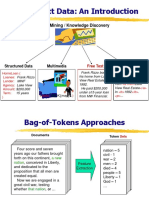
You might also like
- Lecture 6 Score - Term Weight - Vector Space ModelDocument43 pagesLecture 6 Score - Term Weight - Vector Space ModelPrateek SharmaNo ratings yet
- Introduction To: Information RetrievalDocument44 pagesIntroduction To: Information Retrievalnul loNo ratings yet
- Tf-Idf: David Kauchak cs160 Fall 2009Document51 pagesTf-Idf: David Kauchak cs160 Fall 2009Vishal YadavNo ratings yet
- Vector Space Model: TF - IDF: Adapted From Lectures byDocument37 pagesVector Space Model: TF - IDF: Adapted From Lectures byJati Hamengku GatiNo ratings yet
- Lecture6 TfidfDocument45 pagesLecture6 TfidfHamzaNo ratings yet
- Information Storage and RetrivalDocument31 pagesInformation Storage and RetrivalSudharsan LeonicNo ratings yet
- Introduction To: Information RetrievalDocument48 pagesIntroduction To: Information RetrievalTamizharasi ANo ratings yet
- Lecture8-Evaluation 2013Document44 pagesLecture8-Evaluation 2013HamzaNo ratings yet
- NLP Mod-V Q - A (Uploaded by Snaptricks - In)Document7 pagesNLP Mod-V Q - A (Uploaded by Snaptricks - In)sharan rajNo ratings yet
- 5 Retrieval EffectivenessDocument20 pages5 Retrieval Effectivenesshalal.army07No ratings yet
- IR Assigne 4Document8 pagesIR Assigne 4jewarNo ratings yet
- Ranked RetrievalDocument52 pagesRanked RetrievalInstall MacNo ratings yet
- Introduction To Information Retrieval: CourtesyDocument61 pagesIntroduction To Information Retrieval: CourtesyTamizharasi ANo ratings yet
- Question AnsweringDocument29 pagesQuestion AnsweringSV PRNo ratings yet
- Cs8080 Ir Unit2 I Modeling and Retrieval EvaluationDocument42 pagesCs8080 Ir Unit2 I Modeling and Retrieval EvaluationGnanasekaranNo ratings yet
- Introduction of IR ModelsDocument62 pagesIntroduction of IR ModelsMagarsa BedasaNo ratings yet
- IR - ch5 - Vector Space ModelDocument23 pagesIR - ch5 - Vector Space ModelBushra MamoudNo ratings yet
- Introduction To Information Retrieval: Jian-Yun Nie University of Montreal CanadaDocument61 pagesIntroduction To Information Retrieval: Jian-Yun Nie University of Montreal CanadaRicha MayankNo ratings yet
- Query and Document Expansion in Text Retrieval: Clara Isabel Cabezas University of Maryland College Park May, 2 2000Document37 pagesQuery and Document Expansion in Text Retrieval: Clara Isabel Cabezas University of Maryland College Park May, 2 2000shubhajit1234No ratings yet
- Tif Idf Cosine SimilarityDocument44 pagesTif Idf Cosine SimilarityVaibhav GargNo ratings yet
- Information Retrieval: Introduction ToDocument48 pagesInformation Retrieval: Introduction TomlhazanNo ratings yet
- 8.relavance Feedback - IIDocument52 pages8.relavance Feedback - IIRahul MehtaNo ratings yet
- Information RetrievalDocument72 pagesInformation RetrievalMathesh ParamasivamNo ratings yet
- Term WeightingDocument71 pagesTerm Weightingdawit wolduNo ratings yet
- 7 Query OperationsDocument19 pages7 Query OperationsSamuel KetemaNo ratings yet
- Relevance Ranking and Relevance Feedback: Carl StaelinDocument34 pagesRelevance Ranking and Relevance Feedback: Carl Staelinapi-20013624No ratings yet
- IRCh 7 SlidesDocument52 pagesIRCh 7 Slideswenhong zhuNo ratings yet
- Thesis Information RetrievalDocument8 pagesThesis Information RetrievalScientificPaperWritingServicesKansasCity100% (2)
- TF Idf AlgorithmDocument4 pagesTF Idf AlgorithmSharat DasikaNo ratings yet
- AI6122 Topic 3.2 - RankingDocument27 pagesAI6122 Topic 3.2 - RankingYujia TianNo ratings yet
