You might also like
- Filehost - CIA - Mind Control Techniques - (Ebook 197602 .TXT) (TEC@NZ)Document52 pagesFilehost - CIA - Mind Control Techniques - (Ebook 197602 .TXT) (TEC@NZ)razvan_9100% (1)
- Pilapil v. CADocument2 pagesPilapil v. CAIris Gallardo100% (2)
- MisII Manual PageDocument21 pagesMisII Manual PageMorgan PeemanNo ratings yet
- VoIPmonitor Sniffer Manual v5Document19 pagesVoIPmonitor Sniffer Manual v5Allan PadillaNo ratings yet
- Pea RubricDocument4 pagesPea Rubricapi-297637167No ratings yet
- 2015 Evaluating Multiple Classifiers For Stock Price Direction PredictionDocument11 pages2015 Evaluating Multiple Classifiers For Stock Price Direction PredictionhnavastNo ratings yet
- Optimum Array Processing: Part IV of Detection, Estimation, and Modulation TheoryFrom EverandOptimum Array Processing: Part IV of Detection, Estimation, and Modulation TheoryNo ratings yet
- Cache Coherence: Part I: CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012)Document31 pagesCache Coherence: Part I: CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012)botcreaterNo ratings yet
- Chapter 6 Bone Tissue 2304Document37 pagesChapter 6 Bone Tissue 2304Sav Oli100% (1)
- Semiotics Study of Movie ShrekDocument15 pagesSemiotics Study of Movie Shreky2pinku100% (1)
- Chapter 4Document23 pagesChapter 4TesfishoneNo ratings yet
- 19-Microendoscopic Lumbar DiscectomyDocument8 pages19-Microendoscopic Lumbar DiscectomyNewton IssacNo ratings yet
- The Music Tree Activities Book Part 1 Music Tree Summy PDF Book by Frances ClarkDocument3 pagesThe Music Tree Activities Book Part 1 Music Tree Summy PDF Book by Frances ClarkRenata Lemes0% (2)
- TOURISM AND HOSPITALITY ORGANIZATIONS Di Pa TapooosDocument97 pagesTOURISM AND HOSPITALITY ORGANIZATIONS Di Pa TapooosDianne EvangelistaNo ratings yet
- Improving Our Database ServiceDocument34 pagesImproving Our Database ServiceKiran RNo ratings yet
- Time Series Cheat SheetDocument2 pagesTime Series Cheat SheetAshkNo ratings yet
- Python Markov Decision Process Toolbox Documentation: Release 4.0-b4Document44 pagesPython Markov Decision Process Toolbox Documentation: Release 4.0-b4chakrapani2000No ratings yet
- Algorithms - Hidden Markov ModelsDocument7 pagesAlgorithms - Hidden Markov ModelsMani NadNo ratings yet
- AN002 Application Note: What Is A Quaternion?Document3 pagesAN002 Application Note: What Is A Quaternion?kirancallsNo ratings yet
- Kalman Filters For Parameter Estimation of Nonstationary SignalsDocument21 pagesKalman Filters For Parameter Estimation of Nonstationary Signalshendra lamNo ratings yet
- Parallela Cluster by Michael Johan KrugerDocument56 pagesParallela Cluster by Michael Johan KrugerGiacomo Marco ToigoNo ratings yet
- Localized Feature ExtractionDocument6 pagesLocalized Feature ExtractionsujithaNo ratings yet
- Classic RISC PipelineDocument10 pagesClassic RISC PipelineShantheri BhatNo ratings yet
- Application of Digital Signal Processing in Radar: A StudyDocument4 pagesApplication of Digital Signal Processing in Radar: A StudyijaertNo ratings yet
- Brinson Fachler 1985 Multi Currency PADocument4 pagesBrinson Fachler 1985 Multi Currency PAGeorgi MitovNo ratings yet
- Cuda C/C++ Basics: NVIDIA CorporationDocument67 pagesCuda C/C++ Basics: NVIDIA Corporationrj jNo ratings yet
- Blacher - Pricing With A Volatility SmileDocument2 pagesBlacher - Pricing With A Volatility Smilefrolloos100% (1)
- A Study of Sample Matrix Inversion Algorithm For PDFDocument5 pagesA Study of Sample Matrix Inversion Algorithm For PDFRamya RNo ratings yet
