You might also like
- Databases ModelDocument6 pagesDatabases Modelirshia9469No ratings yet
- Database Models: Hierarchical ModelDocument6 pagesDatabase Models: Hierarchical ModelVinothkumarNo ratings yet
- Hierarchical Model: Database ModelsDocument8 pagesHierarchical Model: Database Modelsmallireddy1234No ratings yet
- Database Models: Hierarchical ModelDocument6 pagesDatabase Models: Hierarchical ModeldipanshuhandooNo ratings yet
- Anurag: Ajay Himanshu Mayank PrabhatDocument32 pagesAnurag: Ajay Himanshu Mayank PrabhatPrabhat SinghNo ratings yet
- Types of Database ModelsDocument5 pagesTypes of Database ModelsRobell SamsonNo ratings yet
- Flat (Or Table) Model DataDocument6 pagesFlat (Or Table) Model DataJorge Romeo Rosal Jr.No ratings yet
- Data ModelsDocument5 pagesData Modelssammarmughal77No ratings yet
- Database Models Start n1Document17 pagesDatabase Models Start n1सुबास अधिकारीNo ratings yet
- Dbms PresentaionDocument11 pagesDbms PresentaionSandeep ChowdaryNo ratings yet
- A Database Model Shows The Logical Structure of A DatabaseDocument4 pagesA Database Model Shows The Logical Structure of A DatabaseFungai ChotoNo ratings yet
- Atm Database ManagementDocument36 pagesAtm Database Managementgoutham100% (1)
- Database ModelsDocument5 pagesDatabase ModelsJesmine GandhiNo ratings yet
- Chapter 2 Database System Concepts and ArchitectureDocument31 pagesChapter 2 Database System Concepts and Architectureputtaswamy123No ratings yet
- ModelDocument17 pagesModelkhushali16No ratings yet
- The Evolution of Database ModelingDocument11 pagesThe Evolution of Database Modelingraadr17No ratings yet
- Data Base ModelsDocument26 pagesData Base ModelsTony JacobNo ratings yet
- Data Base 1Document24 pagesData Base 1Kasun Sankalpa අමරසිංහNo ratings yet
- Database Models (Types of Databases)Document3 pagesDatabase Models (Types of Databases)jeunekaur0% (1)
- Hierarchical Model The Hierarchical Data Model Organizes Data in A Tree StructureDocument6 pagesHierarchical Model The Hierarchical Data Model Organizes Data in A Tree Structureshail_pariNo ratings yet
- Chapter 2 Database System Concepts and Architecture-23-.7-2018Document23 pagesChapter 2 Database System Concepts and Architecture-23-.7-2018puttaswamy123No ratings yet
- Cape Notes Unit 2 Module 1 Content 1 3Document12 pagesCape Notes Unit 2 Module 1 Content 1 3Drake Wells0% (1)
- DB Chapter Two NxdgixDocument18 pagesDB Chapter Two NxdgixMagarsa BedasaNo ratings yet
- Database Models: Presented by - Dheeraj Srinath 131GCMA035Document19 pagesDatabase Models: Presented by - Dheeraj Srinath 131GCMA035Dheeraj SrinathNo ratings yet
- DBMS ModelsDocument4 pagesDBMS ModelsAvinavNo ratings yet
- 2nd Chapter SlideDocument98 pages2nd Chapter SlideAjaya KapaliNo ratings yet
- Relational Data Model and SQL: Data Models Relational Database Concepts Introduction To DDL & DMLDocument49 pagesRelational Data Model and SQL: Data Models Relational Database Concepts Introduction To DDL & DMLPius VirtNo ratings yet
- SQL 2Document7 pagesSQL 2Vân Anh TrầnNo ratings yet
- Cape Notes Unit 2 Module 1 Content 1 3 2Document11 pagesCape Notes Unit 2 Module 1 Content 1 3 2Kxñg BùrtõñNo ratings yet
- Unit 2 - HandoutsDocument8 pagesUnit 2 - HandoutsShah zaibNo ratings yet
