (125)
- Midnight in Chernobyl: The Story of the World's Greatest Nuclear DisasterFrom EverandMidnight in Chernobyl: The Story of the World's Greatest Nuclear DisasterRating: 4.5 out of 5 stars4.5/5 (409)
- Strange Angel: The Otherworldly Life of Rocket Scientist John Whiteside ParsonsFrom EverandStrange Angel: The Otherworldly Life of Rocket Scientist John Whiteside ParsonsRating: 4 out of 5 stars4/5 (94)
- Quantum Physics: What Everyone Needs to KnowFrom EverandQuantum Physics: What Everyone Needs to KnowRating: 4.5 out of 5 stars4.5/5 (48)
- Paradox: The Nine Greatest Enigmas in PhysicsFrom EverandParadox: The Nine Greatest Enigmas in PhysicsRating: 4 out of 5 stars4/5 (57)
- Bedeviled: A Shadow History of Demons in ScienceFrom EverandBedeviled: A Shadow History of Demons in ScienceRating: 5 out of 5 stars5/5 (5)
- Too Big for a Single Mind: How the Greatest Generation of Physicists Uncovered the Quantum WorldFrom EverandToo Big for a Single Mind: How the Greatest Generation of Physicists Uncovered the Quantum WorldRating: 4.5 out of 5 stars4.5/5 (8)
- The End of Everything: (Astrophysically Speaking)From EverandThe End of Everything: (Astrophysically Speaking)Rating: 4.5 out of 5 stars4.5/5 (155)
- The Holographic Universe: The Revolutionary Theory of RealityFrom EverandThe Holographic Universe: The Revolutionary Theory of RealityRating: 4.5 out of 5 stars4.5/5 (76)
- The Magick of Physics: Uncovering the Fantastical Phenomena in Everyday LifeFrom EverandThe Magick of Physics: Uncovering the Fantastical Phenomena in Everyday LifeNo ratings yet
- In Search of Schrödinger’s Cat: Quantum Physics and RealityFrom EverandIn Search of Schrödinger’s Cat: Quantum Physics and RealityRating: 4 out of 5 stars4/5 (380)
- Black Holes: The Key to Understanding the UniverseFrom EverandBlack Holes: The Key to Understanding the UniverseRating: 4.5 out of 5 stars4.5/5 (13)
- Starry Messenger: Cosmic Perspectives on CivilizationFrom EverandStarry Messenger: Cosmic Perspectives on CivilizationRating: 4.5 out of 5 stars4.5/5 (158)
- The Sounds of Life: How Digital Technology Is Bringing Us Closer to the Worlds of Animals and PlantsFrom EverandThe Sounds of Life: How Digital Technology Is Bringing Us Closer to the Worlds of Animals and PlantsRating: 5 out of 5 stars5/5 (5)