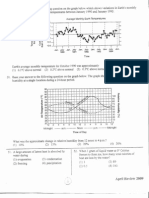
You might also like
- Aromatic Heterocycles Xii Semiempirical Pm3 Study of Diels Alder Cycloaddition Reaction of Substituted PhosphabenzenesDocument18 pagesAromatic Heterocycles Xii Semiempirical Pm3 Study of Diels Alder Cycloaddition Reaction of Substituted PhosphabenzenesJohn RonquilloNo ratings yet
- Macronutrient Intake Induces Oxidative and Inflammatory Stress Potential Relevance To Atherosclerosis and Insulin ResistanceDocument9 pagesMacronutrient Intake Induces Oxidative and Inflammatory Stress Potential Relevance To Atherosclerosis and Insulin ResistanceJohn RonquilloNo ratings yet
- OJT Accomplishment ReportsDocument4 pagesOJT Accomplishment ReportsJohn RonquilloNo ratings yet
- Endometrial Receptivity Profile in Patients With Premature Progesterone Elevation On The Day of HCG AdministrationDocument11 pagesEndometrial Receptivity Profile in Patients With Premature Progesterone Elevation On The Day of HCG AdministrationJohn RonquilloNo ratings yet
- Sleep Disordered Breathing in Patients With Chronic Kidney Diseases How Far The ProblemDocument13 pagesSleep Disordered Breathing in Patients With Chronic Kidney Diseases How Far The ProblemJohn RonquilloNo ratings yet
- Sleep Disruption in Hematopoietic Cell Transplantation Recipients Prevalence Severity and Clinical ManagementDocument20 pagesSleep Disruption in Hematopoietic Cell Transplantation Recipients Prevalence Severity and Clinical ManagementJohn RonquilloNo ratings yet
- OJT Accomplishment ReportsDocument4 pagesOJT Accomplishment ReportsJohn RonquilloNo ratings yet
- New Doc 2019-03-19 13.06.16 - 1Document1 pageNew Doc 2019-03-19 13.06.16 - 1John RonquilloNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Refrence List Middle EastDocument7 pagesRefrence List Middle EastazeemNo ratings yet
- NDP-25 Data SheetDocument4 pagesNDP-25 Data SheetsetyaNo ratings yet
- Scan 1111111111Document1 pageScan 1111111111angela1178No ratings yet
- Cembrit Patina Design Line - LowresDocument11 pagesCembrit Patina Design Line - LowresRaul AntonieNo ratings yet
- Web Service Integration With SAPDocument7 pagesWeb Service Integration With SAPJoy PatelNo ratings yet
- Void Acoustics 2017 BrochureDocument28 pagesVoid Acoustics 2017 BrochureCraig ConnollyNo ratings yet
- Oracle9i Database Installation Guide Release 2 (9.2.0.1.0) For WindowsDocument274 pagesOracle9i Database Installation Guide Release 2 (9.2.0.1.0) For WindowsrameshkadamNo ratings yet
- Uniclass 2015 Ss - Systems Table v1.22: April 2021Document3 pagesUniclass 2015 Ss - Systems Table v1.22: April 2021Nagabhushana HNo ratings yet
- Ronalyn AramboloDocument3 pagesRonalyn AramboloRonalyn AramboloNo ratings yet
- Realizing Higher Productivity by Implementing Air Drilling Tech For Drilling Hard Top Hole Sections in Vindhyan FieldsDocument7 pagesRealizing Higher Productivity by Implementing Air Drilling Tech For Drilling Hard Top Hole Sections in Vindhyan FieldsLok Bahadur RanaNo ratings yet
- American Woodworker 163 2012-2013 PDFDocument76 pagesAmerican Woodworker 163 2012-2013 PDFkaskdos100% (1)
- Building Information Modeling BIM Systems and TheiDocument13 pagesBuilding Information Modeling BIM Systems and Theipurvakul10No ratings yet
- Hyperloop 170201003657Document29 pagesHyperloop 170201003657RafaelLazoPomaNo ratings yet
- CBB Exam Preparation CourseDocument2 pagesCBB Exam Preparation CourseaadmaadmNo ratings yet
- Anti Lock Brake Safety PrecautionsDocument1 pageAnti Lock Brake Safety Precautionssonny1234No ratings yet
- Ecen 607 CMFB-2011Document44 pagesEcen 607 CMFB-2011Girish K NathNo ratings yet
- TQM Model ExamDocument5 pagesTQM Model ExamsaswarajNo ratings yet
- Improvements in Offshore Pipeline Cathodic ProtectionDocument6 pagesImprovements in Offshore Pipeline Cathodic ProtectionEddy Norman Benites DelgadoNo ratings yet
- 10 A103 SiteDocument112 pages10 A103 SiteGovindaraju HSNo ratings yet
- OC Thin Shell Panels SCREENDocument19 pagesOC Thin Shell Panels SCREENKushaal VirdiNo ratings yet
- Omni PageDocument98 pagesOmni Pageterracotta2014No ratings yet
- Requisites of MISDocument2 pagesRequisites of MISPrasanna Sharma67% (3)
- Database Testing: Prepared by Sujaritha MDocument21 pagesDatabase Testing: Prepared by Sujaritha Mavumaa22No ratings yet
- Catalogue MV 07Document54 pagesCatalogue MV 07api-3815405100% (3)
- NEF 50006 BSI WidescreenDocument13 pagesNEF 50006 BSI Widescreenmiguelq_scribdNo ratings yet
- Xpulse200t Manual de PartesDocument92 pagesXpulse200t Manual de PartesAthiq Nehman100% (2)
- Code PICDocument6 pagesCode PICsongbao527No ratings yet
- Aiwa RM-77 Service ManualDocument9 pagesAiwa RM-77 Service Manualcristianhumberto_reyesaguileraNo ratings yet
- Petronas Technical Standards: Symbols and Identification System - MechanicalDocument16 pagesPetronas Technical Standards: Symbols and Identification System - MechanicalUdaya Zorro100% (1)
- Period Based Accounting Versus Cost of Sales AccountingDocument13 pagesPeriod Based Accounting Versus Cost of Sales AccountingAnil Kumar100% (1)