- ADBDocument6 pagesADBSuveetha SuviNo ratings yet
- DataModels SlidesDocument4 pagesDataModels SlidesXen ArfeenNo ratings yet
- European Database DirectiveDocument13 pagesEuropean Database DirectiveManish SahuNo ratings yet
- 1st Chap Data ModelsDocument47 pages1st Chap Data ModelsGuru DarshanNo ratings yet
- Cape Notes Unit 2 Module 1 Content 1 3Document12 pagesCape Notes Unit 2 Module 1 Content 1 3Pauline WaltersNo ratings yet
- The Relational Database ModelDocument3 pagesThe Relational Database ModelSeavus AcceleratorNo ratings yet
- APDIS107 Lecture 3Document3 pagesAPDIS107 Lecture 3Aileen P. de LeonNo ratings yet
- DBT 3Document21 pagesDBT 3idris_ali_7No ratings yet
- Advanced DatabaseDocument29 pagesAdvanced Databasesuplexcity656No ratings yet
- تانايبلا دعاوق يلا لخ دم 111 لاح - 3 Chapter 1 - Data ModelDocument5 pagesتانايبلا دعاوق يلا لخ دم 111 لاح - 3 Chapter 1 - Data ModelHumera GullNo ratings yet
- Data Model Tree: Relational Model Organizes Data Into One or MoreDocument1 pageData Model Tree: Relational Model Organizes Data Into One or MoreBenjamin AmponNo ratings yet
- Institutional Training Final ReportDocument27 pagesInstitutional Training Final ReportAkanksha SinghNo ratings yet
- Mod 6 PDFDocument9 pagesMod 6 PDFNaveen ShettyNo ratings yet
- TypesDocument2 pagesTypessusvi85No ratings yet
- Data Models: What Is A Model?Document5 pagesData Models: What Is A Model?Anas KhurshidNo ratings yet
- Data ModelingDocument61 pagesData ModelingSamiksha SainiNo ratings yet
- Assignment 01 (Data Models)Document6 pagesAssignment 01 (Data Models)Zain AbbasNo ratings yet
- Database Models: (GROUP 5 (R2) 1-50)Document21 pagesDatabase Models: (GROUP 5 (R2) 1-50)Amadi ChinasaokwuNo ratings yet
- Database 2nd SemesterDocument18 pagesDatabase 2nd SemesterEngr RakNo ratings yet
- Database Systems and Big DataDocument5 pagesDatabase Systems and Big DataMadilaine Claire NaciancenoNo ratings yet
- Data Models: Entity Relationship Data ModelDocument3 pagesData Models: Entity Relationship Data ModelAsfand Yar AliNo ratings yet
- Hierarchical ModelDocument4 pagesHierarchical ModelhasandalalNo ratings yet
- CH - 2 - Fundamentals of A Database SystemDocument19 pagesCH - 2 - Fundamentals of A Database Systemabrehamcs65No ratings yet
- Gis Spatial AnalysisDocument56 pagesGis Spatial AnalysissainathNo ratings yet
- Evolution of DBMSDocument3 pagesEvolution of DBMSAhitha RajNo ratings yet
- Chapter 2 - Database System Model and ArchitectureDocument22 pagesChapter 2 - Database System Model and ArchitecturesfdNo ratings yet
- Database Management System (Data Modelling) Answer Key - Activity 2Document17 pagesDatabase Management System (Data Modelling) Answer Key - Activity 2AJ Dela CruzNo ratings yet
- View of DataDocument4 pagesView of DataLakshmi LakshminarayanaNo ratings yet
- Lesson2 Database ModelsDocument15 pagesLesson2 Database ModelsSamuel NdiranguNo ratings yet
- Nigerian Law School Medical Centre Bwari-Abuja Hqs Lagos, Enugu, Kano, Yenegoa and Yola Campuses Student'S Personal DataDocument2 pagesNigerian Law School Medical Centre Bwari-Abuja Hqs Lagos, Enugu, Kano, Yenegoa and Yola Campuses Student'S Personal DataIroegbu Mang JohnNo ratings yet
- K9L6XQDocument4 pagesK9L6XQIroegbu Mang JohnNo ratings yet
