You might also like
- 20 Consejos para Aprender Ingles - Clasing - EbookDocument6 pages20 Consejos para Aprender Ingles - Clasing - EbookJHNo ratings yet
- Reglas para formar plural de los sustantivos en inglésDocument16 pagesReglas para formar plural de los sustantivos en inglésHarold Mendieta100% (1)
- Guia Definitiva de Tiempos Verbales en InglésDocument9 pagesGuia Definitiva de Tiempos Verbales en Inglésjose luis rojas gomezNo ratings yet
- Koe 2 PDF FreeDocument1 pageKoe 2 PDF FreeLETTY BLOWNo ratings yet
- 06 Business Grammar AbaenglishDocument73 pages06 Business Grammar AbaenglishAlberto Torres MalalenguaNo ratings yet
- Cómo Aprender Inglés de Manera NaturalDocument102 pagesCómo Aprender Inglés de Manera NaturalJerry AlemanNo ratings yet
- 03 Calculo de Tuberia de Alimentacion A CisternaDocument35 pages03 Calculo de Tuberia de Alimentacion A CisternaFavio Cueva100% (3)
- Fichas Curso de Ingls Definitivo PDF VaughanDocument2 pagesFichas Curso de Ingls Definitivo PDF VaughanMichaelNo ratings yet
- Vocabulario InglésDocument10 pagesVocabulario InglésMLlanos PGNo ratings yet
- 198 English Paragraphs - Vaughan Systems For Varied English ExercisesDocument12 pages198 English Paragraphs - Vaughan Systems For Varied English ExercisesakilossNo ratings yet
- Guía de comandos de STATADocument17 pagesGuía de comandos de STATAGaby Ht100% (3)
- Gerundios en Inglés LisbetDocument21 pagesGerundios en Inglés Lisbetcarlos panacualNo ratings yet
- Laboratorios RichmondDocument6 pagesLaboratorios RichmondAgus GarciaNo ratings yet
- Tablas SAPDocument4 pagesTablas SAPJuanNo ratings yet
- Laboratorios Richmond - Estados + RatiosDocument10 pagesLaboratorios Richmond - Estados + RatiosAgus GarciaNo ratings yet
- 1000 Frases Más Usadas en Inglés. Expresiones ComunesDocument108 pages1000 Frases Más Usadas en Inglés. Expresiones ComunesLuis Adrian OrtegaNo ratings yet
- List of Phrasal Verbs PDF Más UsadosDocument4 pagesList of Phrasal Verbs PDF Más UsadosOrlando LazoNo ratings yet
- Ingles de La CalleDocument10 pagesIngles de La CalleaxelpulgarNo ratings yet
- TortasDocument6 pagesTortasJUAN ENRIQUEZNo ratings yet
- Manual Sancion.. TransporteMercancías Perecederas PDFDocument36 pagesManual Sancion.. TransporteMercancías Perecederas PDFCapacitaciones RutasNo ratings yet
- MAN30 Fundamentos ComputadoresDocument300 pagesMAN30 Fundamentos Computadoresignacio fernandez luengo100% (1)
- Qué Es Un MetaplánDocument2 pagesQué Es Un Metaplánjoe0208No ratings yet
- Modelado y Control de Molinos de Caña de Azucar PDFDocument171 pagesModelado y Control de Molinos de Caña de Azucar PDFIdiLab Emprendimiento100% (5)
- 10 Claves para Aprender Ingles y DominarloDocument19 pages10 Claves para Aprender Ingles y DominarloPaulo AmorimNo ratings yet
- 3 Secretos de La Sabiduría Antigua para Ser FelicesDocument3 pages3 Secretos de La Sabiduría Antigua para Ser FelicesSofia VioletaNo ratings yet
- Cruces Nadal Rafael Tarea Online 5Document42 pagesCruces Nadal Rafael Tarea Online 5Jessica Pozo MartinNo ratings yet
- Fichas VaughanDocument1 pageFichas VaughanPedro Mata DuranNo ratings yet
- Sistemas de Administracion de Bases de Datos PDFDocument2 pagesSistemas de Administracion de Bases de Datos PDFGuillermo Llidó Parra0% (1)
