You might also like
- SAP Foreign Currency Revaluation: FAS 52 and GAAP RequirementsFrom EverandSAP Foreign Currency Revaluation: FAS 52 and GAAP RequirementsNo ratings yet
- Implementing Integrated Business Planning: A Guide Exemplified With Process Context and SAP IBP Use CasesFrom EverandImplementing Integrated Business Planning: A Guide Exemplified With Process Context and SAP IBP Use CasesNo ratings yet
- 5 StrategiesDocument11 pages5 StrategiesKathrine CruzNo ratings yet
- SAP IS RETAIL OverviewDocument17 pagesSAP IS RETAIL OverviewKumarragamNo ratings yet
- Install GUI Pilih SetupallDocument6 pagesInstall GUI Pilih SetupallAllan SastrawanNo ratings yet
- 10 Reason Why SAPDocument13 pages10 Reason Why SAPunlucky10No ratings yet
- Stationary Procurement & Inventory ProcessDocument11 pagesStationary Procurement & Inventory ProcessSourav Ghosh DastidarNo ratings yet
- Dawood Khalid: SAP FM and CO (Certified) ConsultantDocument3 pagesDawood Khalid: SAP FM and CO (Certified) ConsultantRaza_Kashif_1713No ratings yet
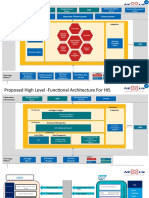
- Staff Rostering System Dietary System Operation Theater SystemDocument5 pagesStaff Rostering System Dietary System Operation Theater SystemBhaskar Biswas100% (1)
- Shift Order Indicator-OPU3Document9 pagesShift Order Indicator-OPU3Bhaskar BiswasNo ratings yet
- Oil and Gas Training TSWDocument59 pagesOil and Gas Training TSWmohannaiduramNo ratings yet
- CO24-Missing Parts Info System-Ecc6 PDFDocument11 pagesCO24-Missing Parts Info System-Ecc6 PDFBhaskar BiswasNo ratings yet
- COGI-Correcting Failed Goods Movementduring Backflush-Ecc6Document8 pagesCOGI-Correcting Failed Goods Movementduring Backflush-Ecc6Bhaskar BiswasNo ratings yet
- General Ledger ReportsDocument16 pagesGeneral Ledger ReportsNive AdmiresNo ratings yet
- CO 9KE5 JPN Change Statistical Key FiguresDocument18 pagesCO 9KE5 JPN Change Statistical Key FiguresnguyencaohuyNo ratings yet
- 0 DTE MEIC - January 16, 2023 by Tammy ChamblessDocument19 pages0 DTE MEIC - January 16, 2023 by Tammy Chamblessben44No ratings yet
- HTTPS://WWW Scribd com/document/346214992/Tcodes-List-S4HANADocument21 pagesHTTPS://WWW Scribd com/document/346214992/Tcodes-List-S4HANAAnonymous LwDMNdNo ratings yet
- How To Set Up Inter Company Stock Transfer PDFDocument13 pagesHow To Set Up Inter Company Stock Transfer PDFUfuk DoğanNo ratings yet
- A Project Report ON Derivatives: Submitted ToDocument34 pagesA Project Report ON Derivatives: Submitted ToAnu PillaiNo ratings yet
- Indicator Library: How To Win in The Stock MarketDocument11 pagesIndicator Library: How To Win in The Stock MarketPeter FrankNo ratings yet
- Information Technology Director Program Project Manager in Milwaukee WI Resume James KurzDocument2 pagesInformation Technology Director Program Project Manager in Milwaukee WI Resume James KurzJamesKurzNo ratings yet
- End To End S4 Use CaseDocument5 pagesEnd To End S4 Use CaseKaran ChopraNo ratings yet
- XYZ Co Ltd Risk Matrix ReviewDocument42 pagesXYZ Co Ltd Risk Matrix ReviewAnupam BaliNo ratings yet
- Cost Element Part 2 Secondary Cost ElementDocument12 pagesCost Element Part 2 Secondary Cost ElementNASEER ULLAHNo ratings yet
- Make-To-Stock Strategies - Strategy 10Document14 pagesMake-To-Stock Strategies - Strategy 10Chaitanya MNo ratings yet
- Valuation VariantDocument4 pagesValuation Variantsrinivas50895No ratings yet
- I DocsDocument22 pagesI DocssirajsamadNo ratings yet
- Detailed SAP Interface Design Fundamental DocumentDocument4 pagesDetailed SAP Interface Design Fundamental Documentamitava_bapiNo ratings yet
- Error FS 861 in External Tax System - SAP BlogsDocument7 pagesError FS 861 in External Tax System - SAP BlogsbirojivenkatNo ratings yet
