You might also like
- Data MiningDocument31 pagesData MiningASHA MAHININo ratings yet
- Sri Venkateswara Engineering CollegeDocument15 pagesSri Venkateswara Engineering Collegeapi-19799369No ratings yet
- Motivation For Data Mining The Information CrisisDocument13 pagesMotivation For Data Mining The Information Crisisriddickdanish1No ratings yet
- Data Mining PresentationDocument25 pagesData Mining Presentationmanas1991No ratings yet
- Chapter 1 Data Mining Lecture NoteDocument31 pagesChapter 1 Data Mining Lecture NotenaolNo ratings yet
- Unit II Data MiningDocument8 pagesUnit II Data MiningAjit RautNo ratings yet
- Ch5 DWDM-1Document14 pagesCh5 DWDM-1uttamraoNo ratings yet
- Datamining With Big Data - SivaDocument69 pagesDatamining With Big Data - SivaVenkatesh GardasNo ratings yet
- Data Mining Tools and ApplicationsDocument5 pagesData Mining Tools and ApplicationsAnkit ChourasiaNo ratings yet
- What Is Data MiningDocument8 pagesWhat Is Data MiningAmran AnwarNo ratings yet
- Course Recommender System Aims at Predicting The Best Combination of Courses Selected by Students-1Document29 pagesCourse Recommender System Aims at Predicting The Best Combination of Courses Selected by Students-1ShivaniNo ratings yet
- Discuss The Role of Data Mining Techniques and Data Visualization in e Commerce Data MiningDocument13 pagesDiscuss The Role of Data Mining Techniques and Data Visualization in e Commerce Data MiningPrema SNo ratings yet
- Unit 1Document27 pagesUnit 1bhavanabhoomika1234No ratings yet
- What Is Data MiningDocument8 pagesWhat Is Data MiningJignesh SoniNo ratings yet
- Data Mining ConceptsDocument122 pagesData Mining ConceptsGiri Saranu100% (3)
- Data Mining: What Is Data Mining?: Correlations or Patterns Among Fields in Large Relational DatabasesDocument6 pagesData Mining: What Is Data Mining?: Correlations or Patterns Among Fields in Large Relational DatabasesAnonymous wfUYLhYZtNo ratings yet
- Notes DATA MINING MBA IIIDocument8 pagesNotes DATA MINING MBA IIIMani BhagatNo ratings yet
- Data MiningDocument8 pagesData MiningAparna AparnaNo ratings yet
- Data MiningDocument89 pagesData MiningMarufNo ratings yet
- Data MiningDocument14 pagesData MiningutkarshNo ratings yet
- 4 DataminingDocument90 pages4 DataminingironchefffNo ratings yet
- Data Mining1Document37 pagesData Mining1MarufNo ratings yet
- What Is Data MiningDocument5 pagesWhat Is Data MiningGustavo AlvesNo ratings yet
- IT Unit 4Document7 pagesIT Unit 4ShreestiNo ratings yet
- Bana1 VisualizationDocument22 pagesBana1 VisualizationSan Juan, Ma. Lourdes D.No ratings yet
- Data Mining: Concepts and TechniquesDocument46 pagesData Mining: Concepts and TechniquesVinamra MittalNo ratings yet
- Navigating Big Data Analytics: Strategies for the Quality Systems AnalystFrom EverandNavigating Big Data Analytics: Strategies for the Quality Systems AnalystNo ratings yet
- Unit 4 New Database Applications and Environments: by Bhupendra Singh SaudDocument14 pagesUnit 4 New Database Applications and Environments: by Bhupendra Singh SaudAnoo ShresthaNo ratings yet
- Data Mining TutorialDocument30 pagesData Mining TutorialNitish SolankiNo ratings yet
- Data Mining:: Dr. Hany SaleebDocument37 pagesData Mining:: Dr. Hany SaleebDeepthi PrasadNo ratings yet
- 1.1what Is Data Mining?: GallopDocument64 pages1.1what Is Data Mining?: GallopNelli HarshithaNo ratings yet
- Chapter 6 Data MiningDocument39 pagesChapter 6 Data MiningJiawei TanNo ratings yet
- Data Mining Process Week3Document13 pagesData Mining Process Week34xpgw58j2hNo ratings yet
- Data Mining NotesDocument45 pagesData Mining Notessbr11100% (1)
- Data Mining - PrashantDocument10 pagesData Mining - PrashantKunal KubalNo ratings yet
- Data Science: What the Best Data Scientists Know About Data Analytics, Data Mining, Statistics, Machine Learning, and Big Data – That You Don'tFrom EverandData Science: What the Best Data Scientists Know About Data Analytics, Data Mining, Statistics, Machine Learning, and Big Data – That You Don'tRating: 5 out of 5 stars5/5 (1)
