You might also like
- Analyze House Price For King CountyDocument15 pagesAnalyze House Price For King CountyyshprasdNo ratings yet
- Capstone Project SubmissionDocument31 pagesCapstone Project Submissionguruss604684No ratings yet
- Capstone-2 Market Basket Analysis Vinothkumar RDocument18 pagesCapstone-2 Market Basket Analysis Vinothkumar RVinothkumar RadhakrishnanNo ratings yet
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHINo ratings yet
- FRA AssignmentDocument31 pagesFRA AssignmentPranav ViswanathanNo ratings yet
- Travel Agency PackageDocument26 pagesTravel Agency PackageKATHIRVEL SNo ratings yet
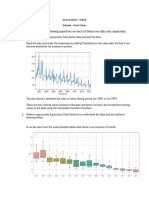
- Problem Statement (Tableau - Graded Project)Document2 pagesProblem Statement (Tableau - Graded Project)Kaustav De0% (1)
- MRA Project - Shehroz KhanDocument19 pagesMRA Project - Shehroz KhanShehroz Khan67% (3)
- Code It QuestionsDocument3 pagesCode It QuestionsNimisha SharmaNo ratings yet
- Marketing & Retail Analytics - Report - Part ADocument18 pagesMarketing & Retail Analytics - Report - Part AAshish Agrawal100% (2)
- TimeSeries ReportDocument41 pagesTimeSeries ReportSukanya ManickavelNo ratings yet
- Mra Project - Milestone1: Student Name: Gowri Srinivasan Batch: Dsba Online Mar 20Document30 pagesMra Project - Milestone1: Student Name: Gowri Srinivasan Batch: Dsba Online Mar 20Sania QamarNo ratings yet
- CafeSales MRA PresentationDocument40 pagesCafeSales MRA PresentationKyotoNo ratings yet
- Big BazaarDocument25 pagesBig BazaarDhruv Singh0% (1)
- Chain AnalysisDocument30 pagesChain Analysissumit kumarNo ratings yet
- Data Science & Business Analytics: Post Graduate Program inDocument16 pagesData Science & Business Analytics: Post Graduate Program inbalaNo ratings yet
- Financial Risk Analytics: ProjectreportDocument94 pagesFinancial Risk Analytics: ProjectreportFiza ssNo ratings yet
- Problem Statement2Document2 pagesProblem Statement2stephennrobertNo ratings yet
- Anamit Deb Gupta Mra - Project Milestone - 1Document30 pagesAnamit Deb Gupta Mra - Project Milestone - 1Gupta Anacoolz100% (1)
- MRA+ CafechainDocument26 pagesMRA+ CafechainPranav ViswanathanNo ratings yet
- Surabhi FRA PartADocument13 pagesSurabhi FRA PartAScribd SCNo ratings yet
- FRA Assignment - India Credit ModelDocument14 pagesFRA Assignment - India Credit ModelpsyishNo ratings yet
- Extended ProjectDocument1 pageExtended Projectcmv_vikkyNo ratings yet
- Factor-Hair RV PDFDocument23 pagesFactor-Hair RV PDFRamachandran VenkataramanNo ratings yet
- Data Mining Business ReportDocument38 pagesData Mining Business ReportThaku SinghNo ratings yet
- Tableau QuestionsDocument2 pagesTableau QuestionsGhulamNo ratings yet
- Sandhya Assignment SQLDocument16 pagesSandhya Assignment SQLsanisani1020No ratings yet
- Answer Book - Rose WinesDocument11 pagesAnswer Book - Rose WinesAshish Agrawal100% (1)
- Capstone Final Report DSA Group 14Document22 pagesCapstone Final Report DSA Group 14house MdNo ratings yet
- Milestone 2 Assignment 2Document6 pagesMilestone 2 Assignment 2vivian_sehoole_99No ratings yet
- MRA Milestone-1 Graded ProjectDocument41 pagesMRA Milestone-1 Graded Projectkirti sharma100% (2)
- Clustering Analysis: Prepared by Muralidharan NDocument16 pagesClustering Analysis: Prepared by Muralidharan Nrakesh sandhyapoguNo ratings yet
- Time Series Rose Shehroz ArfeenDocument42 pagesTime Series Rose Shehroz ArfeenShehroz Khan100% (1)
- FRA ReportDocument30 pagesFRA ReportRaja Sekhar P100% (1)
- Predictive Model: Submitted byDocument27 pagesPredictive Model: Submitted byAnkita Mishra100% (1)
- Machine Learning - Nabeel Khan - Final Project Report - Problem 2Document24 pagesMachine Learning - Nabeel Khan - Final Project Report - Problem 2KhursheedKhan100% (1)