- GR&IR Clearing AccountDocument8 pagesGR&IR Clearing AccountWupankNo ratings yet
- DCF Optimize demand planningDocument2 pagesDCF Optimize demand planningDharmendra KumarNo ratings yet
- Day 1Document3 pagesDay 1Sudhanshu MalandkarNo ratings yet
- Retention: PurposeDocument7 pagesRetention: PurposeSagnik ChakravartyNo ratings yet
- Configuration Document IFRS 16Document213 pagesConfiguration Document IFRS 16Anshuman Yadav0% (1)
- Presales Management (41V - US) : Test Script SAP S/4HANA - 30-08-19Document25 pagesPresales Management (41V - US) : Test Script SAP S/4HANA - 30-08-19Mahamed HassenNo ratings yet
- Vertex Indirect Tax Accelerator For SAP Activation Guide PDFDocument24 pagesVertex Indirect Tax Accelerator For SAP Activation Guide PDFOsvaldo FerreiraNo ratings yet
- Attachment Transfer From ECC PR To SRMDocument15 pagesAttachment Transfer From ECC PR To SRMBalaji HariharanNo ratings yet
- Transaction Based Pricing - Nirvana For FAODocument0 pagesTransaction Based Pricing - Nirvana For FAOvijayhegdeNo ratings yet
- SD OverviewDocument85 pagesSD OverviewSamatha GantaNo ratings yet
- RTP PrcoessDocument3 pagesRTP PrcoessIshan AgrawalNo ratings yet
- Display A List of POs With Outstanding GR or IRDocument6 pagesDisplay A List of POs With Outstanding GR or IRchonchalNo ratings yet
- Configure Tax Collected at Source in SAPDocument12 pagesConfigure Tax Collected at Source in SAPsekhar dattaNo ratings yet
- Results Analysis IAS EDocument22 pagesResults Analysis IAS Efazal509acd100% (1)
- VimtapptDocument40 pagesVimtapptSaroshNo ratings yet
- Link Sales Orders and Purchase RequisitionsDocument3 pagesLink Sales Orders and Purchase RequisitionsHariKrishnan PrabhakharenNo ratings yet
- COST CENTER ASSET RETIREMENTSDocument3 pagesCOST CENTER ASSET RETIREMENTSrajdeeppawarNo ratings yet
- How To Replicate Condition Records For Pricing To External System From SAPDocument12 pagesHow To Replicate Condition Records For Pricing To External System From SAParunakumarbiswalNo ratings yet
- Accounts PayableDocument33 pagesAccounts Payablesurendra singh kushwahaNo ratings yet
- ODP Data Replication API NotesDocument4 pagesODP Data Replication API NotesRobertJindaNo ratings yet
- FM-GM Troubleshooting TipsDocument37 pagesFM-GM Troubleshooting TipsBAble996No ratings yet
- Configuration Practices For Agentry Based Mobile ApplicationDocument44 pagesConfiguration Practices For Agentry Based Mobile ApplicationnandooNo ratings yet
- Sap Financial Supply Chain Management (FSCM) : System & Technology Model Finance SSC June 2019Document20 pagesSap Financial Supply Chain Management (FSCM) : System & Technology Model Finance SSC June 2019fadliNo ratings yet
- Sap Kirloskar Blue Print343411327053679Document85 pagesSap Kirloskar Blue Print343411327053679Rohan AnandNo ratings yet
- CRM IPM OverviewDocument104 pagesCRM IPM OverviewmkumarshahiNo ratings yet
- Fdocuments - in Sap Overview PP PC IntegrationDocument84 pagesFdocuments - in Sap Overview PP PC IntegrationHimanshu SinghNo ratings yet
- Presales ConsultantDocument2 pagesPresales Consultantakshita chhabra100% (1)
- Sap Fi GL Enduser Step by Step MaterialDocument99 pagesSap Fi GL Enduser Step by Step Materialsksk1911No ratings yet
- SAP TablesDocument25 pagesSAP TablesFercho Canul CentenoNo ratings yet
- Commodity FuturesDocument2 pagesCommodity Futuresyousuf264No ratings yet
- SAP S/4HANA Retail: Processes, Functions, CustomisingFrom EverandSAP S/4HANA Retail: Processes, Functions, CustomisingRating: 5 out of 5 stars5/5 (1)
- Perspective Management: Managing Your Career AssignmentDocument5 pagesPerspective Management: Managing Your Career AssignmentNikhilNo ratings yet