- Deep Reinforcement Learning Nanodegree Program SyllabusDocument4 pagesDeep Reinforcement Learning Nanodegree Program Syllabusİlkan SüslüNo ratings yet
- SSL TlsDocument17 pagesSSL TlsSunil KumarNo ratings yet
- Lab1 Introduction To OmnetDocument23 pagesLab1 Introduction To OmnetGhadeer Sami SwagedNo ratings yet
- Table of Contents - LatestDocument5 pagesTable of Contents - LatestGaurav ManglaNo ratings yet
- Introduction To Communications: Channel CodingDocument27 pagesIntroduction To Communications: Channel CodingHarshaNo ratings yet
- Overview of Quantitative Finance and Risk Management 0710Document38 pagesOverview of Quantitative Finance and Risk Management 0710pharssNo ratings yet
- Digital System Design Using Verilog December 2011Document1 pageDigital System Design Using Verilog December 2011Vinayaka HmNo ratings yet
- Greek Letters of FinanceDocument40 pagesGreek Letters of FinanceshahkrunaNo ratings yet
- LmfitDocument117 pagesLmfitVíctor KNo ratings yet
- Lightgbm Gradient Boosting TreeDocument9 pagesLightgbm Gradient Boosting TreeweaponNo ratings yet
- Signal Flow Graph - GATE Study Material in PDFDocument5 pagesSignal Flow Graph - GATE Study Material in PDFAalen IssacNo ratings yet
- Sysml Tutorial PDFDocument20 pagesSysml Tutorial PDFDaniel Stiven TamayoNo ratings yet
- Different Examples of HDLDocument12 pagesDifferent Examples of HDLHanna Abejo0% (1)
- Building Expert Systems in PrologDocument308 pagesBuilding Expert Systems in Prologmaurobio100% (1)
- CECS 347 Programming in C Sylabus: Writing C Code For The 8051Document52 pagesCECS 347 Programming in C Sylabus: Writing C Code For The 8051BHUSHANNo ratings yet
- 1improvement Algorithms of Perceptually Important P PDFDocument5 pages1improvement Algorithms of Perceptually Important P PDFredameNo ratings yet
- Ethernet With 8051Document57 pagesEthernet With 8051pradeepkverma100% (2)
- Collision-Free ProtocolDocument3 pagesCollision-Free ProtocolNetmat GumesNo ratings yet
- Excel Link 3 User GuideDocument88 pagesExcel Link 3 User GuideZeljko RisticNo ratings yet
- Presentation - 02 Reliability in Computer SystemsDocument24 pagesPresentation - 02 Reliability in Computer Systemsvictorwu.ukNo ratings yet
- Computing and Informatics Class Notes For AMIEDocument46 pagesComputing and Informatics Class Notes For AMIEAkeel Aijaz MalikNo ratings yet
- EE8691 Embedded Systems NotesDocument76 pagesEE8691 Embedded Systems NotesMalik MubeenNo ratings yet
- Computer Science Textbook Solutions - 4Document30 pagesComputer Science Textbook Solutions - 4acc-expertNo ratings yet
- HSPICE Toolbox For Matlab and Octave (Also For Use With Ngspice)Document5 pagesHSPICE Toolbox For Matlab and Octave (Also For Use With Ngspice)Wala SaadehNo ratings yet
- Syllabus: Microverse Web Development ProgramDocument3 pagesSyllabus: Microverse Web Development ProgramEzelNo ratings yet
- Solutions Image Processing Ulaby YagleDocument110 pagesSolutions Image Processing Ulaby YagleIrshadh Ibrahim0% (1)
- Facial Recognition Using Eigen FacesDocument3 pagesFacial Recognition Using Eigen FacesAkshay ShindeNo ratings yet
- Machine Learning - Stanford University - CourseraDocument16 pagesMachine Learning - Stanford University - CourseraDaniel FloresNo ratings yet
- 6th Sem Bput Eee SyllabusDocument8 pages6th Sem Bput Eee SyllabusSuneet Kumar RathNo ratings yet
- CNS (Vikram)Document121 pagesCNS (Vikram)Shreyas BaligaNo ratings yet
- CDMA - Flexent Autoplex ECP Release 17 - 0 PDFDocument626 pagesCDMA - Flexent Autoplex ECP Release 17 - 0 PDFrnesi100% (1)
