You might also like
- The Seven Secrets of Extremely Prosperous PeopleDocument20 pagesThe Seven Secrets of Extremely Prosperous Peopleakoo100% (29)
- Food & Recipes Ethiopia: September 2011Document11 pagesFood & Recipes Ethiopia: September 2011robel2012No ratings yet
- Microdose Chapter 1Document8 pagesMicrodose Chapter 1Luis PruyasNo ratings yet
- The Beginners Guide To Micro NichesDocument22 pagesThe Beginners Guide To Micro NicheselsaliliNo ratings yet
- Fees Structure For Government Sponsored (KUCCPS) Students: University of Eastern Africa, BaratonDocument3 pagesFees Structure For Government Sponsored (KUCCPS) Students: University of Eastern Africa, BaratonGiddy LerionkaNo ratings yet
- The Cactus Growers FileDocument9 pagesThe Cactus Growers Fileneli00No ratings yet
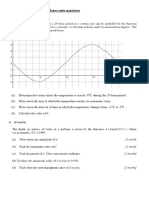
- Sine and Cosine Exam QuestionsDocument8 pagesSine and Cosine Exam QuestionsGamer Shabs100% (1)
- Food Allergies, Warts Fungal Infections, Yeast Infections GingivitisDocument6 pagesFood Allergies, Warts Fungal Infections, Yeast Infections GingivitisJackNo ratings yet
- Home Kakhia Public HTML Tarek Books Eng Alkaloids - Tarek KakhiaDocument479 pagesHome Kakhia Public HTML Tarek Books Eng Alkaloids - Tarek KakhiaDwi Anggi100% (1)
- Religion, Hallucinogens and the Ancient Mochica People of PeruDocument16 pagesReligion, Hallucinogens and the Ancient Mochica People of PeruCeline Brantegem100% (1)
- Granny Storm Crow's List - January 2014 PHYTODocument101 pagesGranny Storm Crow's List - January 2014 PHYTOElectroPig Von FökkenGrüüven100% (1)
- Creature Loot PDF - GM BinderDocument97 pagesCreature Loot PDF - GM BinderAlec0% (1)
- Guava Soap For Investigatory ProjectDocument2 pagesGuava Soap For Investigatory ProjectfebyNo ratings yet
- Essential Oil of The Month: SandlewoodDocument2 pagesEssential Oil of The Month: SandlewoodAnumeha Jindal0% (1)
- Physicians Who Offer IV H2O2 Bioluminescence TherapyDocument22 pagesPhysicians Who Offer IV H2O2 Bioluminescence TherapypererNo ratings yet
- Orange Essential OilDocument4 pagesOrange Essential OilNada PetrovićNo ratings yet
- The Foundations of IncenseDocument17 pagesThe Foundations of IncenseKawtar ElkadriNo ratings yet
- Abinitio Interview QuesDocument30 pagesAbinitio Interview QuesVasu ManchikalapudiNo ratings yet
- Psychedelic LichensDocument4 pagesPsychedelic LichensJon. . .No ratings yet
- Total Phenolic Content and Antioxydant Activity of Two Rhododendron Species Collected From The Rize Province (Turkey)Document6 pagesTotal Phenolic Content and Antioxydant Activity of Two Rhododendron Species Collected From The Rize Province (Turkey)Premier Publishers100% (1)
- Chemistry Project (Final)Document23 pagesChemistry Project (Final)Rohan PatelNo ratings yet
- Aromatherapy 1Document42 pagesAromatherapy 1rudreshadarkar04No ratings yet
- Masculine Scents SpicyDocument2 pagesMasculine Scents SpicyGabrielle May LacsamanaNo ratings yet
- A Taxonomic Revision of The Pentandrous Species of AristolochiaDocument73 pagesA Taxonomic Revision of The Pentandrous Species of Aristolochiasylvernet100% (1)