- Collated List of All BU 16th Oct 2019Document57 pagesCollated List of All BU 16th Oct 2019NikhilNo ratings yet
- Transaction ConfirmationDocument4 pagesTransaction ConfirmationNikhilNo ratings yet
- NokiaDocument9 pagesNokiaNikhil100% (1)
- Flight DocumentDocument2 pagesFlight DocumentNikhilNo ratings yet
- Asahi EvaDocument2 pagesAsahi EvaNikhilNo ratings yet
- Apriori CaseDocument1 pageApriori CaseNikhilNo ratings yet
- Anti Jamming of CdmaDocument10 pagesAnti Jamming of CdmaVishnupriya_Ma_4804No ratings yet
- Open Far CasesDocument8 pagesOpen Far CasesGDoony8553No ratings yet
- Inventory ControlDocument26 pagesInventory ControlhajarawNo ratings yet
- GS16 Gas Valve: With On-Board DriverDocument4 pagesGS16 Gas Valve: With On-Board DriverProcurement PardisanNo ratings yet
- Prasads Pine Perks - Gift CardsDocument10 pagesPrasads Pine Perks - Gift CardsSusanth Kumar100% (1)
- Nagina Cotton Mills Annual Report 2007Document44 pagesNagina Cotton Mills Annual Report 2007Sonia MukhtarNo ratings yet
- Inborn Errors of Metabolism in Infancy: A Guide To DiagnosisDocument11 pagesInborn Errors of Metabolism in Infancy: A Guide To DiagnosisEdu Diaperlover São PauloNo ratings yet
- Revision Worksheet - Matrices and DeterminantsDocument2 pagesRevision Worksheet - Matrices and DeterminantsAryaNo ratings yet
- Case Study IndieDocument6 pagesCase Study IndieDaniel YohannesNo ratings yet
- EC GATE 2017 Set I Key SolutionDocument21 pagesEC GATE 2017 Set I Key SolutionJeevan Sai MaddiNo ratings yet
- Consensus Building e Progettazione Partecipata - Marianella SclaviDocument7 pagesConsensus Building e Progettazione Partecipata - Marianella SclaviWilma MassuccoNo ratings yet
- Hipotension 6Document16 pagesHipotension 6arturo castilloNo ratings yet
- Dep 32.32.00.11-Custody Transfer Measurement Systems For LiquidDocument69 pagesDep 32.32.00.11-Custody Transfer Measurement Systems For LiquidDAYONo ratings yet
- Bad DayDocument3 pagesBad DayLink YouNo ratings yet
- Ecc Part 2Document25 pagesEcc Part 2Shivansh PundirNo ratings yet
- ERIKS Dynamic SealsDocument28 pagesERIKS Dynamic Sealsdd82ddNo ratings yet
- Alignment of Railway Track Nptel PDFDocument18 pagesAlignment of Railway Track Nptel PDFAshutosh MauryaNo ratings yet
- Big Joe Pds30-40Document198 pagesBig Joe Pds30-40mauro garciaNo ratings yet
- Committee History 50yearsDocument156 pagesCommittee History 50yearsd_maassNo ratings yet
- Checklist of Requirements For OIC-EW Licensure ExamDocument2 pagesChecklist of Requirements For OIC-EW Licensure Examjonesalvarezcastro60% (5)
- White Box Testing Techniques: Ratna SanyalDocument23 pagesWhite Box Testing Techniques: Ratna SanyalYogesh MundhraNo ratings yet
- Real Estate Broker ReviewerREBLEXDocument124 pagesReal Estate Broker ReviewerREBLEXMar100% (4)
- Efaverenz p1Document4 pagesEfaverenz p1Pragat KumarNo ratings yet
- Copula and Multivariate Dependencies: Eric MarsdenDocument48 pagesCopula and Multivariate Dependencies: Eric MarsdenJeampierr Jiménez CheroNo ratings yet
- What's Wrong With American Taiwan Policy: Andrew J. NathanDocument14 pagesWhat's Wrong With American Taiwan Policy: Andrew J. NathanWu GuifengNo ratings yet
- Endangered EcosystemDocument11 pagesEndangered EcosystemNur SyahirahNo ratings yet
- Consumers ' Usage and Adoption of E-Pharmacy in India: Mallika SrivastavaDocument16 pagesConsumers ' Usage and Adoption of E-Pharmacy in India: Mallika SrivastavaSundaravel ElangovanNo ratings yet
- Methods to estimate stakeholder views of sustainabilityDocument7 pagesMethods to estimate stakeholder views of sustainabilityAlireza FatemiNo ratings yet
- Easa Management System Assessment ToolDocument40 pagesEasa Management System Assessment ToolAdam Tudor-danielNo ratings yet