You might also like
- Salesforce Integration QuestionsDocument3 pagesSalesforce Integration QuestionsDebabrat RoutNo ratings yet
- Peoplesoft Inteview QuestionsDocument7 pagesPeoplesoft Inteview QuestionsGanesh.am100% (11)
- Pega Real Time ScenarioDocument13 pagesPega Real Time Scenariochakramscribd100% (6)
- Add Search Features To Your Application - Try ElasticDocument15 pagesAdd Search Features To Your Application - Try ElasticrkpunjalNo ratings yet
- JSP Custom Tag For Pagination, Sorting and Filtering - A Case StudyDocument8 pagesJSP Custom Tag For Pagination, Sorting and Filtering - A Case StudyEditor IJRITCCNo ratings yet
- InterviewDocument79 pagesInterviewSravan KumarNo ratings yet
- Interview QuestionsDocument7 pagesInterview Questionssudershan dolliNo ratings yet
- QTP Interview Questions Part-IV: ActionsDocument4 pagesQTP Interview Questions Part-IV: ActionsKiran KumarNo ratings yet
- Question Explain About V-Model?: 4. Requirrement AnalysisDocument7 pagesQuestion Explain About V-Model?: 4. Requirrement AnalysisRamu PalankiNo ratings yet
- Pega Interview QuestionsDocument376 pagesPega Interview QuestionsadityaNo ratings yet
- MERN (Mongo Express React Node) Interview Questions & AnsDocument17 pagesMERN (Mongo Express React Node) Interview Questions & AnsPranoy ChakrabortyNo ratings yet
- Postgresql InterviewQuestionDocument5 pagesPostgresql InterviewQuestionmontosh100% (1)
- Struts 2.0: by Omprakash Pandey SynergeticsDocument50 pagesStruts 2.0: by Omprakash Pandey SynergeticsNguyễn Tuấn AnhNo ratings yet
- QTP Interview Questions: 1) Which Environments Are Supported by QTP?Document9 pagesQTP Interview Questions: 1) Which Environments Are Supported by QTP?Naresh ReddyNo ratings yet
- Struts 2.0 Framework Overview and Hello World ExampleDocument16 pagesStruts 2.0 Framework Overview and Hello World Exampleamitl21066173No ratings yet
- Ramu New Interview AngularDocument40 pagesRamu New Interview Angularblr 1989No ratings yet
- List of PEGA Interview Questions and AnswersDocument33 pagesList of PEGA Interview Questions and Answersknagender100% (1)
- Cucumber & Jmeter: 1) What Is BDD?Document16 pagesCucumber & Jmeter: 1) What Is BDD?Yash GuptaNo ratings yet
- Advantages of Using .NET Framework 2.0Document9 pagesAdvantages of Using .NET Framework 2.0Jan KacinaNo ratings yet
- ATG Interview QuestionsDocument11 pagesATG Interview QuestionskaarthikhaNo ratings yet
- Interview QuestionsDocument12 pagesInterview QuestionsFenil DesaiNo ratings yet
- QTP QnsDocument6 pagesQTP QnsHarikishan LakkojuNo ratings yet
- Interview Questions AnsDocument55 pagesInterview Questions AnssohagiyaNo ratings yet
- All Interview Questions Cognos IbmDocument13 pagesAll Interview Questions Cognos IbmKishore MaramNo ratings yet
- Automated Testing Interview QuestionsDocument13 pagesAutomated Testing Interview Questionsvineeta1234No ratings yet
- QTP Technical QuestionsDocument14 pagesQTP Technical Questionskarthick_49No ratings yet
- Information Management System Using LINQ OverDocument3 pagesInformation Management System Using LINQ Overeditor_ijarcsseNo ratings yet
- 5-Web ModulesDocument71 pages5-Web ModulesJavierNo ratings yet