- Investigation of the Shô-gyu and Yu-Ju Oils Produced in FormosaFrom EverandInvestigation of the Shô-gyu and Yu-Ju Oils Produced in FormosaNo ratings yet
- PQ of Vial Washer Ensures Removal of ContaminantsDocument25 pagesPQ of Vial Washer Ensures Removal of ContaminantsJuan DanielNo ratings yet
- Passive HouseDocument16 pagesPassive HouseZarkima RanteNo ratings yet
- 2288 7485 1 PB PDFDocument7 pages2288 7485 1 PB PDFrajashekhar asNo ratings yet
- Karakteristik Dan Sifat Fisiko-Kimia Berbagai Kualitas Kemenyan Di Sumatera Utara (Characteristics and Physico-Chemical Properties of Benzoin GumDocument15 pagesKarakteristik Dan Sifat Fisiko-Kimia Berbagai Kualitas Kemenyan Di Sumatera Utara (Characteristics and Physico-Chemical Properties of Benzoin Gumanon_254481958No ratings yet
- FlyerDocument3 pagesFlyerJavier100% (1)
- FAKE - Don't Use This: Enable The Body To Gradually Absorb and Assimilate The HDocument19 pagesFAKE - Don't Use This: Enable The Body To Gradually Absorb and Assimilate The Hsairam1975No ratings yet
- Full Text of The Useful Plants of IndiaDocument2,915 pagesFull Text of The Useful Plants of IndiaAnonymous 6HADGUEXD100% (1)
- INCENSEDocument2 pagesINCENSERakshit JainNo ratings yet
- Secoin Incenses & AgarbattisDocument5 pagesSecoin Incenses & AgarbattisDinh xuan BaNo ratings yet
- Substitutions For Magickal Work and IncenseDocument4 pagesSubstitutions For Magickal Work and IncenseAradialevanahNo ratings yet
- Hydrogen Peroxide PDFDocument20 pagesHydrogen Peroxide PDFzibaNo ratings yet
- Experiments with Plants Reveal How Seeds SproutDocument525 pagesExperiments with Plants Reveal How Seeds SproutakantharaNo ratings yet
- The Ultimate Perfume PlaybookDocument13 pagesThe Ultimate Perfume Playbookomaralsaadi92100% (1)
- Benefits of Sea Incense, Indian Wood and Olive OilDocument4 pagesBenefits of Sea Incense, Indian Wood and Olive OilPost2BoxNo ratings yet
- Agarbatti MakingDocument8 pagesAgarbatti MakingAmolSuhasVedpathakNo ratings yet
- Hydrogen Peroxide MSDSDocument10 pagesHydrogen Peroxide MSDSEddy EffendiNo ratings yet
- Abstract of (1936) - by Sara Benetowa (Sula Benet)Document9 pagesAbstract of (1936) - by Sara Benetowa (Sula Benet)Rafael Andres EscribanoNo ratings yet
- Turmeric A Herbal and Traditional MedicineDocument24 pagesTurmeric A Herbal and Traditional MedicineSamNo ratings yet
- Essenc I Er InstructionDocument2 pagesEssenc I Er InstructiondadduuuddNo ratings yet
- Polish WodkaDocument29 pagesPolish WodkasachinNo ratings yet
- 062 Hydrogen PerroxideDocument11 pages062 Hydrogen Perroxideeng20072007No ratings yet
- Shama PerfumesDocument17 pagesShama Perfumesmahesh11233No ratings yet
- 1 PBDocument8 pages1 PBmane_cute_meNo ratings yet
- Morinda Citrifolia L. (Noni) Fruit: Analgesic and Antiinflammatory Activity ofDocument5 pagesMorinda Citrifolia L. (Noni) Fruit: Analgesic and Antiinflammatory Activity ofscribd6069No ratings yet
- Material Safety Data Sheet: 1. Identification of Substance/Preparation & CompanyDocument4 pagesMaterial Safety Data Sheet: 1. Identification of Substance/Preparation & CompanyCarlos ThomasNo ratings yet
- Sacred Sandalwood Crafts of KarnatakaDocument29 pagesSacred Sandalwood Crafts of KarnatakaKapil Sikka100% (1)