- Preferential Infinitesimals For Information Retrieval: Maria Chowdhury Alex Thomo William WadgeDocument34 pagesPreferential Infinitesimals For Information Retrieval: Maria Chowdhury Alex Thomo William Wadgekhushi maheshwariNo ratings yet
- Modern Information Retrieval Chapter 7: Text Operations: Ricardo Baeza-Yates Berthier Ribeiro-NetoDocument40 pagesModern Information Retrieval Chapter 7: Text Operations: Ricardo Baeza-Yates Berthier Ribeiro-Netoapi-20013624No ratings yet
- Lecture10 Efficient ScoringDocument19 pagesLecture10 Efficient ScoringTamizharasi ANo ratings yet
- Lecture10 Efficient ScoringDocument19 pagesLecture10 Efficient Scoringwenhong zhuNo ratings yet
- Digital Libraries: Language TechnologiesDocument51 pagesDigital Libraries: Language TechnologiesAmit SwamiNo ratings yet
- CS583 Info RetrievalDocument33 pagesCS583 Info RetrievalMathesh ParamasivamNo ratings yet
- Lecture Notes For Algorithms For Data Science: 1 Nearest NeighborsDocument3 pagesLecture Notes For Algorithms For Data Science: 1 Nearest NeighborsLakshmiNarasimhan GNNo ratings yet
- Chap 3Document34 pagesChap 3kdineshbeNo ratings yet
- (IJIT-V6I3P1) :asst. Prof. Omprakash Yadav, Saikumar Kandakatla, Shantanu Sawant, Chandan Soni, Murari Indra BahadurDocument4 pages(IJIT-V6I3P1) :asst. Prof. Omprakash Yadav, Saikumar Kandakatla, Shantanu Sawant, Chandan Soni, Murari Indra BahadurIJITJournalsNo ratings yet
- IR Basics Lec28 Oct 3 2011Document26 pagesIR Basics Lec28 Oct 3 2011Mathesh ParamasivamNo ratings yet
- Index ConstructionDocument48 pagesIndex ConstructionAhmed AlesaNo ratings yet
- Introduction To: Information RetrievalDocument38 pagesIntroduction To: Information RetrievalBemenet BiniyamNo ratings yet
- Introduction To: Information RetrievalDocument60 pagesIntroduction To: Information RetrievalDeepa RajNo ratings yet
- Quiz IRW18 3A Answers PDFDocument2 pagesQuiz IRW18 3A Answers PDFMagarsa BedasaNo ratings yet
- Essential Dimensions of Latent Semantic IndexingDocument8 pagesEssential Dimensions of Latent Semantic IndexingverbrimanuelNo ratings yet
- Widc TfidfDocument20 pagesWidc Tfidfnyoman sNo ratings yet
- Text MiningDocument27 pagesText MiningAchyuth PentakotaNo ratings yet
- Dsbda2 Dsbda MergedDocument3 pagesDsbda2 Dsbda Mergedakshaydeolasi00eNo ratings yet
- Quiz IRS17 3A AnswersDocument2 pagesQuiz IRS17 3A AnswersJo73% (11)
- Automatic Indexing: Automatic Text Processing by G. Salton, Addison-Wesley, 1989Document65 pagesAutomatic Indexing: Automatic Text Processing by G. Salton, Addison-Wesley, 1989Ma NiNo ratings yet
- Testing Different Log Bases For Vector Model Weighting TechniqueDocument15 pagesTesting Different Log Bases For Vector Model Weighting TechniqueDarrenNo ratings yet
- IR - Set 1Document5 pagesIR - Set 1Bhavy SinghNo ratings yet
- CS583 Info RetrievalDocument34 pagesCS583 Info RetrievalRamu KakaNo ratings yet
- 6-Query LanguagesDocument19 pages6-Query LanguagesSamuel KetemaNo ratings yet
- Lecture15 Learning RankingDocument46 pagesLecture15 Learning RankingEdgar MartínezNo ratings yet
- Text Categorization Using Association Rule and Naïve Bayes ClassifierDocument9 pagesText Categorization Using Association Rule and Naïve Bayes ClassifierUnmesh PhalakNo ratings yet
- UNIT 4 Data MiningDocument11 pagesUNIT 4 Data MiningmahiNo ratings yet
- Unit-3 IrsDocument48 pagesUnit-3 Irsganeshjaggineni1927No ratings yet
