You might also like
- Steps On Encode and DecodeDocument8 pagesSteps On Encode and DecodemathstopperNo ratings yet
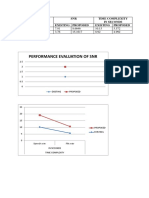
- Performance Calculation of SpeechDocument4 pagesPerformance Calculation of SpeechmathstopperNo ratings yet
- Block DiagramDocument1 pageBlock DiagrammathstopperNo ratings yet
- RoboticsDocument11 pagesRoboticsmathstopperNo ratings yet
- Generate Continuous Time Signals in MATLABDocument3 pagesGenerate Continuous Time Signals in MATLABmathstopperNo ratings yet
- System Requirements: Hardware RequirementsDocument1 pageSystem Requirements: Hardware RequirementsmathstopperNo ratings yet
- Block Diagram SangeethaDocument1 pageBlock Diagram SangeethamathstopperNo ratings yet
- Simulation Parameters SetupDocument1 pageSimulation Parameters SetupmathstopperNo ratings yet
- Brain Control Interface (BCI)Document9 pagesBrain Control Interface (BCI)mathstopperNo ratings yet
- U CardDocument9 pagesU CardmathstopperNo ratings yet
- Cell RecDocument14 pagesCell RecmathstopperNo ratings yet
- A Hybrid Reversible Data Hiding Schemes For EncryptedDocument39 pagesA Hybrid Reversible Data Hiding Schemes For EncryptedmathstopperNo ratings yet
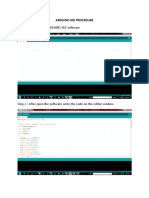
- Arduino Ide ProcedureDocument4 pagesArduino Ide ProceduremathstopperNo ratings yet
- AVR Atmega2560 Input Output PeripheralsDocument3 pagesAVR Atmega2560 Input Output PeripheralsmathstopperNo ratings yet
- SECURE MOBILE AD HOC NETWORK PROTOCOLDocument6 pagesSECURE MOBILE AD HOC NETWORK PROTOCOLmathstopperNo ratings yet
- A Scalable Approximate DCT Architecture For Efficient Hevc Compliant Video CodingDocument13 pagesA Scalable Approximate DCT Architecture For Efficient Hevc Compliant Video CodingvickyNo ratings yet
- A Hybrid Reversible Data Hiding Schemes For EncryptedDocument11 pagesA Hybrid Reversible Data Hiding Schemes For EncryptedmathstopperNo ratings yet
- Presentation 12Document13 pagesPresentation 12mathstopperNo ratings yet
- A Scalable Approximate DCT Architecture For Efficient Hevc Compliant Video CodingDocument13 pagesA Scalable Approximate DCT Architecture For Efficient Hevc Compliant Video CodingvickyNo ratings yet
- Rfid Tag and ReaderDocument4 pagesRfid Tag and ReadermathstopperNo ratings yet
- Conveyer ReportDocument31 pagesConveyer ReportmathstopperNo ratings yet
- Architecture DiagramDocument1 pageArchitecture DiagrammathstopperNo ratings yet
- Matlab Code To ExcelDocument1 pageMatlab Code To ExcelmathstopperNo ratings yet
- Self-Configurable RFID Children Tracking SystemDocument18 pagesSelf-Configurable RFID Children Tracking SystemmathstopperNo ratings yet
- Analysis of Intima Media Thickness in BDocument1 pageAnalysis of Intima Media Thickness in BmathstopperNo ratings yet
- Block Diagra12mDocument2 pagesBlock Diagra12mmathstopperNo ratings yet
- DCT 1Document10 pagesDCT 1mathstopperNo ratings yet
- Proposed Pt123Document9 pagesProposed Pt123mathstopperNo ratings yet
- An Introduction To Data MiningDocument11 pagesAn Introduction To Data MiningmathstopperNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5783)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Dellal ISMJ 2010 Physical and TechnicalDocument13 pagesDellal ISMJ 2010 Physical and TechnicalagustinbuscagliaNo ratings yet
- Job - RFP - Icheck Connect Beta TestingDocument10 pagesJob - RFP - Icheck Connect Beta TestingWaqar MemonNo ratings yet
- Behold The Lamb of GodDocument225 pagesBehold The Lamb of GodLinda Moss GormanNo ratings yet
- Assignment of English Spesialization Biography of B. J. HabibieDocument3 pagesAssignment of English Spesialization Biography of B. J. HabibieFikri FauzanNo ratings yet