- NATUECO Book PDFDocument112 pagesNATUECO Book PDFpuvichandranNo ratings yet
- Iao Primer v2Document13 pagesIao Primer v2pipiNo ratings yet
- 2019.07.16 US Hemp Roundtable FDA CommentsDocument29 pages2019.07.16 US Hemp Roundtable FDA CommentsHalcyonPublishing100% (1)
- Steam Distillation of Carvone from Caraway and SpearmintDocument11 pagesSteam Distillation of Carvone from Caraway and SpearmintMunna Patel100% (2)
- Manufacture of Limonene PDFDocument147 pagesManufacture of Limonene PDFLoreli Sanchez0% (1)
- Unik Aloe Vera PP PresentationDocument77 pagesUnik Aloe Vera PP PresentationTAMBAKI EDMOND100% (3)
- Krishna ScentDocument1 pageKrishna ScentTheScienceOfTimeNo ratings yet
- Turmeric PlantDocument5 pagesTurmeric PlantanjalisweNo ratings yet
- E 2017 1 Expertenwissen GeruchsschulungDocument24 pagesE 2017 1 Expertenwissen Geruchsschulungatila117No ratings yet
- The Mystery of Metamorphosis - Foreword by Lynn Margulis and Dorion SaganDocument5 pagesThe Mystery of Metamorphosis - Foreword by Lynn Margulis and Dorion SaganChelsea Green Publishing100% (1)
- Decision Tree Classifiers To Determine The Patient's Post-Operative Recovery DecisionDocument13 pagesDecision Tree Classifiers To Determine The Patient's Post-Operative Recovery DecisionAI Coordinator - CSC JournalsNo ratings yet
- Data Science in HealthcareDocument15 pagesData Science in HealthcareK NandanNo ratings yet
- Final Project ML ReportDocument6 pagesFinal Project ML ReportSiti Hawa Abd HamidNo ratings yet
- A Survey On Cardiac Disease Classifying From Imbalanced Healthcare Facts Using Ensemble Classification TechniquesDocument6 pagesA Survey On Cardiac Disease Classifying From Imbalanced Healthcare Facts Using Ensemble Classification TechniquesIJRASETPublicationsNo ratings yet
- Disease Prediction Using Machine LearningDocument3 pagesDisease Prediction Using Machine LearningjohnnyNo ratings yet
- Reference Website Addresses of Korea ICTDocument3 pagesReference Website Addresses of Korea ICTakooNo ratings yet
- Licensing Issues, Markets and Innovations in Software Industry in U.S (Term Paper in SNU)Document13 pagesLicensing Issues, Markets and Innovations in Software Industry in U.S (Term Paper in SNU)akoo100% (1)
- Implementation and Implication of Digital Opportunity Index - DOI - in MyanmarDocument2 pagesImplementation and Implication of Digital Opportunity Index - DOI - in MyanmarakooNo ratings yet
- The Convergence of Telecommunications and Broadcasting (Fall' 06)Document69 pagesThe Convergence of Telecommunications and Broadcasting (Fall' 06)akoo100% (2)
- IT Innovation Study Research Team in SNUDocument2 pagesIT Innovation Study Research Team in SNUakooNo ratings yet
- Investment Analysis On The PH D Course in TEMAP (Term Paper in SNU) (2006)Document25 pagesInvestment Analysis On The PH D Course in TEMAP (Term Paper in SNU) (2006)akoo100% (1)
- Applicability of Utility Grid Computing in The Telecommunication Sector of Myanmar (Term Paper, SNU) - (Spring' 07)Document24 pagesApplicability of Utility Grid Computing in The Telecommunication Sector of Myanmar (Term Paper, SNU) - (Spring' 07)akoo100% (3)
