You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons the100% (1)
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Exhibit 1: Chapter 2 Analyzing TransactionsDocument1 pageExhibit 1: Chapter 2 Analyzing Transactionscons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Intro to accounting and PS Music caseDocument1 pageIntro to accounting and PS Music casecons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Problems Series B: InstructionsDocument1 pageProblems Series B: Instructionscons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Introduction to Accounting Chapter 1Document1 pageIntroduction to Accounting Chapter 1cons theNo ratings yet
- Wilderness Travel Service financial statementsDocument1 pageWilderness Travel Service financial statementscons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial Accounting PDFDocument1 pageFinancial and Managerial Accounting PDFcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial Accounting PDFDocument1 pageFinancial and Managerial Accounting PDFcons theNo ratings yet
- Financial and Managerial Accounting PDFDocument1 pageFinancial and Managerial Accounting PDFcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Introduction to Accounting EquationDocument1 pageIntroduction to Accounting Equationcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial Accounting PDFDocument1 pageFinancial and Managerial Accounting PDFcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Financial and Managerial AccountingDocument1 pageFinancial and Managerial Accountingcons theNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Limit Theorems: By: Ivan Sutresno Hadi SujotoDocument19 pagesLimit Theorems: By: Ivan Sutresno Hadi SujotoBagoes Budi LaksonoNo ratings yet
- SAT Math Workbook D1-12 PDFDocument157 pagesSAT Math Workbook D1-12 PDFADITYA SirohiNo ratings yet
- EE 802321 Name: 2 Semester 2018 Mid Exam ID: Time Limit: 60 Minutes SecDocument5 pagesEE 802321 Name: 2 Semester 2018 Mid Exam ID: Time Limit: 60 Minutes Secعبدالرحمن السعيطيNo ratings yet
- Here are the number of significant figures in each measurement:1. 3.005 g - 4SF2. 820 m - 3SF 3. 0.000 670 km - 4SF4. 0.405 021 kg - 7SF5. 22.4 L - 3SFDocument8 pagesHere are the number of significant figures in each measurement:1. 3.005 g - 4SF2. 820 m - 3SF 3. 0.000 670 km - 4SF4. 0.405 021 kg - 7SF5. 22.4 L - 3SFMark Christian Dimson Galang100% (1)
- Manula of Functional AnalysisDocument1 pageManula of Functional AnalysisGhulam Muhammad BismilNo ratings yet
- Lesson 8 - Implicit DifferentiationDocument3 pagesLesson 8 - Implicit DifferentiationLewis PharmaceuticalsNo ratings yet
- 456740Document13 pages456740Sukrit GhoraiNo ratings yet
- Math-3-Module-6 Definite IntegralsDocument4 pagesMath-3-Module-6 Definite IntegralsAne CalimagNo ratings yet
- Chemical Analysis2Document627 pagesChemical Analysis2Alimjan AblaNo ratings yet
- Ramanujan's Life and Achievements as a Groundbreaking MathematicianDocument12 pagesRamanujan's Life and Achievements as a Groundbreaking MathematicianibicengNo ratings yet
- Solution HW 3 Directional Derivatives and Extreme ValuesDocument6 pagesSolution HW 3 Directional Derivatives and Extreme ValuestooniiiNo ratings yet
- (Fdi)Document109 pages(Fdi)freak badNo ratings yet
- Principles Sampling TechniquesDocument2 pagesPrinciples Sampling Techniqueshania hanif100% (1)
- Pde CaracteristicasDocument26 pagesPde CaracteristicasAnonymous Vd26Pzpx80No ratings yet
- Teknomo, 2002Document141 pagesTeknomo, 2002Franz Chevarria BustamanteNo ratings yet
- BSBINS603 New 11Document22 pagesBSBINS603 New 11Samit ShresthaNo ratings yet
- Functions: Ecc 3001 Engineering Mathematics 1Document39 pagesFunctions: Ecc 3001 Engineering Mathematics 1nur hashimahNo ratings yet
- What Is Cost-Utility Analysis?: Supported by Sanofi-AventisDocument6 pagesWhat Is Cost-Utility Analysis?: Supported by Sanofi-Aventiscristi6923No ratings yet
- Function SpacesDocument15 pagesFunction SpacesGeorge ProtopapasNo ratings yet
- Grdient NotesDocument118 pagesGrdient Notessahlewel weldemichaelNo ratings yet
- Pert CPMDocument26 pagesPert CPMAnonymous pTZCrF7No ratings yet
- Z-Test of One-Sample MeanDocument16 pagesZ-Test of One-Sample MeanKurt AmihanNo ratings yet
- Bessel's Equation: Dr. Motilal Panigrahi Associate Professor, Nirma UniversityDocument29 pagesBessel's Equation: Dr. Motilal Panigrahi Associate Professor, Nirma UniversityDhiren PanditNo ratings yet
- Laplace Table PDFDocument2 pagesLaplace Table PDFOana NiculaescuNo ratings yet
- Calculus 2 - Tutorial 2Document5 pagesCalculus 2 - Tutorial 2Albert CofieNo ratings yet
- Interpret Titration CurvesDocument15 pagesInterpret Titration CurvesGhadeer M HassanNo ratings yet
- Module 6 (Maths)Document100 pagesModule 6 (Maths)Adabala Durgarao NaiduNo ratings yet
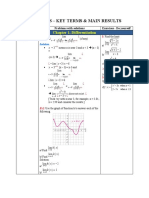
- Calculus - Key Terms & Main Results: Chapter 1. DifferentiationDocument21 pagesCalculus - Key Terms & Main Results: Chapter 1. DifferentiationLý Kim BiênNo ratings yet
- Week012-ANOVA: Laboratory Exercise 007Document3 pagesWeek012-ANOVA: Laboratory Exercise 007Michalcova Realisan JezzaNo ratings yet
- Practice - Questions - 2, System ScienceDocument3 pagesPractice - Questions - 2, System ScienceSONUNo ratings yet