- METACOGNITION MODULEDocument4 pagesMETACOGNITION MODULEViolet SilverNo ratings yet
- Quarter 4 English 3 DLL Week 1Document8 pagesQuarter 4 English 3 DLL Week 1Mary Rose P. RiveraNo ratings yet
- The Retired Adventurer - Six Cultures of PlayDocument14 pagesThe Retired Adventurer - Six Cultures of Playfernando_jesus_58No ratings yet
- List of ISRO-DRDO JobsDocument2 pagesList of ISRO-DRDO Jobsjobkey.inNo ratings yet
- Modern Physics - Chapter 27Document67 pagesModern Physics - Chapter 27Hamza PagaNo ratings yet
- Early Christian Reliquaries in The Republic of Macedonia - Snežana FilipovaDocument15 pagesEarly Christian Reliquaries in The Republic of Macedonia - Snežana FilipovaSonjce Marceva50% (2)
- A Complete Guide To Amazon For VendorsDocument43 pagesA Complete Guide To Amazon For Vendorsnissay99No ratings yet
- Getting More Effective: Branch Managers As ExecutivesDocument38 pagesGetting More Effective: Branch Managers As ExecutivesLubna SiddiqiNo ratings yet
- CONTINUOUS MECHANICAL HANDLING EQUIPMENT SAFETY CODEmoving parts, shall be fitted with interlocking deviceswhich prevent starting of the equipment when theseopenings are openDocument16 pagesCONTINUOUS MECHANICAL HANDLING EQUIPMENT SAFETY CODEmoving parts, shall be fitted with interlocking deviceswhich prevent starting of the equipment when theseopenings are openhoseinNo ratings yet
- Sales & Distribution Management Presentation NewDocument35 pagesSales & Distribution Management Presentation NewVivek Sinha0% (1)
- Bulletin 13.9.22Document4 pagesBulletin 13.9.22dbq088sNo ratings yet
- Underground Cable FaultDocument8 pagesUnderground Cable FaultMohammad IrfanNo ratings yet
- Acceleration vs. Time GraphDocument16 pagesAcceleration vs. Time Graphlea pagusaraNo ratings yet
- Peterbilt Essentials Module3 Sleepers PDFDocument6 pagesPeterbilt Essentials Module3 Sleepers PDFLuis Reinaldo Ramirez ContrerasNo ratings yet
- School Name Address Contact No. List of Formal Schools: WebsiteDocument8 pagesSchool Name Address Contact No. List of Formal Schools: WebsiteShravya NEMELAKANTINo ratings yet
- Malunggay cooking oil substituteDocument5 pagesMalunggay cooking oil substitutebaba112No ratings yet
- Astrolada - Astrology Elements in CompatibilityDocument6 pagesAstrolada - Astrology Elements in CompatibilitySilviaNo ratings yet
- Nipas Act, Ipra, LGC - Atty. Mayo-AndaDocument131 pagesNipas Act, Ipra, LGC - Atty. Mayo-AndaKing Bangngay100% (1)
- BSBINS603 - Self Study Guide v21.1Document10 pagesBSBINS603 - Self Study Guide v21.1Akshay Kumar TapariaNo ratings yet
- Sociology Viva NotesDocument4 pagesSociology Viva NotesTaniaNo ratings yet
- Bracing Connections To Rectangular Hss Columns: N. Kosteski and J.A. PackerDocument10 pagesBracing Connections To Rectangular Hss Columns: N. Kosteski and J.A. PackerJordy VertizNo ratings yet
- Motivation and Rewards StudyDocument6 pagesMotivation and Rewards StudyBea Dela CruzNo ratings yet
- (Ebook - PDF - Cisco Press) DNS, DHCP and IP Address ManagementDocument29 pages(Ebook - PDF - Cisco Press) DNS, DHCP and IP Address ManagementRachele AlbiottiNo ratings yet
- Using Accelerometers in A Data Acquisition SystemDocument10 pagesUsing Accelerometers in A Data Acquisition SystemueidaqNo ratings yet
- Preparedness of Interns For Hospital Practice Before and After An Orientation ProgrammeDocument6 pagesPreparedness of Interns For Hospital Practice Before and After An Orientation ProgrammeTanjir 247No ratings yet
- Essay 'Why Alice Remain Popular?'Document3 pagesEssay 'Why Alice Remain Popular?'Syamil AdzmanNo ratings yet