You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Macros For Mine Planning EngineerDocument8 pagesMacros For Mine Planning Engineernanham29_759629210No ratings yet
- Real Time Forth (v5, 199309) - Tim HendtlassDocument265 pagesReal Time Forth (v5, 199309) - Tim HendtlassAnonymous 4oNIJHNo ratings yet
- Cerner QuestionsDocument18 pagesCerner Questionsavid_reader_new50% (2)
- Big Data Analytics Unit 1 MCQDocument10 pagesBig Data Analytics Unit 1 MCQKaruna90% (10)
- MBISTDocument12 pagesMBISTChiranjeevi ChiruNo ratings yet
- USPS - Address-Information-ApiDocument14 pagesUSPS - Address-Information-ApiMillerJamesDNo ratings yet
- Working with SAP Business ObjectsDocument17 pagesWorking with SAP Business Objectskmurth_hnNo ratings yet
- Lab Assignment ProgrammingDocument9 pagesLab Assignment ProgrammingelissaysmnNo ratings yet
- Log4j Tutorial Tutorialpoint PDFDocument39 pagesLog4j Tutorial Tutorialpoint PDFGeorges WakeuNo ratings yet
- Autocad CommandsDocument4 pagesAutocad CommandsAmarnath SahNo ratings yet
- VHDL Codes For Flip FlopsDocument7 pagesVHDL Codes For Flip FlopsAnil KumarNo ratings yet
- 7 Great SQL Interview Questions and Answers - ToptalDocument11 pages7 Great SQL Interview Questions and Answers - Toptallife2005No ratings yet
- Priority search queues: Loser treesDocument37 pagesPriority search queues: Loser treesAnonymous Hurq9VKNo ratings yet
- 003 Operating System VerifiedDocument51 pages003 Operating System VerifiedKurumeti Naga Surya Lakshmana KumarNo ratings yet
- NR-311201-Design and Analysis of AlgorithmsDocument8 pagesNR-311201-Design and Analysis of AlgorithmsSrinivasa Rao GNo ratings yet
- Javabeans and Ejbs: What Is Meant by Enterprise Java Beans (Ejb) ?Document4 pagesJavabeans and Ejbs: What Is Meant by Enterprise Java Beans (Ejb) ?AdarshNo ratings yet
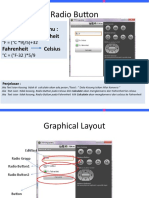
- Radio Button: Latihan Konversi Suhu: Celsius Fahrenheit Fahrenheit CelsiusDocument5 pagesRadio Button: Latihan Konversi Suhu: Celsius Fahrenheit Fahrenheit CelsiusagustavNo ratings yet
- Project Documentation for CODESYS Control ExamDocument9 pagesProject Documentation for CODESYS Control ExamLuis SalasNo ratings yet
- LSMW MM01 Valuation Type ExtensionDocument5 pagesLSMW MM01 Valuation Type ExtensionPrakash GnanamNo ratings yet
- Handson Nodejs SampleDocument63 pagesHandson Nodejs SamplerjegannathanNo ratings yet
- 8086/8088Mp Instructor: Abdulmuttalib A. H. AldouriDocument8 pages8086/8088Mp Instructor: Abdulmuttalib A. H. Aldouriabdulbaset alselwiNo ratings yet
- Assignment of ArrayDocument6 pagesAssignment of ArrayNiti Arora0% (1)
- Nvidia Opencl Best Practices Guide: OptimizationDocument49 pagesNvidia Opencl Best Practices Guide: OptimizationYttria TherbiumNo ratings yet
- Python BasicsDocument22 pagesPython BasicsDua BalochNo ratings yet
- Aivika User GuideDocument106 pagesAivika User GuideBård-Inge PettersenNo ratings yet
- Types of ParserDocument17 pagesTypes of ParserNimi KhanNo ratings yet
- Only PandasDocument8 pagesOnly PandasJyotirmay SahuNo ratings yet
- RSI1Document2 pagesRSI1nikunj olpadwalaNo ratings yet
- Mutual Exclusion in Distributed SystemsDocument157 pagesMutual Exclusion in Distributed Systemsashishkr23438No ratings yet
- Class 16 - Doubly Linked ListDocument15 pagesClass 16 - Doubly Linked ListMaximus AranhaNo ratings yet