- Project - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)Document15 pagesProject - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)guillermo cocoNo ratings yet
- MRA Project Milestone2 PDFDocument1 pageMRA Project Milestone2 PDFRekha Rajaram100% (1)
- Finance VikasDocument15 pagesFinance VikasVikas Chauhan100% (1)
- MRA Project Milestone 2Document31 pagesMRA Project Milestone 2Puvya Ravi100% (1)
- 1) Introduction A) Defining Problem Statement:-: ST STDocument10 pages1) Introduction A) Defining Problem Statement:-: ST STRaveendra Babu GaddamNo ratings yet
- Cart-Rf-ANN: Prepared by Muralidharan NDocument16 pagesCart-Rf-ANN: Prepared by Muralidharan NKrishnaveni Raj0% (1)
- House Price Prediction 1Document27 pagesHouse Price Prediction 1Lakshman KondreddiNo ratings yet
- Data Mining Assignment: Sudhanva SaralayaDocument16 pagesData Mining Assignment: Sudhanva SaralayaSudhanva S100% (1)
- E-Commerce Revenue Management - Python For Data Science - Great LearningDocument4 pagesE-Commerce Revenue Management - Python For Data Science - Great LearningSuchi S Bahuguna100% (1)
- ML Project Report: (Text Learning Case Study)Document9 pagesML Project Report: (Text Learning Case Study)ankitbhagatNo ratings yet
- Linear Regression Model For Predicting Medical Expenses Based On Insurance DataDocument6 pagesLinear Regression Model For Predicting Medical Expenses Based On Insurance DataAdriana PadureNo ratings yet
- PG Program DsbaDocument16 pagesPG Program DsbatechsivamNo ratings yet
- Neha Arcot Time SeriesDocument34 pagesNeha Arcot Time SeriesNeha Arcot100% (1)
- GDP Forecasting Using Time Series AnalysisDocument15 pagesGDP Forecasting Using Time Series AnalysisAnujNagpalNo ratings yet
- Pratik Zanke Cold StorageDocument6 pagesPratik Zanke Cold Storagepratik zankeNo ratings yet
- Mra Project ML 1: Mitesh Kumar Agrawal Batch: June'21 BatchDocument23 pagesMra Project ML 1: Mitesh Kumar Agrawal Batch: June'21 BatchMITESH AGRAWAL100% (2)
- Shivani Pandey TSFDocument32 pagesShivani Pandey TSFShivich10100% (1)
- Data Mining Project - 27.06.2021Document6 pagesData Mining Project - 27.06.2021vansh guptaNo ratings yet
- Clustering ProjectDocument44 pagesClustering Projectkirti sharma100% (1)
- Time Series Forecasting - Rose - Buisness ReportDocument69 pagesTime Series Forecasting - Rose - Buisness ReportPriyanka Patil100% (1)
- Time Series Forecasting Business Report: Name: S.Krishna Veni Date: 20/02/2022Document31 pagesTime Series Forecasting Business Report: Name: S.Krishna Veni Date: 20/02/2022Krishna Veni100% (1)
- Business: Capstone Project House Price Prediction Project Note-1Document40 pagesBusiness: Capstone Project House Price Prediction Project Note-1Srinidhi A E80% (5)
- PN1 Shakti Akshaya S PDFDocument60 pagesPN1 Shakti Akshaya S PDFRekha Rajaram100% (1)
- Stats Project Module 1 2Document21 pagesStats Project Module 1 2jothamajibadeNo ratings yet
- 7 QC ToolsDocument14 pages7 QC ToolsMangesh NadkarniNo ratings yet
- Alupoaiei Alexie DissertationDocument114 pagesAlupoaiei Alexie DissertationMiruna ZaimNo ratings yet
- Drying Characteristics of Shiitake Mushroom and Jinda Chili During Vacuum Heat Pump DryingDocument10 pagesDrying Characteristics of Shiitake Mushroom and Jinda Chili During Vacuum Heat Pump Dryingnguyen minh tuanNo ratings yet
- SCMH 2.7.2 Variation Sensitivity Analysis Overview Dated 1OCT2020Document41 pagesSCMH 2.7.2 Variation Sensitivity Analysis Overview Dated 1OCT2020Alberto Sánchez RamírezNo ratings yet
- Two Sample T-TestDocument95 pagesTwo Sample T-TestJOMALYN J. NUEVONo ratings yet