- Interview Questions in ASP - NET, C#.NET, SQL Server,.NET Framework - ASP - NET, C#.NET, VB PDFDocument31 pagesInterview Questions in ASP - NET, C#.NET, SQL Server,.NET Framework - ASP - NET, C#.NET, VB PDFGopinathNo ratings yet
- Ijarcce 2022 11113Document9 pagesIjarcce 2022 11113arjunnandunNo ratings yet
- ATG Interview QuestionsDocument12 pagesATG Interview Questionsvyshalli999No ratings yet
- QTP Intervieview QuestionDocument166 pagesQTP Intervieview Questionrenukac300% (1)
- Peoplesoft Interview QuestionsDocument31 pagesPeoplesoft Interview Questionsandysusilook@yahoo.comNo ratings yet
- Complete Reference To ATG2Document8 pagesComplete Reference To ATG2Rudra GNo ratings yet
- An Introduction To Struts 1Document39 pagesAn Introduction To Struts 1SraVanKuMarThadakamallaNo ratings yet
- Node - Js - Express FrameworkDocument36 pagesNode - Js - Express FrameworkB. POORNIMANo ratings yet
- Software Testing 1Document8 pagesSoftware Testing 1junaroopeshNo ratings yet
- AnswerDocument10 pagesAnswerKristie GrayNo ratings yet
- Test Answers (Pega)Document7 pagesTest Answers (Pega)ENG17CS0034 Ankith RaghavNo ratings yet
- Questions & AnswersDocument10 pagesQuestions & AnswersRaghuNo ratings yet
- Internet Information Services (IIS) Is Created by Microsoft To Provide Internet-Based Services ToDocument21 pagesInternet Information Services (IIS) Is Created by Microsoft To Provide Internet-Based Services ToSiva KrishNo ratings yet
- 1.1 Company ProfileDocument55 pages1.1 Company ProfileAshraf AliNo ratings yet
- 2 - UiPath Advance Certification UIARD Certification Latest - UdemyDocument43 pages2 - UiPath Advance Certification UIARD Certification Latest - UdemyHadry GassamaNo ratings yet
- Jmeter Interview Q&ADocument5 pagesJmeter Interview Q&ASaravanan MuruganNo ratings yet
- Struts 2 Interview Questions and AnswersDocument8 pagesStruts 2 Interview Questions and AnswerssoumyaanshNo ratings yet
- Dot Net Interview Questions SummaryDocument32 pagesDot Net Interview Questions SummaryakrbharathrajaNo ratings yet
- SRS - How to build a Pen Test and Hacking PlatformFrom EverandSRS - How to build a Pen Test and Hacking PlatformRating: 2 out of 5 stars2/5 (1)
- Getting Started With Quick Test Professional (QTP) And Descriptive ProgrammingFrom EverandGetting Started With Quick Test Professional (QTP) And Descriptive ProgrammingRating: 4.5 out of 5 stars4.5/5 (2)
- Python Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreFrom EverandPython Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreNo ratings yet
- Java/J2EE Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandJava/J2EE Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Learn NodeJS in 1 Day: Complete Node JS Guide with ExamplesFrom EverandLearn NodeJS in 1 Day: Complete Node JS Guide with ExamplesRating: 3 out of 5 stars3/5 (3)
- Spring Boot Intermediate Microservices: Resilient Microservices with Spring Boot 2 and Spring CloudFrom EverandSpring Boot Intermediate Microservices: Resilient Microservices with Spring Boot 2 and Spring CloudNo ratings yet
- Basics of Python Programming: A Quick Guide for BeginnersFrom EverandBasics of Python Programming: A Quick Guide for BeginnersNo ratings yet
- Data Driven Guide for Python Programming : Master Essentials to Advanced Data StructuresFrom EverandData Driven Guide for Python Programming : Master Essentials to Advanced Data StructuresNo ratings yet