- Fichas Visuales InglesDocument274 pagesFichas Visuales InglesMjose JsNo ratings yet
- Informacion General Reconversion Monetaria SapDocument8 pagesInformacion General Reconversion Monetaria SapOscar IbarraNo ratings yet
- Instrucciones de Uso Incubadora Suro 20Document12 pagesInstrucciones de Uso Incubadora Suro 20dcruzp78No ratings yet
- Directiva 0409 de 2015Document32 pagesDirectiva 0409 de 2015biric14 SECCION SEGUNDANo ratings yet
- Adaptacion Italiano B1 08Document8 pagesAdaptacion Italiano B1 08PERDHRO DIEGONo ratings yet
- Ebook Whatsup Expresiones en InglesDocument14 pagesEbook Whatsup Expresiones en InglesALfredo ROldanNo ratings yet
- Manual Agora RestaurantDocument711 pagesManual Agora RestaurantJuanjo Serrano0% (1)
- Apuntes QlikViewDocument9 pagesApuntes QlikViewlucho60No ratings yet
- Tablas Dinamicas 2016Document4 pagesTablas Dinamicas 2016Anonymous Rd0yrjNo ratings yet
- Controller Financiero & Auditor Interno (Grupo)Document1 pageController Financiero & Auditor Interno (Grupo)Alvaro AleksandroffNo ratings yet
- Ps MatchingDocument10 pagesPs MatchingGustavo F. Huamán FernándezNo ratings yet
- Tema 1Document8 pagesTema 1Luis MendozaNo ratings yet
- Guía Instalación ODLDocument5 pagesGuía Instalación ODLLeonardo Valenzuela100% (1)
- Un Marco Teórico Alternativo..input PDFDocument14 pagesUn Marco Teórico Alternativo..input PDFOlga SosaNo ratings yet
- Palab Ingles 4Document18 pagesPalab Ingles 4Benjamin CruzNo ratings yet
- Lab 9Document8 pagesLab 9Anonymous 47WfjWVNo ratings yet
- Ejemplos de Operatoria-Version 1Document49 pagesEjemplos de Operatoria-Version 1Martin100% (2)
- Costos PresupuestosDocument256 pagesCostos PresupuestosDon GonzaloNo ratings yet
- Separata de ExelDocument39 pagesSeparata de ExelAldo LlanoNo ratings yet
- Metodologia VAR PDFDocument49 pagesMetodologia VAR PDFInnovación Comercio Internacional y aduanasNo ratings yet
- Desde Excel A Google EarthDocument3 pagesDesde Excel A Google Earthangelica valderramaNo ratings yet
- Las 97 Cosas Que Todo Programador Debería SaberDocument107 pagesLas 97 Cosas Que Todo Programador Debería SaberJefferson CabreraNo ratings yet
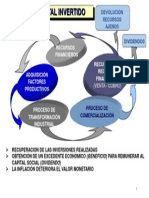
- Ciclo Del Capital Invertido PDFDocument1 pageCiclo Del Capital Invertido PDFFelix RinaldiNo ratings yet
- Data Wrangling SpanishDocument2 pagesData Wrangling SpanishCristian GarciaNo ratings yet
- Tell Me More EnglishDocument1 pageTell Me More EnglishgatochaletNo ratings yet
- Aprender InglesDocument7 pagesAprender InglesJorge KingNo ratings yet
- Guía Didáctica Comunicacion de DatosDocument71 pagesGuía Didáctica Comunicacion de DatosJCBILBAONo ratings yet
- AdjectivesDocument6 pagesAdjectiveslahefaNo ratings yet
- Manual Teletrabajo TrenDigital UC PDFDocument44 pagesManual Teletrabajo TrenDigital UC PDFAtalia Isaid OrdoñezNo ratings yet
- 771ca Librecad 2015Document81 pages771ca Librecad 2015calderondelacanoa100% (1)
- Comandos de StataDocument15 pagesComandos de StataLuiiz Segu'ura100% (1)
- Comandos de StataDocument15 pagesComandos de StataMauricio Catalán BezemerNo ratings yet
- Guia Stata 1 Introduccion StataDocument7 pagesGuia Stata 1 Introduccion Statagonzalo bustamante rojasNo ratings yet
- Comandos StataDocument16 pagesComandos StataJuan Jose Barrera CuellarNo ratings yet