- Jarvis - 2005 (1) Species Diversity and StructureDocument438 pagesJarvis - 2005 (1) Species Diversity and StructuresellaginellaNo ratings yet
- Does Firm Investment Respond To Peers' Investment?: M. Cecilia Bustamante and Laurent FR Esard January 22, 2017Document53 pagesDoes Firm Investment Respond To Peers' Investment?: M. Cecilia Bustamante and Laurent FR Esard January 22, 2017Liem NguyenNo ratings yet
- An Investigation of The Efficacy of Various Policies Regarding Employee WelfareDocument19 pagesAn Investigation of The Efficacy of Various Policies Regarding Employee WelfareResearch ParkNo ratings yet
- Impact of Social Media On Brand Loyalty Papr 16Document16 pagesImpact of Social Media On Brand Loyalty Papr 16Ahmed100% (1)
- Complete - Lesson 2 CorrDocument26 pagesComplete - Lesson 2 CorrMARION JUMAO-AS GORDONo ratings yet
- Prerna Bansal Maths in ChemistryDocument196 pagesPrerna Bansal Maths in ChemistryFernando GularteNo ratings yet
- G Power 3.1 Manual: October 15, 2020Document85 pagesG Power 3.1 Manual: October 15, 2020AlbertNo ratings yet
- Correlation and RegressionDocument167 pagesCorrelation and RegressionAtanu MisraNo ratings yet
- Consumer Behavior Purchase Intentions Msia Restaurant and Fastfood PDFDocument6 pagesConsumer Behavior Purchase Intentions Msia Restaurant and Fastfood PDFWilliam HoNo ratings yet
- Quatitative AnalysisDocument24 pagesQuatitative AnalysisGarick BhatnagarNo ratings yet
- Report4 PDFDocument46 pagesReport4 PDFBouchouicha KadaNo ratings yet
- Association Between Variables Measured at The Interval-Ratio Level: Bivariate Correlation and RegressionDocument26 pagesAssociation Between Variables Measured at The Interval-Ratio Level: Bivariate Correlation and RegressionBonie Jay Mateo DacotNo ratings yet
- Pearson Correlation AnalysisDocument26 pagesPearson Correlation Analysissacli100% (1)
- Correlation of StatisticsDocument6 pagesCorrelation of StatisticsHans Christer RiveraNo ratings yet
- The Impact of Customer Relationship Marketing Tactics On Customer LoyaltyDocument43 pagesThe Impact of Customer Relationship Marketing Tactics On Customer LoyaltysteffyalbertsNo ratings yet
- Audio Splicing Detection and Localization Using PDFDocument13 pagesAudio Splicing Detection and Localization Using PDFnomad defNo ratings yet
- Quiz To Chapter 11 (Pass - Quiz11) - Attempt ReviewDocument15 pagesQuiz To Chapter 11 (Pass - Quiz11) - Attempt ReviewHữuNo ratings yet
- Accurate Statistical Analysis of Serdes Mentorpaper - 91688Document23 pagesAccurate Statistical Analysis of Serdes Mentorpaper - 91688FrankNo ratings yet
- Influence of Organic Matter On Soil ColorDocument6 pagesInfluence of Organic Matter On Soil ColorRoderick VillanuevaNo ratings yet
- Encyclopedia of Research Design-Multiple RegressionDocument13 pagesEncyclopedia of Research Design-Multiple RegressionscottleeyNo ratings yet
- Lesson 7 - Linear Correlation and Simple Linear RegressionDocument8 pagesLesson 7 - Linear Correlation and Simple Linear Regressionchloe frostNo ratings yet
- MMW 0001 - Mathematics in The Modern World Syllabus For Online Learning 2Document15 pagesMMW 0001 - Mathematics in The Modern World Syllabus For Online Learning 2Gerardo Abulencia jr.No ratings yet
- Market Research On Edible CutleryDocument20 pagesMarket Research On Edible CutleryVignesh Kg100% (4)
- Youth and Political Participation: What Factors Influence Them?Document28 pagesYouth and Political Participation: What Factors Influence Them?Uugankhuu BatchuluunNo ratings yet
- The - Analysis - On - The - Cause - of - Material - Wa JATEE-Hafnidar - A. - Rani PDFDocument5 pagesThe - Analysis - On - The - Cause - of - Material - Wa JATEE-Hafnidar - A. - Rani PDFmelchior suarliakNo ratings yet