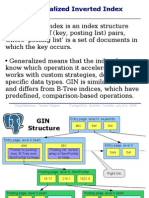
- Generalized Inverted Index An Inverted Index Is An IndexDocument14 pagesGeneralized Inverted Index An Inverted Index Is An IndexNikolay Samokhvalov100% (1)
- Returned Results Could Slightly Differ FromDocument3 pagesReturned Results Could Slightly Differ FromNikolay SamokhvalovNo ratings yet
- Gavin M. Roy: myYearBook - Com Architecture (Highload++, Moscow, Russia, October 2008)Document30 pagesGavin M. Roy: myYearBook - Com Architecture (Highload++, Moscow, Russia, October 2008)Nikolay Samokhvalov100% (1)
- Transaction Isolation in The Sedna Native XML DBMSDocument6 pagesTransaction Isolation in The Sedna Native XML DBMSNikolay SamokhvalovNo ratings yet
- Generalized Search Trees For Database SystemsDocument12 pagesGeneralized Search Trees For Database SystemsNikolay Samokhvalov100% (3)
- Asko Oja Training Talk (Moscow, Russia, October 2008)Document61 pagesAsko Oja Training Talk (Moscow, Russia, October 2008)Nikolay Samokhvalov100% (14)
- Video Radar Tps 78Document14 pagesVideo Radar Tps 78Nikolay SamokhvalovNo ratings yet
- Help Them Deal With Increasingly Significant Issues SuchDocument2 pagesHelp Them Deal With Increasingly Significant Issues SuchNikolay SamokhvalovNo ratings yet
- Вторая PostgreSQL-встреча: полнотекстовый поиск. Часть 2Document17 pagesВторая PostgreSQL-встреча: полнотекстовый поиск. Часть 2Nikolay Samokhvalov100% (1)
- PostgreSQL Promo (In Russian)Document2 pagesPostgreSQL Promo (In Russian)Nikolay Samokhvalov100% (2)
- Upcoming PostgreSQL Performance FeaturesDocument11 pagesUpcoming PostgreSQL Performance FeaturesNikolay Samokhvalov100% (3)
- PostgreSQL Promo FlyerDocument2 pagesPostgreSQL Promo FlyerNikolay SamokhvalovNo ratings yet
- The Implementation of POSTGRESDocument36 pagesThe Implementation of POSTGRESNikolay SamokhvalovNo ratings yet
- XML Support in PostgreSQLDocument6 pagesXML Support in PostgreSQLNikolay Samokhvalov100% (2)
- Upcoming PostgreSQL Performance FeaturesDocument11 pagesUpcoming PostgreSQL Performance FeaturesNikolay Samokhvalov100% (3)
- The Design of POSTGRESDocument28 pagesThe Design of POSTGRESNikolay SamokhvalovNo ratings yet
- PostgreSQL Performance TuningDocument63 pagesPostgreSQL Performance TuningNikolay Samokhvalov100% (9)
- Full-Text Search in PostgreSQLDocument77 pagesFull-Text Search in PostgreSQLNikolay Samokhvalov100% (20)
- The Design of The POSTGRES Storage SystemDocument19 pagesThe Design of The POSTGRES Storage SystemNikolay Samokhvalov100% (1)
- On Rules, Procedures, Caching and Views in Data Base SystemsDocument18 pagesOn Rules, Procedures, Caching and Views in Data Base SystemsNikolay Samokhvalov100% (1)
- The POSTGRES Data ModelDocument21 pagesThe POSTGRES Data ModelNikolay Samokhvalov100% (1)
- A Commentary On The POSTGRES Rules SystemDocument8 pagesA Commentary On The POSTGRES Rules SystemNikolay Samokhvalov100% (4)
- The Road To The XML Type. Current and Future DevelopmentsDocument54 pagesThe Road To The XML Type. Current and Future DevelopmentsNikolay SamokhvalovNo ratings yet
- QPDF Manual: For QPDF Version 8.0.2, March 6, 2018Document49 pagesQPDF Manual: For QPDF Version 8.0.2, March 6, 2018ctrplieff2669No ratings yet