- Major Issues in Data MiningDocument45 pagesMajor Issues in Data MiningProsper Muzenda75% (4)
- Data Mining Concepts and Applications: Six Factors Behind The Sudden Rise in Popularity of Data MiningDocument36 pagesData Mining Concepts and Applications: Six Factors Behind The Sudden Rise in Popularity of Data MiningOngudi TiberiusNo ratings yet
- 1 IntroDocument33 pages1 IntroFe Unlayao LarwaNo ratings yet
- Discussion Questions BADocument11 pagesDiscussion Questions BAsanjay.diddeeNo ratings yet
- Data Mining and Data Profiling - Nargis Hamid MonamiDocument7 pagesData Mining and Data Profiling - Nargis Hamid MonamiNargis Hamid MonamiNo ratings yet
- DMOverviewDocument25 pagesDMOverviewSyed Hasib1971 AbdullahNo ratings yet
- Introduction To Data Mining: Dr. Hany SaleebDocument17 pagesIntroduction To Data Mining: Dr. Hany SaleebNaheed NajamNo ratings yet
- Data Mining For Customer Relationship ManagementDocument10 pagesData Mining For Customer Relationship ManagementAlti AdelNo ratings yet
- A Techinical Paper: Tupimakadia1@yahoo - Co.in Yamu - 4u1985@yahoo - Co.inDocument14 pagesA Techinical Paper: Tupimakadia1@yahoo - Co.in Yamu - 4u1985@yahoo - Co.insur8742No ratings yet
- Data Mining: Knowledge Discovery in DatabasesDocument21 pagesData Mining: Knowledge Discovery in DatabasesLavanya RatalaNo ratings yet
- How To Create New Business Models With Big Data & Analytics: Aki Balogh Calpont CorporationDocument25 pagesHow To Create New Business Models With Big Data & Analytics: Aki Balogh Calpont CorporationArdy NugrohoNo ratings yet
- Unit I - Big Data ProgrammingDocument19 pagesUnit I - Big Data ProgrammingjasmineNo ratings yet
- UNIT - 3 Data Mining PTDocument19 pagesUNIT - 3 Data Mining PTnehakncbcips1990No ratings yet
- Data Mining AND Warehousing: AbstractDocument12 pagesData Mining AND Warehousing: AbstractSanthosh AnuhyaNo ratings yet
- 01 Unit1Document13 pages01 Unit1Sridhar KumarNo ratings yet
- Data Mining and Data WarehousingDocument13 pagesData Mining and Data WarehousingKattineni ChaitanyaNo ratings yet
- Data MiningDocument4 pagesData Miningarpitarajput4213No ratings yet
- Chapter 1Document35 pagesChapter 1Ipsita PriyadarshiniNo ratings yet
- Data Mining: by Doug AlexanderDocument6 pagesData Mining: by Doug AlexanderVictoria ZúñigaNo ratings yet
- SuniDocument104 pagesSunisaitejNo ratings yet
- Data MiningDocument4 pagesData MiningVivek GuptaNo ratings yet
- Meal Card Directory - 24.04.2018Document1,803 pagesMeal Card Directory - 24.04.2018fecaxeyivuNo ratings yet
- Icici Bank Business Overview: Kunal Gandhi 5kunalg 6175Document2 pagesIcici Bank Business Overview: Kunal Gandhi 5kunalg 6175fecaxeyivuNo ratings yet
- Tripmate PresskitDocument10 pagesTripmate PresskitfecaxeyivuNo ratings yet
- ITS - Functions Covered v1Document20 pagesITS - Functions Covered v1fecaxeyivuNo ratings yet
- Corporate Finance Career Overview PDFDocument7 pagesCorporate Finance Career Overview PDFfecaxeyivuNo ratings yet
- PsychomotorDocument36 pagesPsychomotorfecaxeyivu100% (1)
- Indian BankingDocument23 pagesIndian BankingfecaxeyivuNo ratings yet
- Indian Banking Industry: An AnalysisDocument30 pagesIndian Banking Industry: An AnalysisfecaxeyivuNo ratings yet
- 193 IciciDocument2 pages193 IcicifecaxeyivuNo ratings yet
- Competitor AnalysisDocument5 pagesCompetitor AnalysisfecaxeyivuNo ratings yet
- FDI & FII: A Balanced Perspective: by Rohit Anand Garg Abhishek MukherjeeDocument15 pagesFDI & FII: A Balanced Perspective: by Rohit Anand Garg Abhishek MukherjeefecaxeyivuNo ratings yet
- Palett Prize II RevisedDocument1 pagePalett Prize II RevisedfecaxeyivuNo ratings yet
- BondsDocument55 pagesBondsfecaxeyivuNo ratings yet
- MM 2Document2 pagesMM 2fecaxeyivuNo ratings yet
- Japanese 5 S ApproachDocument30 pagesJapanese 5 S ApproachfecaxeyivuNo ratings yet
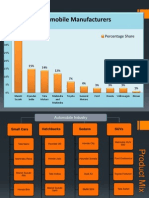