- Essay For Productivity Class (TEMEP in SNU)Document8 pagesEssay For Productivity Class (TEMEP in SNU)akooNo ratings yet
- Status and Overview of Official ICT Indicators of ChinaDocument20 pagesStatus and Overview of Official ICT Indicators of ChinaakooNo ratings yet
- Ph.D. Thesis (Abstract) - (TEMEP in SNU) (Feb'09)Document10 pagesPh.D. Thesis (Abstract) - (TEMEP in SNU) (Feb'09)akoo100% (3)
- Foreign Direct Investment and IT Industry in IndiaDocument20 pagesForeign Direct Investment and IT Industry in Indiaakoo100% (19)
- Policy Issues Related To Technical Innovations in ICT in Myanmar (Term Paper in SNU)Document12 pagesPolicy Issues Related To Technical Innovations in ICT in Myanmar (Term Paper in SNU)akoo100% (2)
- Public-Private Partnership (Fourth Seminar in SNU) (Oct'06)Document13 pagesPublic-Private Partnership (Fourth Seminar in SNU) (Oct'06)akooNo ratings yet
- Public-Private Partnership (Third Seminar in SNU) (Oct' 06)Document17 pagesPublic-Private Partnership (Third Seminar in SNU) (Oct' 06)akoo100% (2)
- Public-Private Partership (PPP) (2nd Seminar in SNU) (Sept'06)Document11 pagesPublic-Private Partership (PPP) (2nd Seminar in SNU) (Sept'06)akooNo ratings yet
- Performance Evaluation On Automated Grammar Checkers As Knowledge SystemsDocument3 pagesPerformance Evaluation On Automated Grammar Checkers As Knowledge Systemsakoo100% (2)
- Public-Private Partnership (Fifth Seminar in SNU) (Nov' 07)Document21 pagesPublic-Private Partnership (Fifth Seminar in SNU) (Nov' 07)akoo100% (1)
- Call For Articles: SNU-ITPP NewsletterDocument2 pagesCall For Articles: SNU-ITPP NewsletterakooNo ratings yet
- Int'l ICT Workshop (Vietnam, 2007)Document3 pagesInt'l ICT Workshop (Vietnam, 2007)akooNo ratings yet
- Public-Private Partnership (Seminar Presentation) (September'06)Document21 pagesPublic-Private Partnership (Seminar Presentation) (September'06)akoo100% (2)
- ICT Policy Management System Between Korea and MyanmarDocument1 pageICT Policy Management System Between Korea and MyanmarakooNo ratings yet
- SNU-TEMEP Workshop Program (Fall' 2008)Document2 pagesSNU-TEMEP Workshop Program (Fall' 2008)akooNo ratings yet
- Telecommunications Landscape in The U.S (SNU Invited Lecture)Document64 pagesTelecommunications Landscape in The U.S (SNU Invited Lecture)akoo100% (3)
- Empirical Analysis On Object-Oriented Systems Using Dynamic CouplingDocument5 pagesEmpirical Analysis On Object-Oriented Systems Using Dynamic Couplingakoo100% (4)
- Why Is Dokdo Korean Territory - Selected Essay in Dok-Do Essay ContestDocument2 pagesWhy Is Dokdo Korean Territory - Selected Essay in Dok-Do Essay Contestakoo100% (1)
- SNU-ITPP Newsletter CommitteeDocument1 pageSNU-ITPP Newsletter CommitteeakooNo ratings yet
- BAI 2009 Call For PapersDocument4 pagesBAI 2009 Call For Papersakoo100% (2)