- Opening Range PaperDocument7 pagesOpening Range PaperAHGrimes0% (1)
- Features of 8086Document31 pagesFeatures of 8086Ngaa SiemensNo ratings yet
- Arm Assembly Language ProgrammingDocument9 pagesArm Assembly Language ProgrammingMohammadEjazArif100% (1)
- Compiler Design-RavirajDocument56 pagesCompiler Design-RavirajRavi RajNo ratings yet
- Understanding of A Convolutional Neural NetworkDocument6 pagesUnderstanding of A Convolutional Neural NetworkJavier BushNo ratings yet
- Ternary Chalcopyrite Semiconductors: Growth, Electronic Properties, and Applications: International Series of Monographs in The Science of The Solid StateFrom EverandTernary Chalcopyrite Semiconductors: Growth, Electronic Properties, and Applications: International Series of Monographs in The Science of The Solid StateRating: 3 out of 5 stars3/5 (1)
- A - Persuasive TextDocument15 pagesA - Persuasive TextMA. MERCELITA LABUYONo ratings yet
- 6401 1 NewDocument18 pages6401 1 NewbeeshortNo ratings yet
- DE1734859 Central Maharashtra Feb'18Document39 pagesDE1734859 Central Maharashtra Feb'18Adesh NaharNo ratings yet
- Durst Caldera: Application GuideDocument70 pagesDurst Caldera: Application GuideClaudio BasconiNo ratings yet
- Game Theory Presentation: Big BrotherDocument11 pagesGame Theory Presentation: Big BrotherNitinNo ratings yet
- Lifelong Learning: Undergraduate Programs YouDocument8 pagesLifelong Learning: Undergraduate Programs YouJavier Pereira StraubeNo ratings yet
- End of Semester Student SurveyDocument2 pagesEnd of Semester Student SurveyJoaquinNo ratings yet
- Pharmaniaga Paracetamol Tablet: What Is in This LeafletDocument2 pagesPharmaniaga Paracetamol Tablet: What Is in This LeafletWei HangNo ratings yet
- Symptoms: Generalized Anxiety Disorder (GAD)Document3 pagesSymptoms: Generalized Anxiety Disorder (GAD)Nur WahyudiantoNo ratings yet
- PLSQL Day 1Document12 pagesPLSQL Day 1rambabuNo ratings yet
- Lower Gastrointestinal BleedingDocument1 pageLower Gastrointestinal Bleedingmango91286No ratings yet
- Wastewater Treatment: Sudha Goel, Ph.D. Department of Civil Engineering, IIT KharagpurDocument33 pagesWastewater Treatment: Sudha Goel, Ph.D. Department of Civil Engineering, IIT KharagpurSubhajit BagNo ratings yet
- Allen F. y D. Gale. Comparative Financial SystemsDocument80 pagesAllen F. y D. Gale. Comparative Financial SystemsCliffordTorresNo ratings yet
- Elements of PoetryDocument5 pagesElements of PoetryChristian ParkNo ratings yet
- ENTRAPRENEURSHIPDocument29 pagesENTRAPRENEURSHIPTanmay Mukherjee100% (1)
- Micro TeachingDocument3 pagesMicro Teachingapi-273530753No ratings yet
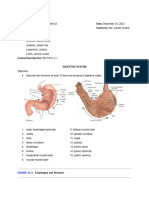
- Digestive System LabsheetDocument4 pagesDigestive System LabsheetKATHLEEN MAE HERMONo ratings yet
- Thomas HobbesDocument3 pagesThomas HobbesatlizanNo ratings yet
- Finding Neverland Study GuideDocument7 pagesFinding Neverland Study GuideDean MoranNo ratings yet
- 2 Lista Total de Soportados 14-12-2022Document758 pages2 Lista Total de Soportados 14-12-2022Emanuel EspindolaNo ratings yet
- Basics of An Model United Competition, Aippm, All India Political Parties' Meet, Mun Hrishkesh JaiswalDocument7 pagesBasics of An Model United Competition, Aippm, All India Political Parties' Meet, Mun Hrishkesh JaiswalHRISHIKESH PRAKASH JAISWAL100% (1)
- Review Questions & Answers For Midterm1: BA 203 - Financial Accounting Fall 2019-2020Document11 pagesReview Questions & Answers For Midterm1: BA 203 - Financial Accounting Fall 2019-2020Ulaş GüllenoğluNo ratings yet