- CorelDRAW Graphics Suite X6Document1 pageCorelDRAW Graphics Suite X6Iroegbu Mang JohnNo ratings yet
- Dev Fees 2015Document2 pagesDev Fees 2015Iroegbu Mang JohnNo ratings yet
- TimerDocument1 pageTimerIroegbu Mang JohnNo ratings yet
- PHP IntroductionDocument101 pagesPHP IntroductionIroegbu Mang JohnNo ratings yet
- Agent ContractDocument1 pageAgent ContractIroegbu Mang JohnNo ratings yet
- Public Holidays in NigeriaDocument1 pagePublic Holidays in NigeriaIroegbu Mang JohnNo ratings yet
- Consulting AgreementDocument1 pageConsulting AgreementIroegbu Mang JohnNo ratings yet
- Spyglass DFTDocument3 pagesSpyglass DFTBharathi MahadevacharNo ratings yet
- Verilog Prep MaterialDocument11 pagesVerilog Prep MaterialSangeetha BajanthriNo ratings yet
- Asa Ldap AuthenticationDocument9 pagesAsa Ldap Authenticationj_benz44No ratings yet
- Mark 46 MDLDocument10 pagesMark 46 MDLАртур КонстантиновNo ratings yet
- Haptic TechnologyDocument13 pagesHaptic TechnologyBandaru Purna0% (1)
- 2233Document12 pages2233thulasiramvNo ratings yet
- CS2102 Database Systems 2Document2 pagesCS2102 Database Systems 2Weichen Christopher XuNo ratings yet
- Com 5502 SoftDocument17 pagesCom 5502 SoftComBlockNo ratings yet
- 2018 Book AdvancesInSoftComputing PDFDocument454 pages2018 Book AdvancesInSoftComputing PDFIsmael ChinarroNo ratings yet
- Documentation of Women Security AppDocument48 pagesDocumentation of Women Security AppBabuHalderNo ratings yet
- Content Server 53 API RefDocument554 pagesContent Server 53 API RefGraham EwingsNo ratings yet
- DAA UNIT 1 - FinalDocument38 pagesDAA UNIT 1 - FinalkarthickamsecNo ratings yet
- SBI Specialist Officer Computer and Communication Exam 2012 Question PaperDocument8 pagesSBI Specialist Officer Computer and Communication Exam 2012 Question PaperhinaavermaNo ratings yet
- Sap 1Document21 pagesSap 1Ramu AryanNo ratings yet
- Fluent MDM 16.0 WS06 RemeshingDocument28 pagesFluent MDM 16.0 WS06 RemeshingHahaNo ratings yet
- System HookingDocument17 pagesSystem HookingdomeleuNo ratings yet
- Manual Update Mmi 3g v1 7aDocument47 pagesManual Update Mmi 3g v1 7aИлия МариновNo ratings yet
- Apa Itu Capacity ManagementDocument5 pagesApa Itu Capacity ManagementvictorNo ratings yet
- Jeevan Pranaam - DLCDocument13 pagesJeevan Pranaam - DLCLAKSHMANARAO PNo ratings yet
- DB2 Query Monitor User's Guide PDFDocument70 pagesDB2 Query Monitor User's Guide PDFvishal_bvpNo ratings yet
- A Report On Introduction To Computer SystemsDocument6 pagesA Report On Introduction To Computer Systemschaulagainajeet50% (4)
- Nutanix CompetitiveDocument151 pagesNutanix CompetitiveZainoorNo ratings yet
- Dataram RAMDisk Users ManualDocument20 pagesDataram RAMDisk Users ManualBabis ArbiliosNo ratings yet
- CODESYS Runtime enDocument16 pagesCODESYS Runtime enAbdelali KhalilNo ratings yet
- dbms2 1Document5 pagesdbms2 1thess22No ratings yet
- SyllabusDocument2 pagesSyllabusnsavi16eduNo ratings yet
- JTAG TAP ControllerDocument5 pagesJTAG TAP ControllerTanmayKabra100% (1)
- User Manual FPRA G02Document57 pagesUser Manual FPRA G02Ivan StanojevicNo ratings yet
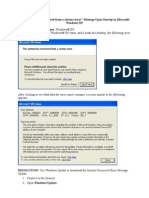
- The System Has Recovered From A Serious ErrorDocument3 pagesThe System Has Recovered From A Serious Errorpuji_ascNo ratings yet