- OR 50, University of York, 2008, Myanmar, ITPP, TEMEP, SNU, AHP, Public Procurement, Government, UCSY, Aung Kyaw Oo, Defence, Ph.D., Decision Science, Jeong-Dong Lee, Jong-Su Lee, Jung-Seok Hwang, ICT, Decision Analysis, Tai-Yoo kim, Nilar Thein, Government, Success Factors, MCDM, DSSDocument2 pagesOR 50, University of York, 2008, Myanmar, ITPP, TEMEP, SNU, AHP, Public Procurement, Government, UCSY, Aung Kyaw Oo, Defence, Ph.D., Decision Science, Jeong-Dong Lee, Jong-Su Lee, Jung-Seok Hwang, ICT, Decision Analysis, Tai-Yoo kim, Nilar Thein, Government, Success Factors, MCDM, DSSakooNo ratings yet
- Huawei Switch S5700 How ToDocument10 pagesHuawei Switch S5700 How ToJeanNo ratings yet
- EHT For Athletes For Brain HealthDocument2 pagesEHT For Athletes For Brain HealthTracey Jorg RollisonNo ratings yet
- A Study On Consumer Buying Behaviour Towards ColgateDocument15 pagesA Study On Consumer Buying Behaviour Towards Colgatebbhaya427No ratings yet
- Business Law & TaxationDocument3 pagesBusiness Law & TaxationD J Ben UzeeNo ratings yet
- BSHM 23 ReviewerDocument8 pagesBSHM 23 ReviewerTrixie Mae MuncadaNo ratings yet
- Online JournalismDocument24 pagesOnline JournalismZandra Kate NerNo ratings yet
- An IDEAL FLOW Has A Non-Zero Tangential Velocity at A Solid SurfaceDocument46 pagesAn IDEAL FLOW Has A Non-Zero Tangential Velocity at A Solid SurfaceJayant SisodiaNo ratings yet
- Lab 1 Boys CalorimeterDocument11 pagesLab 1 Boys CalorimeterHafizszul Feyzul100% (1)
- Explosive Loading of Engineering Structures PDFDocument2 pagesExplosive Loading of Engineering Structures PDFBillNo ratings yet
- Kina23744ens 002-Seisracks1Document147 pagesKina23744ens 002-Seisracks1Adrian_Condrea_4281No ratings yet
- Going to the cinema listening practiceDocument2 pagesGoing to the cinema listening practiceMichael DÍligo Libre100% (1)
- Adjective: the girl is beautifulDocument15 pagesAdjective: the girl is beautifulIn'am TraboulsiNo ratings yet
- Introduction To Machine Learning Top-Down Approach - Towards Data ScienceDocument6 pagesIntroduction To Machine Learning Top-Down Approach - Towards Data ScienceKashaf BakaliNo ratings yet
- De Thi Thu Tuyen Sinh Lop 10 Mon Anh Ha Noi Nam 2022 So 2Document6 pagesDe Thi Thu Tuyen Sinh Lop 10 Mon Anh Ha Noi Nam 2022 So 2Ngọc LinhNo ratings yet
- Megneto TherapyDocument15 pagesMegneto TherapyedcanalNo ratings yet
- 3.6 God Provides Water and Food MaryDocument22 pages3.6 God Provides Water and Food MaryHadassa ArzagaNo ratings yet
- Mod. 34 Classic Compact T06Document4 pagesMod. 34 Classic Compact T06Jaime Li AliNo ratings yet
- The Diffusion of Microfinance: An Extended Analysis & Replication ofDocument33 pagesThe Diffusion of Microfinance: An Extended Analysis & Replication ofNaman GovilNo ratings yet
- Dice Resume CV Narendhar ReddyDocument5 pagesDice Resume CV Narendhar ReddyjaniNo ratings yet
- M Audio bx10s Manuel Utilisateur en 27417Document8 pagesM Audio bx10s Manuel Utilisateur en 27417TokioNo ratings yet
- Electronic Throttle ControlDocument67 pagesElectronic Throttle Controlmkisa70100% (1)
- Nozzle F Factor CalculationsDocument5 pagesNozzle F Factor CalculationsSivateja NallamothuNo ratings yet
- Sss PDFDocument1 pageSss PDFROVI ROSE MAILOMNo ratings yet
- Viviana Rodriguez: Education The University of Texas at El Paso (UTEP)Document1 pageViviana Rodriguez: Education The University of Texas at El Paso (UTEP)api-340240168No ratings yet