- LogiComm Pattern ControlDocument2 pagesLogiComm Pattern ControlNordson Adhesive Dispensing SystemsNo ratings yet
- Analysis of Non-Uniform Torsion in Curved Incrementally Launched PDFDocument14 pagesAnalysis of Non-Uniform Torsion in Curved Incrementally Launched PDFYONAS GOSANo ratings yet
- Lecture 24 - Prestressed ConcreteDocument12 pagesLecture 24 - Prestressed ConcretejeovanNo ratings yet
- Chapter 17 - InstrumentationDocument37 pagesChapter 17 - InstrumentationCandice PeñaNo ratings yet
- R. Angeline Prabha & J.Lavina Mary: Jacsi College of Engg. NazarethDocument17 pagesR. Angeline Prabha & J.Lavina Mary: Jacsi College of Engg. NazarethRose EdwardNo ratings yet
- Shear Wave Velocity: Comparison Between Centrifuge and Triaxial Based MeasurementsDocument6 pagesShear Wave Velocity: Comparison Between Centrifuge and Triaxial Based MeasurementsLuciano JuniorNo ratings yet
- Urea BrochureDocument0 pagesUrea BrochureiosiiosiNo ratings yet
- De Prospectiva PingendiDocument7 pagesDe Prospectiva PingendiDiego Che0% (2)
- Near-Infrared Spectroscopy NIRS-based Digit Skin TDocument5 pagesNear-Infrared Spectroscopy NIRS-based Digit Skin TRussell AngelesNo ratings yet
- Answers & Solutions: JEE (Advanced) - 2019Document40 pagesAnswers & Solutions: JEE (Advanced) - 2019Amogh VaishnavNo ratings yet
- CIV2040S L3 Problems Basic Fluid PropertiesDocument2 pagesCIV2040S L3 Problems Basic Fluid PropertiesMosameem ARNo ratings yet
- Marine CompositesDocument390 pagesMarine Compositesbblagonic93% (14)
- Contoh Dan Jawaban Soal Metode Elemen HinggaDocument16 pagesContoh Dan Jawaban Soal Metode Elemen HinggadhiafahheraNo ratings yet
- (Darryl D. Hol,) Geometric Mechanics Rotating, TR (B-Ok - CC) PDFDocument304 pages(Darryl D. Hol,) Geometric Mechanics Rotating, TR (B-Ok - CC) PDFOceanNo ratings yet
- Gulfmaster Manual PDFDocument15 pagesGulfmaster Manual PDFJoan RosanwoNo ratings yet
- Pre Stressed ConcreteDocument5 pagesPre Stressed Concreteridzwan8789No ratings yet
- Australia Shell Spirax S6 AXME 80W-140 TDSDocument2 pagesAustralia Shell Spirax S6 AXME 80W-140 TDSfdpc1987No ratings yet
- LPO / Low Power ObjectiveDocument2 pagesLPO / Low Power ObjectiveFor AstroNo ratings yet
- ANSYS 10.0 Workbench Tutorial - Description of TutorialsDocument7 pagesANSYS 10.0 Workbench Tutorial - Description of TutorialssangeethsreeniNo ratings yet
- Energy TypesDocument3 pagesEnergy TypesSuki TsangNo ratings yet
- Micrologic Trip CurvesDocument3 pagesMicrologic Trip Curves322399mk7086No ratings yet
- Stats&Prob - WEEK 1Document3 pagesStats&Prob - WEEK 1Ji PaoNo ratings yet
- Financial Mathematics Course FIN 118 Unit Course 0 Number Unit Introduction To The Course Unit SubjectDocument23 pagesFinancial Mathematics Course FIN 118 Unit Course 0 Number Unit Introduction To The Course Unit Subjectayadi_ezer6795No ratings yet
- Pirs509a BeamnrcDocument289 pagesPirs509a BeamnrcskcomhackerNo ratings yet
- 1 s2.0 S0267726121000427 MainDocument14 pages1 s2.0 S0267726121000427 MainMarco Castro MayorNo ratings yet
- Study Guide Velocity and AccelerationDocument2 pagesStudy Guide Velocity and Accelerationapi-259781257100% (1)
- Hydrotest Pressure CalculationDocument26 pagesHydrotest Pressure Calculationrudrakr0% (1)
- Kcet Chemistry 2015Document11 pagesKcet Chemistry 2015BURHAN0% (1)
- H Guru Instrument North India Private LimitedDocument6 pagesH Guru Instrument North India Private LimitedneenuNo ratings yet
- TCRT 1000Document7 pagesTCRT 1000Costel MirzacNo ratings yet