- Automobile Manufacturers: Percentage ShareDocument4 pagesAutomobile Manufacturers: Percentage SharefecaxeyivuNo ratings yet
- Parachute Advansed Summer Fresh Body LotionDocument18 pagesParachute Advansed Summer Fresh Body LotionfecaxeyivuNo ratings yet
- KaizenDocument13 pagesKaizenfecaxeyivuNo ratings yet
- Parachute Summer Fresh Bajaj Ke Bande JbimsDocument25 pagesParachute Summer Fresh Bajaj Ke Bande JbimsfecaxeyivuNo ratings yet
- Indian Railways - Rebranding by FMSDocument31 pagesIndian Railways - Rebranding by FMSfecaxeyivuNo ratings yet
- Social Justice in The Age of Identity PoliticsDocument68 pagesSocial Justice in The Age of Identity PoliticsAndrea AlvarezNo ratings yet
- BCG Most Innovative Companies Mar 2019 R2 - tcm38 215836 PDFDocument22 pagesBCG Most Innovative Companies Mar 2019 R2 - tcm38 215836 PDFAbhinav SrivastavaNo ratings yet
- Soal Bahasa Inggris Semerter VI (Genap) 2020Document5 pagesSoal Bahasa Inggris Semerter VI (Genap) 2020FabiolaIvonyNo ratings yet
- Temperature Performance Study-SilviaDocument11 pagesTemperature Performance Study-SilviadalheimerNo ratings yet
- Risen 300-350 WP MonoDocument2 pagesRisen 300-350 WP MonoAgoesPermanaNo ratings yet
- Research On The Jackson Personality Inventory Revised JPI R PDFDocument16 pagesResearch On The Jackson Personality Inventory Revised JPI R PDFAndrea RosalNo ratings yet
- (P1) Modul DC Motor Speed Control SystemDocument13 pages(P1) Modul DC Motor Speed Control SystemTito Bambang Priambodo - 6726No ratings yet
- SupplyPower Overview Presentation SuppliersDocument20 pagesSupplyPower Overview Presentation SuppliersCarlos CarranzaNo ratings yet
- Dividend PolicyDocument26 pagesDividend PolicyAnup Verma100% (1)
- Menguito Vs Republic DigestDocument1 pageMenguito Vs Republic DigestRyan AcostaNo ratings yet
- Itron Meter Data Management With MicrosoftDocument4 pagesItron Meter Data Management With MicrosoftBernardo Mendez-aristaNo ratings yet
- Case StudyDocument10 pagesCase StudyJessica FolleroNo ratings yet
- 747-400F Specifications - Atlas AirDocument1 page747-400F Specifications - Atlas AirRoel PlmrsNo ratings yet
- MachXO2 Lattice Semiconductor ManualDocument23 pagesMachXO2 Lattice Semiconductor ManualAdrian Hdz VegaNo ratings yet
- 5 Quick Guide ACI 212.3 PRAN Vs PRAH CHPT 15 Explained 2pgsDocument2 pages5 Quick Guide ACI 212.3 PRAN Vs PRAH CHPT 15 Explained 2pgsOvenbird Ingeniaria AvanzadaNo ratings yet
- Principles of Management ImportanceDocument2 pagesPrinciples of Management ImportanceT S Kumar KumarNo ratings yet
- Facebook Addiction Chapter1Document22 pagesFacebook Addiction Chapter1Catherine BenbanNo ratings yet
- Bakri Balloon PDFDocument5 pagesBakri Balloon PDFNoraNo ratings yet
- Ballsim DirectDocument58 pagesBallsim DirectDiego GaliciaNo ratings yet
- Gold Prospecting in OhioDocument2 pagesGold Prospecting in OhioJannette FerreriaNo ratings yet
- Paul M.C. (Ed.) - Fiber Laser PDFDocument415 pagesPaul M.C. (Ed.) - Fiber Laser PDFXuan Phuong Huynh100% (1)
- Bugreport 2022 01 04 15 15 29 Dumpstate - Log 29625Document3 pagesBugreport 2022 01 04 15 15 29 Dumpstate - Log 29625Yorman Ruiz AcstaNo ratings yet
- Syllabus Income TaxationDocument10 pagesSyllabus Income TaxationValery Joy CerenadoNo ratings yet
- IX Chem Mole Concept Kailash Khatwani FinalDocument8 pagesIX Chem Mole Concept Kailash Khatwani FinalAditya ParuiNo ratings yet
- HSE Program 2017 - FinalDocument12 pagesHSE Program 2017 - FinalAbdul Hamid Tasra100% (2)
- Maven - Download Apache MavenDocument1 pageMaven - Download Apache Mavenjuanc_faundezNo ratings yet
- Nano ProgrammingDocument3 pagesNano ProgrammingBhavani DhanasekaranNo ratings yet
- Autodesk 2015 Products Direct Download LinksDocument2 pagesAutodesk 2015 Products Direct Download LinksALEXNo ratings yet
- Narrative Report de ChavezDocument48 pagesNarrative Report de ChavezGerald De ChavezNo ratings yet
- Bribery and Corruption Plague Middle EastDocument2 pagesBribery and Corruption Plague Middle EastKhaled HaddadNo ratings yet