- Chapter5 Testing The Software With Blinders OnDocument42 pagesChapter5 Testing The Software With Blinders Onx1y2z3qNo ratings yet
- Using The C Compilers On NetbeansDocument12 pagesUsing The C Compilers On NetbeansDoug RedNo ratings yet
- Sec Incident Resp Short FormDocument1 pageSec Incident Resp Short FormneuclearalphaNo ratings yet
- Debug Log Captures Initialization of Memory Forensics ToolDocument58 pagesDebug Log Captures Initialization of Memory Forensics TooljaphetjakeNo ratings yet
- Guide To OPCDocument9 pagesGuide To OPCpartho143No ratings yet
- SAS Procedures by NameDocument14 pagesSAS Procedures by Namekshen2001No ratings yet
- SALOME 7 7 1 Release NotesDocument31 pagesSALOME 7 7 1 Release Notesfermat91No ratings yet
- A/L ICT Competency 2.3Document4 pagesA/L ICT Competency 2.3Mohamed Irfan100% (7)
- Gradient Descent TutorialDocument3 pagesGradient Descent TutorialAntonioNo ratings yet
- SAP HANA XS Classic, Develop Your First SAP HANA XSC Application - SAPDocument10 pagesSAP HANA XS Classic, Develop Your First SAP HANA XSC Application - SAPSandeepNo ratings yet
- Mysql ArchitectureDocument10 pagesMysql ArchitectureRaghavan HNo ratings yet
- Rubrics For EcommerceDocument2 pagesRubrics For EcommerceChadZs Arellano MutiaNo ratings yet
- Automated Planning and ActingDocument472 pagesAutomated Planning and ActingVehid TavakolNo ratings yet
- Virtual Classroom Java Project ReportDocument42 pagesVirtual Classroom Java Project ReportShekhar Imvu100% (1)
- Mitac 8575a Service ManualDocument219 pagesMitac 8575a Service ManualvogliaNo ratings yet
- SP3D Common User GuideDocument13 pagesSP3D Common User GuideROHITNo ratings yet
- Stefano Markidis, Erwin Laure - Solving Software Challenges For Exascale 2015Document154 pagesStefano Markidis, Erwin Laure - Solving Software Challenges For Exascale 2015Nguyen Thanh BinhNo ratings yet
- Hibernate ArchitectureDocument18 pagesHibernate Architecturerina mahureNo ratings yet
- Java Fundamentals: Get Started With Alice 3 Get Started With Alice 3Document39 pagesJava Fundamentals: Get Started With Alice 3 Get Started With Alice 3Yana Siee PunkrockLowriderNo ratings yet
- SL95 CalInstructionsDocument2 pagesSL95 CalInstructionsalberto_030% (1)
- Guide-Writing Testable CodeDocument38 pagesGuide-Writing Testable Codebobbob24No ratings yet
- 83 - SUDO - Root Programme Unter User Laufen: SpecificationsDocument3 pages83 - SUDO - Root Programme Unter User Laufen: SpecificationssaeeddeepNo ratings yet
- A Powerful Genetic Algorithm For Traveling Salesman ProblemDocument5 pagesA Powerful Genetic Algorithm For Traveling Salesman ProblemIangrea Mustikane BumiNo ratings yet
- CO PO JustificationDocument4 pagesCO PO JustificationNithya Velam0% (1)
- PSO Codes MatlabDocument4 pagesPSO Codes MatlabJosemarPereiradaSilvaNo ratings yet
- Ug586 7series MISDocument164 pagesUg586 7series MISSriram VasudevanNo ratings yet
- Booking Test Case V 0.1 DraftDocument8 pagesBooking Test Case V 0.1 DraftgfrbggfNo ratings yet
- 64-Bit Real and Virtual StorageDocument20 pages64-Bit Real and Virtual Storagegene6658No ratings yet
- Vlsi Projects On Verilog and VHDLDocument3 pagesVlsi Projects On Verilog and VHDLsujan100% (1)