- Stata Sesion 2Document4 pagesStata Sesion 2Jhonatan EscaleraNo ratings yet
- TablespaceDocument5 pagesTablespacemiguelNo ratings yet
- Unidad 1 Torneado de Conos y Tornillo Sin Fin v0Document27 pagesUnidad 1 Torneado de Conos y Tornillo Sin Fin v0Hector CRNo ratings yet
- Definiciones de Mercadotecnia: Similitudes y DiferenciasDocument2 pagesDefiniciones de Mercadotecnia: Similitudes y DiferenciasCecilia Muñoz Oceguera100% (2)
- CaratulaDocument1 pageCaratulaMarco Cayampi UlloaNo ratings yet
- Sistemas de Información Gerencial Caso DominosDocument3 pagesSistemas de Información Gerencial Caso DominosCarlos MejiaNo ratings yet
- Formato de Entrevista EstructuradaDocument3 pagesFormato de Entrevista EstructuradaJohn Aaron Cortez DamianNo ratings yet
- Articulo Evolucion Talento HumanoDocument5 pagesArticulo Evolucion Talento HumanoJavier CepedaNo ratings yet
- Superestructura TurísticaDocument4 pagesSuperestructura TurísticaAnnie Brown0% (1)
- Proyectos de InversiónDocument52 pagesProyectos de InversiónAnamin Yrrazaba100% (1)
- Credo de los ApóstolesDocument5 pagesCredo de los Apóstoleslucia moranNo ratings yet
- ReacsaDocument2 pagesReacsaSandra Leyva GuerreroNo ratings yet
- I9 OndasDocument4 pagesI9 OndasAlexis ArdilaNo ratings yet
- Tratamiento de Residuos PetrolizadosDocument11 pagesTratamiento de Residuos PetrolizadosKarenOviedoNo ratings yet
- Diseño de CV, horario y afiche para la práctica calificada 1 de Fundamentos de InformáticaDocument10 pagesDiseño de CV, horario y afiche para la práctica calificada 1 de Fundamentos de InformáticaGary SurquisllaNo ratings yet
- Desomi - Sesion IVDocument18 pagesDesomi - Sesion IVAlexandra de la CadenaNo ratings yet
- CURVAS DE DESPLAZAMIENTO INTERRUPTOR DE ALTA TENSIÓN - ZensolDocument12 pagesCURVAS DE DESPLAZAMIENTO INTERRUPTOR DE ALTA TENSIÓN - ZensolEddy Fernando Queca CadizNo ratings yet
- PRÁCTICA 2 - PARTE II (13%) - Revisión Del IntentoDocument5 pagesPRÁCTICA 2 - PARTE II (13%) - Revisión Del IntentoVanesa CardonaNo ratings yet
- Anexo 3 Volante de BuzónDocument2 pagesAnexo 3 Volante de BuzónDennis Mart CampNo ratings yet
- Presupuesto para mejorar el servicio de agua y saneamiento en Alto Algarrobo y Bajo AlgarroboDocument11 pagesPresupuesto para mejorar el servicio de agua y saneamiento en Alto Algarrobo y Bajo AlgarroboSamuel Chacon RomanNo ratings yet
- Método Servqual y El Método ServperfDocument5 pagesMétodo Servqual y El Método ServperfEL CesarNo ratings yet
- Universidad Autónoma de Chiriquí Laboratorio#3Document7 pagesUniversidad Autónoma de Chiriquí Laboratorio#3HeidyNuñezNo ratings yet
- M1 U1 JOHB AutoevaluaciónDocument3 pagesM1 U1 JOHB AutoevaluaciónJesus Hernandez BartoloNo ratings yet
- 2016 Procesos Silabo MC 216Document5 pages2016 Procesos Silabo MC 216Larry BerriosNo ratings yet
- La Globalizacion Manuel CastellDocument14 pagesLa Globalizacion Manuel CastellCecilia Comesana DuranNo ratings yet
- Transportadores de CintaDocument46 pagesTransportadores de CintaEsteban WNo ratings yet
- Voluntariado Con Personas Con Discapacidad IntelectualDocument38 pagesVoluntariado Con Personas Con Discapacidad IntelectualFrancisco Vela MotaNo ratings yet
- Compresores ResumenDocument10 pagesCompresores Resumenfernandilote0% (1)